
随着元宇宙概念的兴起,数字人在近一两年频繁地出现在我们的视野中。无论你是否做好准备,数字人似乎都将越来越多地融入到我们的日常生活中。本文将简要介绍数字人的发展历程与技术现状,并对数字人未来发展做一些思考。
(一)什么是数字人?
数字人目前尚无统一的定义。有些定义中,将数字人定义为“虚拟人物”,具备人类的某些特质,而另一些定义中,将数字人定义为纯粹的“计算机程序”。
笔者认为,数字人的落脚点在“人”,若数字人没有了“人”的特征,其与人工智能就没有本质差异了。因此,笔者对数字人的定义如下:数字人是集成了计算机图形、机器视觉、智能语音、自然语言处理等技术并具有人物形象及人物设定的计算机应用程序。此处人物形象并非必须是写实人物,也可以是卡通形象。
(二)数字人发展历程与现状
数字人最初的发展阶段可追溯到上世纪80年代初,公认的第一位数字人名为林明美,其原本是日本动画片《超时空要塞》的女主角。


林明美
本世纪初,电影《指环王》中世界首个虚拟电影角色“咕噜”的诞生标志着数字人进入了成熟的商业化阶段。

咕噜
借助计算机图形学(CG)技术、动作捕捉技术、语音合成技术,数字人已达到了实用水平。但是,由于制作主要依靠人工,费事费力,且相关硬件设备造价高昂,写实级别数字人的应用范围基本仅限于电影与超大型游戏。例如《速度与激情7》中,仅几个保罗·沃克的CG镜头制作费用就高达5000万美元!数字人其实并不是最近才有的东西,早就已经有了较为完整的产业链,只不过由于居高不下的成本,导致数字人并未大规模进入公众视野。
如今,随着人工智能(AI)技术的日趋成熟,数字人的制作过程有效简化,制作成本急剧下降,且数字人的交互能力大幅上升。大量的数字人在这一阶段涌现,令人眼花缭乱:集原美、AYAYI、柳夜熙、翎Ling、A-SOUL、韬斯曼、aespa、华智冰、崔筱盼、希加加,小浦、塞壬、新小浩……每一位数字人都被赋予了不同的人设。这些数字人大多由大型互联网企业创造,制作过程多为传统手工与AI相结合。
(三)数字人关键技术
数字人涉及到的技术非常多,包括人物形象、语音、动画、交互等方面。但在众多的技术中,数字人的形象与动作是现阶研究人员关注度最高的,因为其能非常直观地反映出数字人逼真与否。下面笔者将试图从数字人人物形象、动作与AI结合的角度,梳理涉及的关键技术。
(1)建模。
传统意义上,建模是手工完成的,一个全新的人物模型一般先由策划师提供风格需求,再由原画师画出具体的人物形象,最后由模型师根据原画在Maya、3ds max等建模软件中完成人物的建模。手工建模依然是现阶段使用最广泛的建模方式,绝大多数游戏人物以及非写实数字人都是采用手工建模的方式完成的。手工建模的优点是灵活、精度高,缺点是周期长,成本高。
若对现实世界已有的物体进行建模,则可采用基于扫描的建模技术。基于扫描的建模技术分为静态扫描建模和动态光场重建。静态扫描建模技术又可分为结构光扫描重建和相机阵列扫描重建。动态光场重建主要包含人体动态三维重建和光场成像。基于扫描的建模优点是建模周期短,可以很好地还原真实世界的物体,缺点是无法对真实世界不存在的物体进行建模,且硬件设施成本高。
在传统建模的基础上,使用AI技术可大大提高建模的效率。下面介绍几个典型的应用。
a) 三维可变形人脸模型(3D Morphable models,3DMM)数据集。这是AI辅助建模中的最重要的基础设施之一,几乎所有的AI辅助人脸建模都离不开这个数据集。3DMM是基于大量三维扫描得到的三维人脸数据制作出来的模型,可以有脸型、表情、纹理等多个维度。其核心思想是任意人脸可以在三维空间中进行一一匹配,并且可以由其他许多幅人脸正交基加权线性相加而来。目前该模型开源的数据集有BFM(200人)和LSFM(9663人)。开源数据集主要采集的是外国人的人脸数据,国内有一些科研机构和企业也有亚洲人的3DMM数据集,但都未公开。
3DMM人脸数据库示意图
b) 基于一张或几张图片的人脸建模。通过一张正脸照片,或者多个角度的人脸照片(手机拍摄即可,无需使用专业相机),输入至一个经由3DMM数据集训练好的神经网络,可以快速生成该人的三维人脸模型。该技术较成熟,生成效果较好,前提是3DMM数据集较为完备。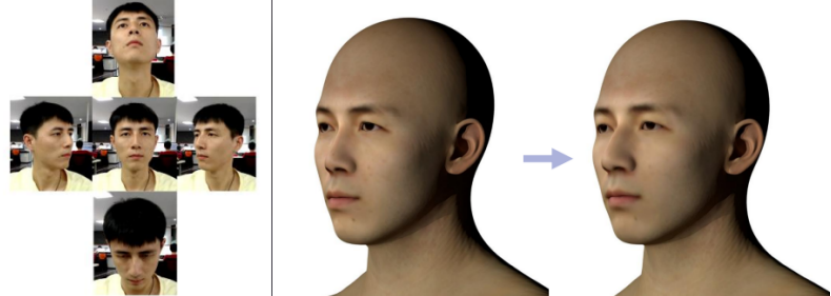
多视角人脸模型重建 (图片来源-东西游戏公众号)
c) 基于照片的全身建模。与b)类似,使用一张全身照,通过训练好的深度神经网络生成全身的3D模型。该技术受制于图片像素,目前在细节上的建模精度较低。

基于照片的全身建模
(2)动作捕捉与驱动。
驱动指数字人的运动,包括做出各种表情以及关节的动作等,在某些情况下,数字人的驱动也称作动画。在早期,数字人的驱动是通过手工绘制关键帧的形式完成的,现如今纯手工的方式已较少使用。
动作捕捉是记录真人动作的技术。现阶段,光学动作捕捉是最主流的方式。光学动作捕捉通过对目标上特定光点的监视和跟踪来完成运动捕捉的任务。一般情况下会在演员身上粘贴能够反射红外光的马克点,通过摄像头对反光马克点的追踪,来对演员的动作进行捕捉。这种方式对动作的捕捉精度高,但对环境要求也高,并且造价高昂。
使用动作捕捉将真人动作迁移至数字人是数字人驱动的主流方式,许多大众熟知的电影,如《金刚》、《指环王》、《复仇者联盟》、《阿凡达》等都是借助动作捕捉技术,将活灵活现的人物展示到荧屏上。
在数字人的驱动方面,不通过动作捕捉迁移,而是借助AI采用智能合成的方式也出现端倪。下面介绍几个典型的AI辅助数字人驱动技术。
a) 单/多目摄像头人脸捕捉。无需通过专业的动作捕捉设备,只需通过单个多少数几个摄像头的拍摄,利用AI技术,实时获取脸部的关键点,将这些关键点与拍摄者解耦,并映射至已经建模完毕的数字人上,便可实时驱动数字人脸部表情的运动。

3D模仿秀(图片来源:之江实验室科艺融合中心)
b) 单/多视角摄像头身体动作捕捉。这是网易制作的视频,用央视的转播画面进行AI动作捕捉,并映射至“哈利波特”数字人上。当时很快就冲上了微博热搜。如果按传统制作方式,这种营销策划案是不太可能实现的,因为整套下来需要至少六位数的开销和一个多月制作周期。但是用这套AI方案,成本就可以忽略不计。

单/多视角摄像头身体动作捕捉 (图片来源-东西游戏公众号)
c) 基于文本的手语生成。将AR眼镜中画面的文字提取出来,并通过数字人实时展示手语翻译。此技术为聋哑人(绝大多数的聋哑人只能理解手语,难以理解文字)极大地提供了便利。

基于文本的手语生成 (图片来源:之江实验室科艺融合中心)
(四)数字人标准化现状
ITU-T SG16 Q5发布了2项数字人国际标准,分别是 “F.748.15: Framework and metrics for digital human application system”和“F.748.14: Requirements and evaluation methods of non-interactive 2D real-person digital human application system”。ITU-T F.748.15聚焦于数字人应用系统,首次明确了数字人(“digital human”)的定互处理、多模态输入、多模态输出等维度规范了相应的技术评估指标。ITU-T F748.14面向非交互式2D真人形象类数字人应用系统,定义了2D数字人、2D真人形象类数字人、非交互式数字人的相关概念,并结合ITU-T F.748.15,从形象、语音、动作、多模态输入、多模态输出等维度提出了相应的指标要求以及具体的评估方法。此外,还有一项标准“Requirements and evaluation methods of digital human platform”获立项,暂无相关国家标准。目前涉及数字人的标准相对较少,随着数字人行业不断发展与完善,会更多的标准规范陆续出台。
(五)数字人的应用场景
数字人的应用场景可分为两类:服务型虚拟数字人和身份型虚拟数字人。
服务型数字人的特点是替代真人服务从而达到降本增效的效果,包括虚拟客服、虚拟导游、虚拟主播、虚拟讲师、虚拟主持、虚拟心理医生、虚拟陪伴等。
身份型虚拟数字人的特点是拥有娱乐与社交的身份,它们的出现满足了新兴需求,包括虚拟歌姬、虚拟KOL、虚拟偶像、虚拟艺术家、数字化身等。
(六)关于数字人未来的思考
笔者认为,一项技术能否得以长期发展无外乎两种情况:第一种情况,该技术满足了新的需求;第二种情况,该技术的存在使得社会的运转成本下降,运转效率提高。
从这个角度来看,服务型数字人的发展路径较为明确,只要技术过关,就可以在一定程度上代替人工,从而提高社会的运转效率。事实上,已经有许多公司通过服务型数字人节约了不少成本。
然而,娱乐型数字人的发展前景还有待观察,虽然娱乐型数字人可以防范真人存在的道德与法律风险,但人与机器仍然存在着较大的隔阂,真人与数字人给人类带来的主观感觉是有明显差异的。娱乐型数字人究竟是否是一个新的需求,或者只是昙花一现,让我们期待市场给出的最终答案。
作者:许知涯。之江实验室智能科技标准化研究中心高级研究专员,现主要研究方向为数字人标准化
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。