
实时语音翻译是一项复杂的挑战,需要无缝集成语音识别、机器翻译和文本转语音合成。传统的级联方法通常会引入复合错误,无法保留说话者身份,并且处理速度缓慢,因此不太适合现场翻译等实时应用。此外,现有的同声传译模型难以平衡准确性和延迟,依赖于难以扩展的复杂推理机制。一个重大障碍仍然是缺乏大规模、对齐良好的语音数据集,这限制了训练能够以最小延迟生成上下文准确且自然的翻译的模型的能力。
Kyutai 开发了Hibiki,这是一个拥有 27 亿个参数的解码器专用模型,专为实时语音转语音翻译 (S2ST) 和语音转文本 (S2TT) 翻译而设计。Hibiki 以12.5Hz 帧速率和 2.2kbps 比特率运行,目前支持法语到英语翻译,并旨在在翻译输出中保留语音特征。精简版Hibiki-M(17 亿个参数)针对智能手机上的实时性能进行了优化,使其更适合在设备上进行翻译。
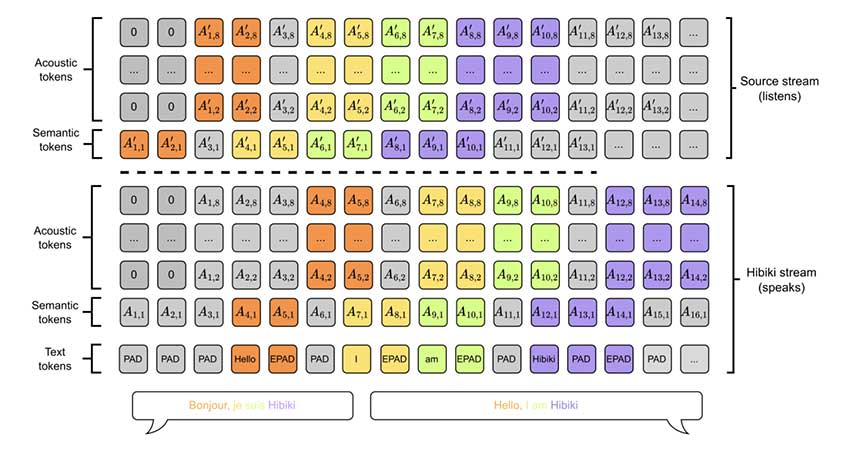
技术方法和优势
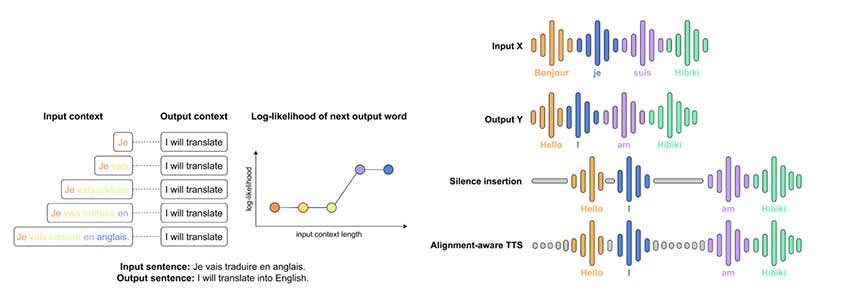
Hibiki 的仅解码器架构能够使用多流语言模型同时进行语音处理,该模型可以预测文本和音频标记。它采用神经音频编解码器 (Mimi)来压缩音频,同时保持保真度,确保高效的翻译生成。其设计的一个关键方面是上下文对齐,这种方法利用文本翻译模型的困惑度来确定生成语音的最佳时间,使 Hibiki 能够动态调整翻译延迟,同时保持一致性。此外,Hibiki 支持批量推理,可在 H100 GPU 上并行处理多达320 个序列,使其适用于大规模应用。该模型基于700 万小时的英语音频、45 万小时的法语和 4 万小时的合成并行数据进行训练,这有助于提高其在各种语音模式下的稳健性。
绩效与评估
Hibiki 在翻译质量和说话人保真度方面表现优异。它的ASR-BLEU 得分为 30.5,超过了包括离线模型在内的现有基线。人工评估将其自然度评为 3.73/5,接近专业人工翻译的 4.12/5 分数。该模型在说话人相似度方面也表现良好,相似度得分为0.52,而Seamless 为 0.43 。与Seamless 和 StreamSpeech相比,Hibiki 始终提供更高的翻译质量和更好的语音传输,同时保持了具有竞争力的延迟。经过提炼的Hibiki-M变体虽然在说话人相似度方面略低,但对于实时设备使用仍然有效。
结论
Hibiki 提供了一种实时语音翻译的实用方法,它集成了上下文对齐、高效压缩和实时推理,以提高翻译质量,同时保留自然语音特征。通过在宽松的 CC-BY 许可下提供开源版本,Hibiki 有可能为多语言通信的进步做出重大贡献。
更多信息请查看:https://github.com/kyutai-labs/hibiki?tab=readme-ov-file
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/55657.html
