
多模态大型语言模型 (MLLM) 正在快速发展,使机器能够同时解释和推理文本和视觉数据。这些模型在图像分析、视觉问答和多模态推理方面具有变革性的应用。通过弥合视觉与语言之间的差距,它们在提高人工智能整体理解和与世界互动的能力方面发挥着至关重要的作用。
尽管前景光明,但这些系统仍需要克服重大挑战。一个核心限制是依赖自然语言监督进行训练,这通常会导致视觉表现质量不佳。虽然数据集大小和计算复杂性的增加带来了适度的改进,但它们需要更有针对性的优化这些模型中的视觉理解,以确保它们在基于视觉的任务中实现所需的性能。当前的方法经常需要在计算效率和改进的性能之间取得平衡。
有的 MLLM 训练技术通常涉及使用视觉编码器从图像中提取特征,并将它们与自然语言数据一起输入语言模型。一些方法采用多个视觉编码器或交叉注意机制来增强理解。然而,这些方法的代价是数据和计算要求明显更高,限制了它们的可扩展性和实用性。这种低效率凸显了对 MLLM 进行视觉理解的更有效优化方法的需求。
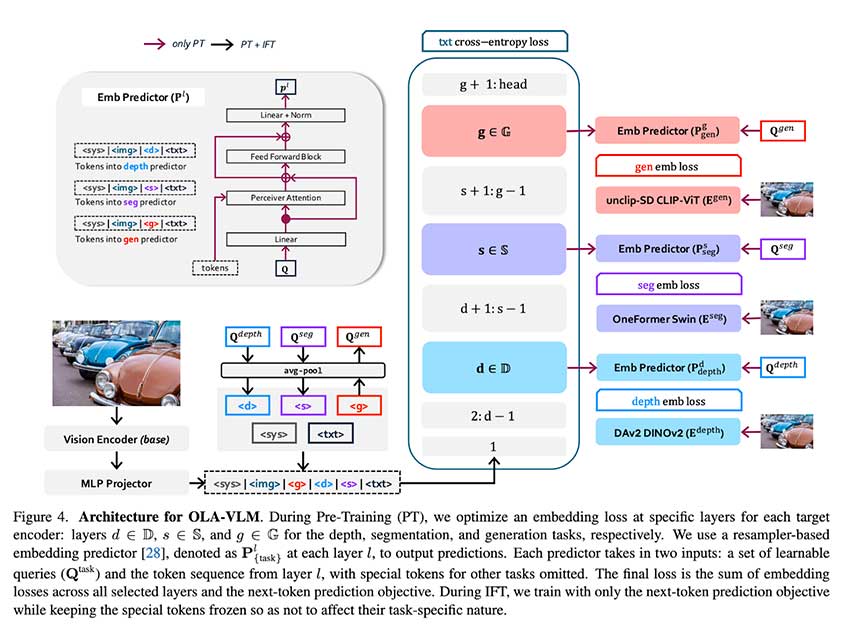

佐治亚理工学院 SHI 实验室和微软研究院的研究人员推出了一种名为 OLA-VLM 的新方法来应对这些挑战。该方法旨在通过在预训练期间将辅助视觉信息提炼到 MLLM 的隐藏层中来改进 MLLM。OLA-VLM 不会增加视觉编码器的复杂性,而是利用嵌入优化来增强视觉和文本数据的对齐。将这种优化引入语言模型的中间层可确保更好的视觉推理,而无需在推理过程中增加额外的计算开销。
OLA-VLM 背后的技术涉及嵌入损失函数,以优化专用视觉编码器的表示。这些编码器经过图像分割、深度估计和图像生成任务的训练。使用预测嵌入优化技术将提取的特征映射到语言模型的特定层。此外,特殊的任务特定标记被附加到输入序列中,允许模型无缝地整合辅助视觉信息。这种设计确保视觉特征有效地集成到 MLLM 的表示中,而不会破坏下一个标记预测的主要训练目标。结果是一个学习更强大和以视觉为中心的表示的模型。
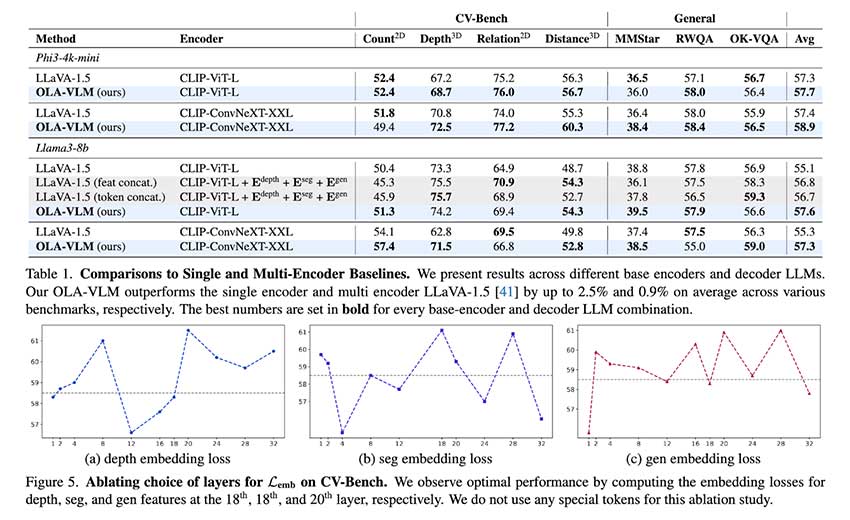
OLA-VLM 的性能在各种基准测试中经过了严格测试,与现有的单编码器和多编码器模型相比,其性能有了显著的提升。在以视觉为中心的基准测试套件 CV-Bench 上,OLA-VLM 在深度估计任务中的表现比 LLaVA-1.5 基线高出 8.7%,准确率达到 77.8%。对于分割任务,其平均交并比 (mIoU) 得分为 45.4%,比基线的 39.3% 有了显著提高。该模型还在 2D 和 3D 视觉任务中表现出了持续的提升,在距离和关系推理等基准测试中平均提升了 2.5%。OLA-VLM 在推理过程中仅使用单个视觉编码器就实现了这些结果,这使其效率远高于多编码器系统。
为了进一步验证其有效性,研究人员分析了 OLA-VLM 学习到的表示。探索性实验表明,该模型在其中间层实现了卓越的视觉特征对齐。这种对齐显著提高了模型在各种任务中的下游性能。例如,研究人员指出,在训练期间集成特殊的任务特定标记有助于更好地优化深度、分割和图像生成任务的特征。结果强调了预测嵌入优化方法的效率,证明了它能够平衡高质量的视觉理解和计算效率。

OLA-VLM 通过在预训练期间专注于嵌入优化,为将视觉信息集成到 MLLM 中建立了新标准。这项研究通过引入以视觉为中心的视角来提高视觉表征的质量,从而解决了当前训练方法中的差距。与现有方法相比,所提出的方法提高了视觉语言任务的性能,并且以更少的计算资源实现了这一目标。OLA-VLM 举例说明了在预训练期间进行有针对性的优化如何显著提高多模态模型的性能。
总之,SHI 实验室和微软研究院开展的研究突出了多模态 AI 的突破性进展。通过优化 MLLM 中的视觉表示,OLA-VLM 弥补了性能和效率方面的关键差距。该方法展示了嵌入优化如何有效解决视觉语言对齐方面的挑战,为未来更强大、更可扩展的多模态系统铺平了道路。
更多详细信息,请查看论文GitHub页面:https://github.com/SHI-Labs/OLA-VLM?tab=readme-ov-file
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/54693.html