
Google 近期发布了最新开放模型 Gemma 2,目前与同等规模的开放模型相比,取得了明显的优势,同时在安全可控性上得到了显著的增强。
Gemma 2 提供了 9B 以及 27B 两种参数规模的选择,同时分别提供了预训练模型 (Gemma 2-9B/Gemma 2-27B) 与指令微调模型 (Gemma 2-9B-it/Gemma 2-27B-it),优异的性能表现原自 Gemma 2 在训练阶段的各项技术创新。
Gemma 2 支持 8192 tokens 的上下文长度,同时使用了旋转位置编码 (RoPE)。Gemma 2-9B 在 Google TPUv4 上训练而成,Gemma 2-27B 在 Google TPUv5p 上训练而成。
作为开放模型,用户目前可以在 Hugging Face 以及 Kaggle 上免费获取模型权重。
- 用户可以选择先把模型下载到本地或者云端共享存储,然后将模型部署至推理框架上。
- 也可以选择在部署模型的过程中从 Hugging Face 上下载模型。
我们通常建议使用第一种方案,这种方式可以避免每次部署模型都从公网下载,提升模型加载以及扩展效率。
Gemma 2 生态广泛,支持通过多种主流框架进行模型的部署,这些框架包括但不限于:
● Hugging Face Transformers
● Keras NLP
● Pytorch
● Gemma C++
● GGUF
● Tensorflow Lite
● TensorRT-LLM
● MaxText
● Pax
● Flax
● vLLM
● oLLama
此外,用户也可以根据实际需求选择灵活的方式部署 Gemma 2 模型,这些部署方案通常包括:
- 本地或 colab 部署: 个人用途,体验模型功能或者构建个人助理。
- GKE 或第三方 Kubernetes 平台部署: 生产用途,用于将模型和生产业务系统集成,同时充分借助 Kubernetes 平台资源调度和扩展的优势。
- Vertex AI 部署: 生产用途,用于将模型和生产业务系统集成,同时借助 Google AI PaaS 平台全托管的优势。
Google Cloud 为用户提供了方便的操作服务,用户可以在 Vertex AI Model Garden 上将 Gemma 2 一键部署 GKE 集群或者 Vertex AI endpoint 上,并通过可视化界面对性能和日志进行实时查看,同时也根据请求的流量对推理实例动态的扩缩容。
Gemma 2 支持模型的 fine-tuning,用户可以利用私有数据或者领域内的特定数据对模型进行 fine-tune,对齐领域内的风格和标准、从而更好地支撑业务场景。
大模型的 fine-tuning 通常包括以下几种方式:
● Full Parameter fine-tuning
● Lora fine-tuning
● QLora fine-tuning
其中 Full Parameter fine-tuning 需要对模型的全部参数进行重新训练,Lora fine-tuning 通过训练少量的低秩矩阵参数提升模型训练的效率,QLora fine-tuning 在 Lora 的基础上对模型精度进行了 4bit 或者 8bit 的量化处理来近一步优化模型的存储占用。
Lora 和 QLora 在一些特定的场景下可以用很低的成本取得非常好的效果,但是对于一些复杂的场景、或者领域数据更加丰富的场景,还是需要通过全量参数的方式进行继续训练。
本次演示我们会通过全量参数训练的方式对模型进行 fine-tuning,同时结合 Deepspeed 框架来实现模型的分布式训练。
Fine-Tune 演示
a. 微调数据集
本次模型微调,我们会对 Gemma 2-27B 的预训练基础模型利用对话数据进行微调。Gemma 2-27B 是预训练模型,不具备对话能力,通过对比 fine-tune 前后的模型,可以观察模型训练的效果。
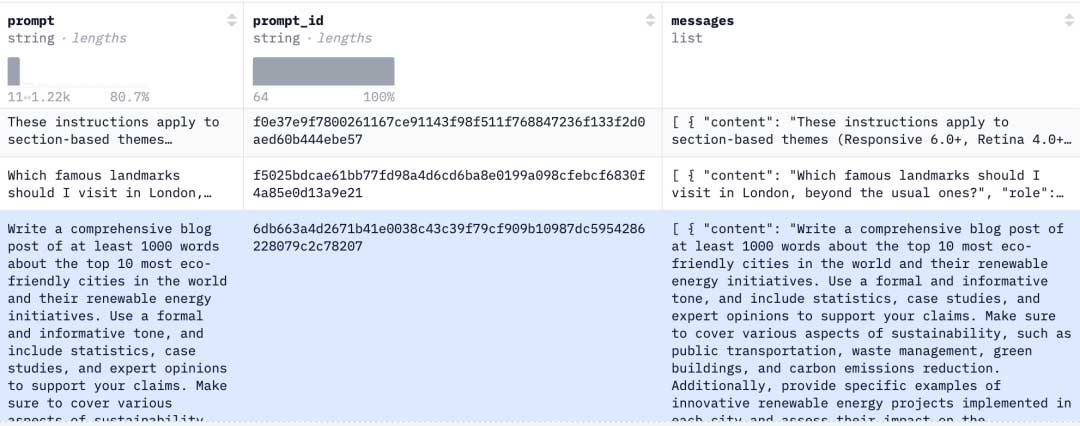
训练数据集使用了 Hugging Face 上的开放数据集 “smangrul/ultrachat-10k-chatml”,它一共由 10k 行训练数据集以及 2k 行测试数据集组成。数据格式如图所示,每一条数据的 message 列都由一个多轮对话组成。
b. 训练环境
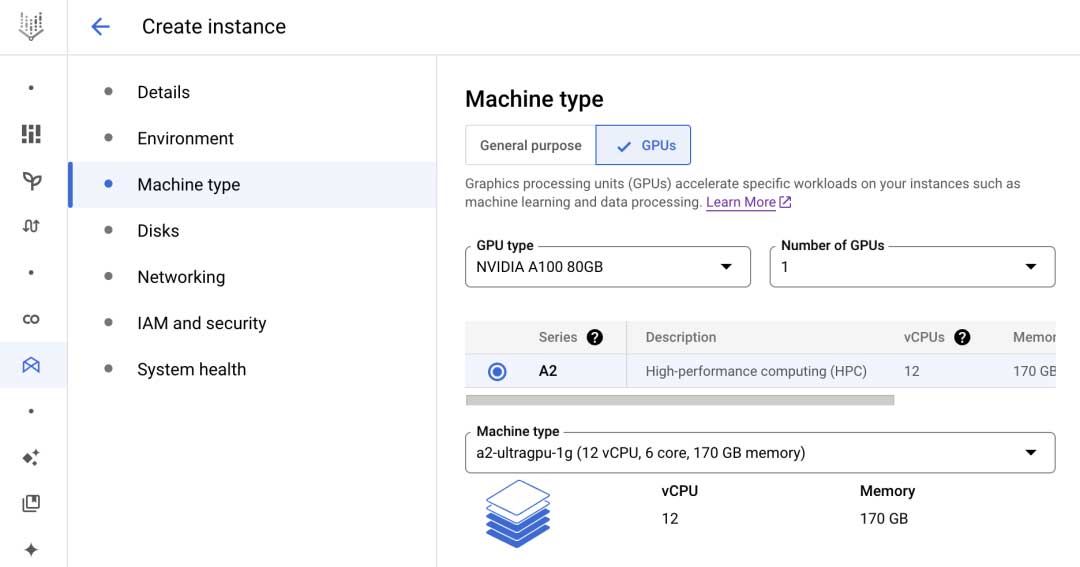
创建 Vertex AI Workbench,Vertex AI Workbench 是由 Google Cloud 托管的企业级 Jupyter Notebook 服务,它支持多种硬件加速设备,同时预制了依赖包,用户完成 Workbench 实例的创建后可以通过浏览器访问 Jupyter Notebook 界面,之后快速开启模型体验之旅。
c. 微调步骤
1. 进入 Vertex AI Workbench 界面,创建新文件,运行下面代码,加载 Gemma 2-27B 基础模型,并测试模型针对 prompt 的输出,此步骤目的是为和训练后的输出进行训练效果对比。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
#加载模型
model_id = "google/gemma-2-27b"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
)
#准备prompt(对话格式)
prompt = """### Human: I can't cancel the subscription to your corporate newsletter### Assistant: """
#将prompt转换成token id并输入model生成内容
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=100)
#解码token id,打印输出
print(tokenizer.decode(outputs[0]))
可以看到模型对话风格生硬,自然对话的效果差。
2. 克隆 peft github 代码,并切换至模型训练脚本界面。
!git clone https://github.com/huggingface/peft.git
!cd examples/sft/Gemma 2 与开源的 Hugging Face 的 Transformer library 完全兼容,因此用于训练其它模型的脚本在更改模型名称后,便可以开始训练 Gemma 模型。但是需要注意的是,不同模型多轮对话支持的特殊 token 可能不一样,因此与之相对应的 tokenzier 里面 chat 模板需要提前进行处理。本次我们使用 chatml 格式的模板,只需要在示例脚本上设置对应参数,代码对会自动对 tokenizer 进行处理。
3. 配置 Hugging Face (用于模型下载) 以及 wandb (用于可视化展示训练监控指标) 的 token 环境变量。
!echo 'export HUGGINGFACE_TOKEN=YOUR_HF_API_TOKEN' >> ~/.bashrc
!echo 'export WANDB_API_KEY=YOUR_WANDB_API_KEY' >> ~/.bashrc
!source ~/.bashrc4. 安装依赖包
!pip install accelerate==0.32.1
!pip install deepspeed==0.14.4
!pip install transformers==4.42.4
!pip install peft==0.11.1
!pip install trl==0.9.6
!pip install bitsandbytes==0.43.1
!pip install wandb==0.17.45. 启动训练任务,命令会通过 accelerate 启动一个单机八卡的训练任务,分布式框架由 deepspeed 实现。训练任务由 Hugging Face SFTTrainer 实现,它会下载 Hugging Face上的 “smangrul/ultrachat-10k-chatml” 数据集,并读取 content 字段。
训练任务采用 bf16 混合精度,由于全量参数微调占用显存很大,因此每个 GPU device 的 batch size 设置为 1 (激活值非常消耗内存,若大于 1 会导致 OOM),通过将梯度累加设置将单个设备的有效 batch size 提升为 4,同时开启 gradient_checkpointing 节省激活值对内存的占用。
任务在训练过程中,指标数据会实时传送至 wandb,整个训练周期为 1 个 epoch,训练任务结束后,模型会自动存放至 gemma2-27b-sft-deepspeed 路径下。
# 任务训练任务启动命令
!accelerate launch --config_file "configs/deepspeed_config.yaml" train.py \
--seed 100 \
--model_name_or_path "google/gemma-2-27b" \
--dataset_name "smangrul/ultrachat-10k-chatml" \
--chat_template_format "chatml" \
--add_special_tokens False \
--append_concat_token False \
--splits "train,test" \
--max_seq_len 2048 \
--num_train_epochs 1 \
--logging_steps 5 \
--log_level "info" \
--logging_strategy "steps" \
--evaluation_strategy "epoch" \
--save_strategy "epoch" \
--bf16 True \
--learning_rate 1e-4 \
--lr_scheduler_type "cosine" \
--weight_decay 1e-4 \
--warmup_ratio 0.0 \
--max_grad_norm 1.0 \
--output_dir "gemma2-27b-sft-deepspeed" \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 4 \
--gradient_checkpointing True \
--use_reentrant False \
--dataset_text_field "content"# Deespeed配置脚本
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
deepspeed_multinode_launcher: standard
gradient_accumulation_steps: 4
offload_optimizer_device: none
offload_param_device: none
zero3_init_flag: true
zero3_save_16bit_model: true
zero_stage: 3
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: bf16
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
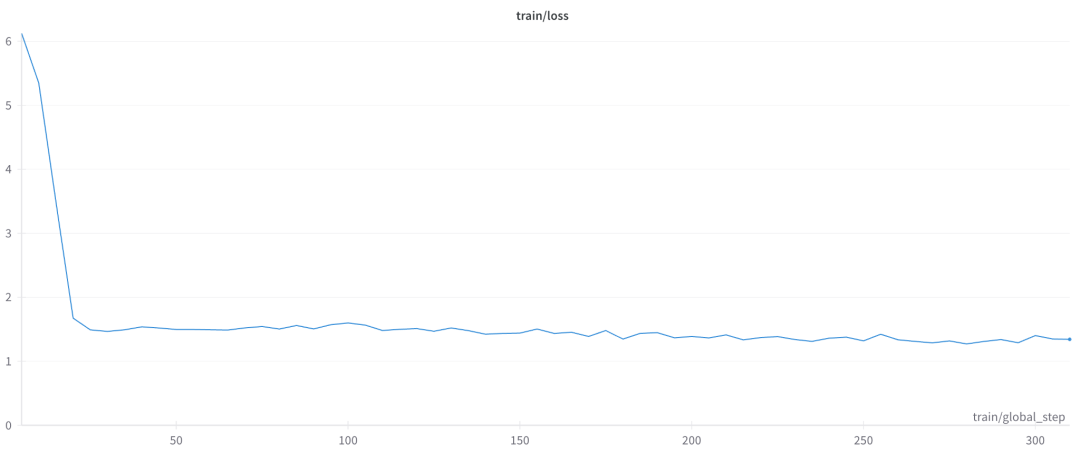
use_cpu: false6. 观察任务训练指标,等待任务训练结束。本次训练,测试数据由 10k 行组成,由于我们采用了 8 张卡训练,单个卡的 batch size 设置为 1,梯度累积设置为 4,因此 global batch size 为 1*4*8=32,单个 epoch 训练 step 数量为: 10000/32= 312 steps。从损失值图表中可以看到,当训练任务至 20 步左右时,损失值开始快速下降,之后平稳收敛直到训练任务结束。

7. 重新加载训练后的模型,并验证训练效果。从内容输出中可以看到,模型很好地学习到了数据集生成对话的形式和总结风格,能够以更加流畅、自然的方式进行对话。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "./gemma2-27b-sft-deepspeed"
dtype = torch.bfloat16
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="cuda",
torch_dtype=dtype,
)
prompt = """### Human: I can't cancel the subscription to your corporate newsletter### Assistant: """
inputs = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
outputs = model.generate(input_ids=inputs.to(model.device), max_new_tokens=100)
print(tokenizer.decode(outputs[0]))
以上介绍了 Gemma-2-27B fine-tune 的一个简单的实验演示,通过实验可以看出 Gemma 2 与主流的训练框架完全兼容,对于已经了解如何 fine-tune 其它模型的开发人员可以快速切换至 Gemma 2 完成模型训练。
Google Cloud 还提供了更多高级的解决方案,可以帮助用户通过 Vertex AI Pipeline 或者 Ray On GKE 等方式大规模、自动化地训练开放模型, 感兴趣的读者可以联系 Google Cloud 的工作人员获得更近一步的了解。
作者 / 曹治政,Google Cloud 解决方案架构师
来源 / 谷歌云服务
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
