

随着生成式人工智能的兴起,近年来涌现了大量文生图、文生视频模型。此类算法的主要目标是根据用户要求(prompt)生成视觉内容。因此,评价人类对AIGC的主观偏好逐渐受到了广泛重视,具有重要的研究价值。然而现有的图像/视频质量评价(I/VQA)方法与人类主观感知质量的相关性不强,且通常无法表征生成内容与用户要求的契合度,因此需要提出新的评价指标来预测AIGC的质量,由此促进多模态生成领域的发展。
在UGC(用户生成内容)VQA的基础上,AIGC(人工智能生成内容)VQA面临两大独特挑战:首先,生成的伪影与真实世界中的失真并不一致;其次,生成帧与文本描述的对齐问题亟待解决。国际竞赛NTIRE 2024组织的 AIGC 视频质量评价挑战赛包含了10,000 个视频数据,涵盖了主流的8种文生视频模型,极具挑战性。
由于在AIGC VQA中,有三个关键因素至关重要:
1. 技术质量:这是与失真感知密切相关的核心因素。高质量的技术标准能更准确地识别和处理各种失真现象。
2. 美学质量:从美学角度捕捉人类感知的艺术因素,提升内容的视觉享受和艺术表现力。
3. 视频-文本对齐:通过捕捉语义不匹配,确保视频内容与文本描述的高度一致,使观众获得更加完整和流畅的观感体验。
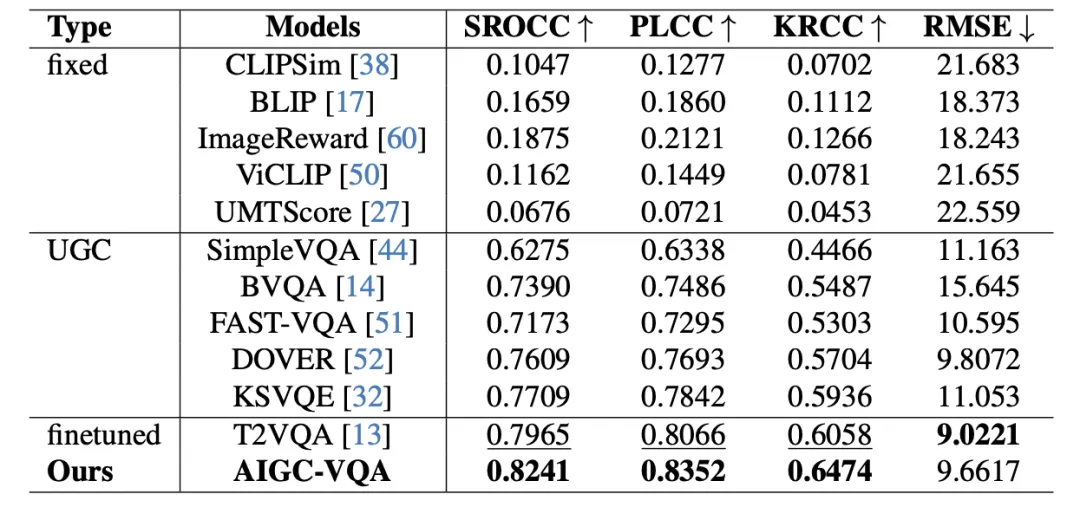
针对这三个因素,中科大IMCL提出一个评价范围更全面的AIGC VQA指标。其中包含三个功能分支,用于捕捉人工智能生成内容(AIGC)视频中的技术、美学和视频-文本对齐方面的合作。并引入空间-时间适配器,以利用大规模图像-文本模型的预训练先验,并实现对视频时空特性的知识迁移。最后提出一种分而治之的训练策略,用于在多个分支上进行渐进式合作。
截至目前,比赛所对应的CVPR workshop已经举办完毕,比赛结果也已公布。团队取得了第一名的好成绩,并且在性能上较其他参赛者有不错的领先。这也验证了团队提出方案的有效性,为AIGC视频质量评价的发展贡献了一份力量。
【内容提供】陆亦婷
【单位】IMCL (Intelligent Media Computing Lab, 中国科学技术大学智能媒体计算实验室)
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
