
Mozilla Ocho 是浏览器公司的创新和实验小组,其有趣的创新之一是 Llamafile,这是一种从单个文件分发和运行人工智能大型语言模型(LLM)的简便方法。5月9日晚上发布的 Llamafile 0.8.2 是最新版本,更新了 Llama.cpp,最令人兴奋的是对 AVX2 性能进行了优化。
Llamafile 的目标是让用户和开发人员更容易获得人工智能 LLM,它支持从单个文件精简部署大型语言模型,这些模型既能在 CPU 和 GPU 上执行,也能跨平台运行。Llamafile 已经支持利用 AVX/AVX2 实现更快的性能,并支持 AVX-512 以实现更快的速度。在 Llamafile 0.8.2 中,又增加了 AVX2 优化功能。
Llamafile 0.8.2 发布说明中提到:
“此版本为 K-quants 和 IQ4_XS 引入了更快的 AVX2 提示处理。这是由 @ikawrakow 贡献给 llamafile 的,他在去年发明了 K 量子:gerganov/llama.cpp@99009e7。在之前的版本中,我们推荐使用传统的 Q4_0 量子,因为它最简单、最直观,可以与最近的 matmul 优化一起使用。多亏了 Iwan Kawrakow 的努力,现在(在现代 x86 系统上)最好的量子(如 Q5_K_M)将以最快的速度运行”。
在过去几年中,英特尔和 AMD 处理器广泛支持高级矢量扩展 2:在过去十年中,大多数英特尔 CPU 从 Haswell 开始支持高级矢量扩展 2,而 AMD 方面则从 Excavator CPU 开始支持高级矢量扩展 2。
拉取请求指出,在更快的 AVX2 提示处理方面取得了一些令人振奋的成果。据报告,各种计算器的速度提高了 1.4~2.3 倍。
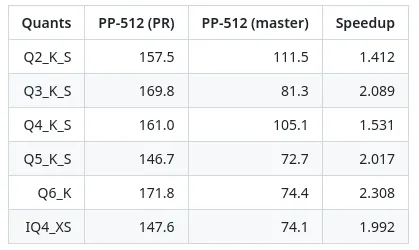
“这是 @ikawrakow 做出的了不起的改变。我很高兴看到最好的量化格式现在能以最快的速度运行。在 x86-64 机器上,我一直看到提示处理的速度提高了 1.2-2.0 倍。你们甚至成功地使令牌生成速度更快(我发现这要困难得多),在某些情况下甚至提高了 1.33 倍!”
对于 Llamafile 0.8.2 而言,这些针对提示处理的 AVX2 优化已经足够令人兴奋了。不过,0.8.2 版还带来了内存错误修复、文本生成的轻微性能优化、本周的 Llama.cpp 代码更新以及各种新标志。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/48073.html
