
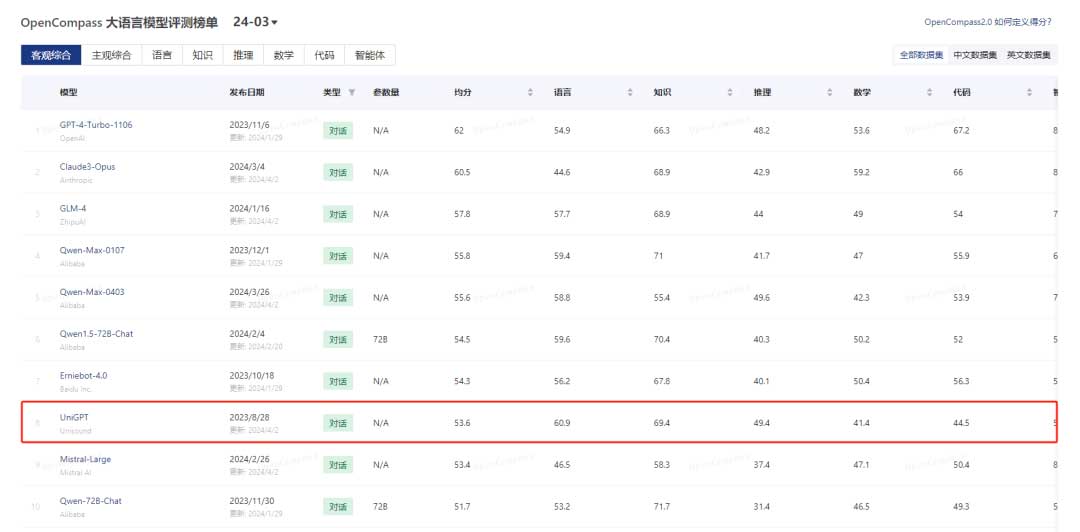
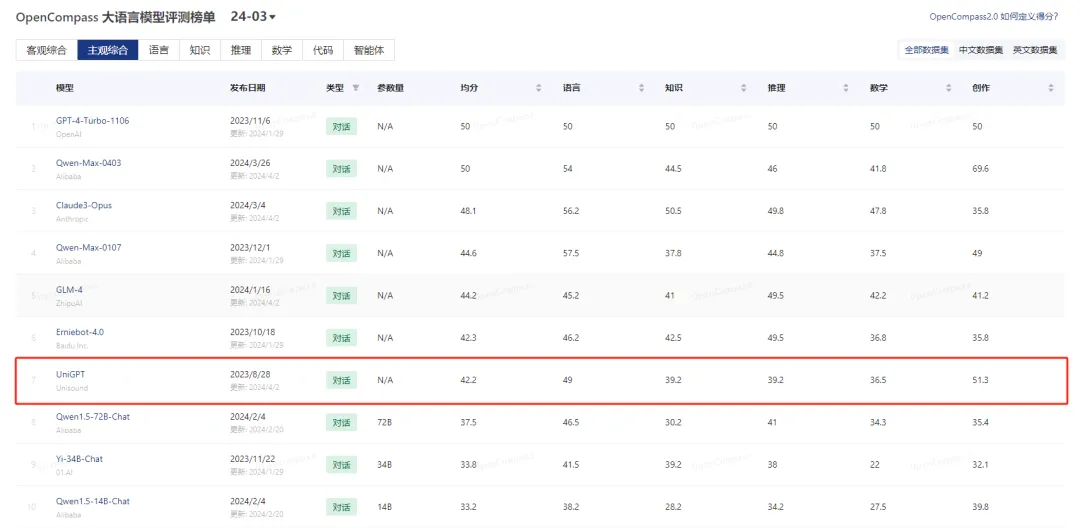
近日,山海大模型完成新一轮迭代升级,并在最新的OpenCompass大模型评测中取得综合性中英文双语客观评测得分53.6、综合性中文主观评测得分42.2的优异成绩,在参与测评的全球大模型厂商中排名第六。评测结果显示,其在中英文双语客观评测中的语言、知识、推理能力,在综合性中文主观评测中的创作能力已超越GPT-4。
作为上海人工智能实验室开源的大模型评测体系,OpenCompass致力于探索最先进的语言与视觉模型,为工业界和研究社区提供全面、客观、中立的评测参考,从而根据不同能力维度的评测分数指导大模型的优化与进步。
OpenCompass 月度榜单从基础能力和综合能力的设计出发,构造了一套高质量的中英文双语评测基准,涵盖语言与理解、常识与逻辑推理、数学计算与应用、多编程语言代码能力、智能体、创作与对话六个方面二十余项细分任务,力图对近期的主流开源模型和商业 API 模型进行全面评测分析。
此次榜单囊括了国内外 40 个大语言模型,评测数据集采用中英文闭源数据集,包括综合性中文主观评测和综合性中英文双语客观评测。云知声山海大模型综合性中英文双语客观评测得分53.6,综合性中文主观评测得分42.2,排名国产大模型厂商第四、全球大模型厂商第六。从各项数据看,其在语言、知识、推理、创作等方面表现优异,显现出强劲的综合实力。
而山海大模型之所以能够在众多大模型中脱颖而出,得益于其在技术上的一系列创新和优化——在本次大模型升级中,云知声引入了自我演进偏好学习技术,使得大模型能够通过自我对弈微调(SPIN)实现自我提升。在高质量数据生成方面,云知声结合RLHF和RLAIF方法,生成大量偏好数据,并采用k-Center Greedy算法确保数据的多样性和覆盖度。此外,云知声还建立了一个全面的自动化评测体系,以此实现对模型效果的快速评测,进而支持大模型的迭代和优化。
自2023年5月发布以来,山海大模型始终保持高速迭代,其在C-Eval全球大模型综合性评测、CCKS 2023医疗大模型评测等权威赛事上屡获佳绩,展现出全面的通用能力和卓越的专业能力,成功跻身大模型第一梯队。此次评测,是山海大模型出色实力的又一次印证,也将鞭策其继续加速迭代,持续引领大模型研发与落地。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。





