
NVIDIA® 与谷歌携手推出 Gemma,这是一套源自 Gemini 技术的优化开放模型。Gemma 由 TensorRT-LLM 提供支持,具有高吞吐量和尖端性能。它兼容所有 NVIDIA 人工智能平台,从数据中心到本地个人电脑均可访问。
Gemma 2B 和 Gemma 7B 模型由 Google DeepMind 开发,以效率为优先考虑。通过 TensorRT-LLM 加速,Gemma 可确保无缝部署和优化。TensorRT-LLM 简化的 Python API 简化了量化和内核压缩,增强了 Python 开发人员的定制选项。
Gemma 模型的词汇量为 256K,支持高达 8K 的上下文长度,因此优先考虑安全性。广泛的数据整理和 PII 过滤确保了负责任的人工智能实践。Gemma 对超过六万亿个令牌进行了训练,使开发人员能够自信地构建和部署高级人工智能应用。

使用 TensorRT-LLM 加速 Gemma 模型
TensorRT-LLM 在提高 Gemma 模型速度方面发挥着关键作用。凭借一系列优化和内核,TensorRT-LLM 显着提高了推理吞吐量和延迟。值得注意的是,三个不同的功能——FP8、XQA 和 INT4 激活感知权重量化 (INT4 AWQ)——有助于提高 Gemma 的性能。
FP8 增强:
FP8 代表了深度学习应用的自然演变,超越了现代处理器中常见的 16 位格式。它有助于提高矩阵乘法和内存传输的吞吐量,而不会影响准确性。FP8 对小批量和大批量都有好处,特别是在内存带宽有限的模型中。
KV 缓存的 FP8 量化:
TensorRT-LLM 为 KV 缓存引入了 FP8 量化,解决了大批量或长上下文长度带来的独特挑战。此优化使运行批量大小增大 2-3 倍,从而提高性能。
XQA 内核:
XQA 内核支持组查询注意力和多查询注意力,在生成阶段和波束搜索期间提供优化。NVIDIA GPU 优化了数据加载和转换时间,确保在相同的延迟预算内提高吞吐量。
INT4 AWQ:
INT4 AWQ 通过小批量工作负载提供卓越的性能,减少网络内存占用,并显着增强内存带宽有限的应用程序的性能。它利用低位仅权重量化方法来最小化量化误差并保护显着权重。
使用 TensorRT-LLM 实现实时性能
TensorRT-LLM 与 NVIDIA H200 Tensor Core GPU 相结合,在 Gemma 2B 和 Gemma 7B 模型上展示了卓越的实时性能。单个 H200 GPU 在 Gemma 2B 型号上每秒可实现超过 79,000 个令牌,在较大的 Gemma 7B 型号上可实现每秒近 19,000 个令牌。
使用 TensorRT-LLM 实现可扩展性
仅在一个 H200 GPU 上部署带有 TensorRT-LLM 的 Gemma 2B 模型即可为超过 3,000 个并发用户提供服务,并且所有用户都具有实时延迟。这种可扩展性强调了 TensorRT-LLM 在提供高性能AI 解决方案方面的效率和有效性。
开始使用 Gemma
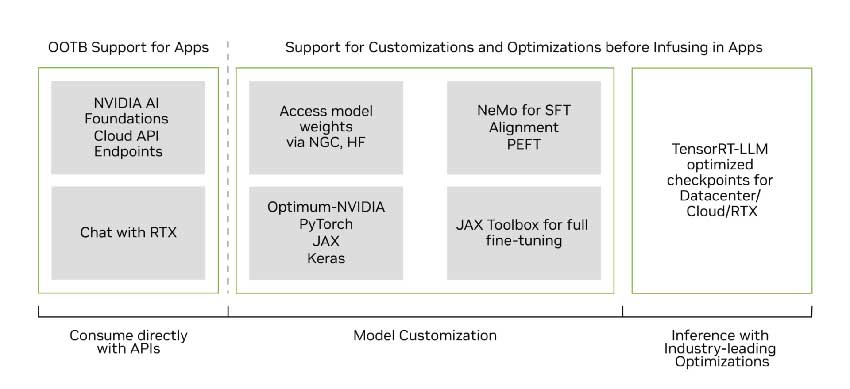
直接通过 NVIDIA AI 游乐场上的浏览器体验 Gemma。很快,您还可以在 NVIDIA Chat with RTX 演示应用程序上试用 Gemma。
NVIDIA 优化的旅程
探索针对 Gemma 小语言模型的 NVIDIA 优化支持。在 NGC 上找到几个 TensorRT-LLM 优化的 Gemma-2B 和 Gemma-7B 模型检查点。其中包括适合在 NVIDIA GPU 上运行的预训练和指令调整版本,包括消费级 RTX 系统。
优化的 FP8 量化版本
即将推出,体验 Hugging Face 上 Optimum-NVIDIA 库中模型的 TensorRT-LLM 优化 FP8 量化版本。只需一行代码即可集成快速 LLM 推理。
使用 NVIDIA NeMo 框架进行部署
开发人员可以使用 NVIDIA NeMo 框架在生产环境中自定义和部署 Gemma。NeMo 支持流行的定制技术,例如使用 LoRA 和 RLHF 进行监督微调和参数高效微调。它还为训练提供 3D 并行性。查看笔记本以开始使用 Gemma 和 NeMo 进行编码。
关于 Gemma 和 TensorRT-LLM 的常见问题
1. Gemma 是什么?它与以前的型号有何不同?
Gemma 是 Google 创建的新优化的开放模型系列,利用了 Gemini 模型的研究和技术。与之前的迭代相比,它提供了增强的性能和效率。
2. TensorRT-LLM 在加速 Gemma 模型方面发挥什么作用?
TensorRT-LLM 是一个用于优化推理性能的开源库。它通过各种优化和内核显着提高了 Gemma 模型的速度和效率。
3. Gemma 如何支持实时性能,其含义是什么?
Gemma 由 TensorRT-LLM 和 NVIDIA H200 Tensor Core GPU 加速,在 Gemma 2B 模型上每秒实现超过 79,000 个令牌。这种实时性能水平可以为各种应用程序提供高吞吐量推理。
4. 开发者可以在哪里访问使用 TensorRT-LLM 优化的 Gemma 模型?
开发人员可以在 NVIDIA NGC 平台上找到优化的 Gemma-2B 和 Gemma-7B 模型检查点,包括预训练和指令调整的版本。这些型号与 NVIDIA GPU 兼容,包括消费级 RTX 系统。
5. TensorRT-LLM优化的FP8量化版Gemma的意义是什么?
TensorRT-LLM 优化的 Gemma FP8 量化版本提供了增强的速度和效率,可以通过减少内存占用实现更快的推理。它将在 Hugging Face 的 Optimum-NVIDIA 库中提供。
6. 开发者如何在生产环境中定制和部署Gemma模型?
开发人员可以利用 NVIDIA NeMo 框架来定制和部署 Gemma 模型。NeMo 支持各种定制技术,包括监督微调、LoRA 参数高效微调以及人类反馈强化学习 (RLHF)。
7. Gemma 型号集成了哪些安全功能?
Gemma 模型通过广泛的数据管理、PII 过滤和根据人类反馈进行强化学习来优先考虑安全性。这些措施确保负责任的人工智能实践并保护敏感信息。
8. Gemma如何为AI应用的进步做出贡献?
Gemma 经过超过 6 万亿个代币的训练,使开发人员能够自信地构建和部署高性能、负责任且先进的 AI 应用程序。其效率和可扩展性使其成为各个行业的宝贵工具。
来源:https://cioinfluence.com/it-and-devops/nvidia-and-google-collaborate-to-optimize-gemma-models-with-tensorrt-llm/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。