
目标说话人提取(Target Speaker Extraction, TSE)旨在从包含多个说话人的复杂音频中分离出特定的说话人的语音。在诸如会议交流和家庭聚会等场景中,存在诸多干扰说话人和背景噪声,这种情况下对特定说话人的语音提取是一项极具挑战的任务。以往的TSE方法大多需要使用目标说话人的注册音频这一先验信息,但这些数据并不总能轻易获取。此外,当前大多数TSE方法的研究以音频质量作为评估指标,但往往并不能提升后端语音识别(ASR)系统的准确率。针对该问题,ICASSP2024上举办了以语音识别为评判标准的目标说话人提取评测,且引入唇动视觉信息作为目标说话人先验,即第三届基于多模态信息的语音处理(Multi-modal Information based Speech Processing,MISP)挑战赛的评测任务。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和马上消费合作参加了本届MISP竞赛,提交系统取得了第二名的优异成绩。依据提交系统撰写的论文“An Audio-quality-based Multi-strategy Approach For Target Speaker Extraction In the MISP 2023 Challenge”被语音研究顶级会议ICASSP2024接收。现对该论文进行简要的解读和分享。
论文题目:An Audio-quality-based Multi-strategy Approach For Target Speaker Extraction In the MISP 2023 Challenge
合作单位:马上消费
作者列表:韩润铎、闫晓鹏、许伟铭、郭鹏程、孙佳耀、王贺、陆全、蒋宁、谢磊
论文网址:https://arxiv.org/abs/2401.03697

背景动机
目标说话人提取(TSE)的目的是从包括背景噪音和多重说话人干扰的复杂声学环境中提取特定说话人的语音[1, 2]。近两年的ICASSP会议上举办的深度噪声抑制(DNS)竞赛均围绕TSE任务。NPU-ASLP实验室也携合作伙伴两次蝉联了冠军。
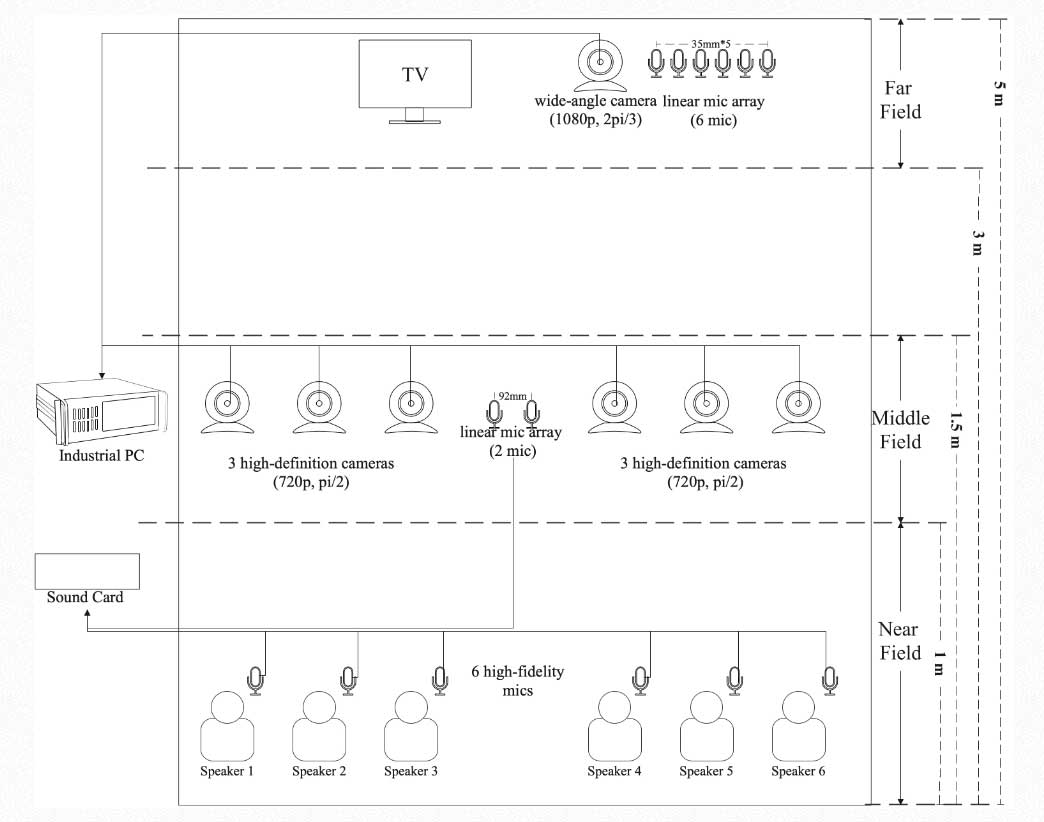
当前的TSE方案通常依赖于目标说话人的预先录制的注册音频,但这一苛刻的条件限制了其广泛应用[1]。此外,这些方案通常以音频质量指标(如主观听感)作为主要评估指标。但事实证明[3]主观听感的提升往往会带来后端语音识别率的下降。为此,MISP2023挑战赛[1]以远场6通道混合音频作为输入(如图3,使用Far Field 线性6麦克风阵列采集),以后端语音识别任务作为评估标准,同时引入了唇动视频数据(如图3,使用Middle Field摄像头进行采集)作为TSE任务的先验信息,而不是目标说话人注册音频。在这次多模态挑战赛上,为了确保前端提取的音频对后端ASR系统的有效性,该赛事采用了固定参数的ASR系统[4]来评估处理后语音识别的字错误率(CER)。在竞赛官方评估集上,我们的方法实现了33.2%的字符错误率(CER),取得了最终评估中第二名的优异成绩。
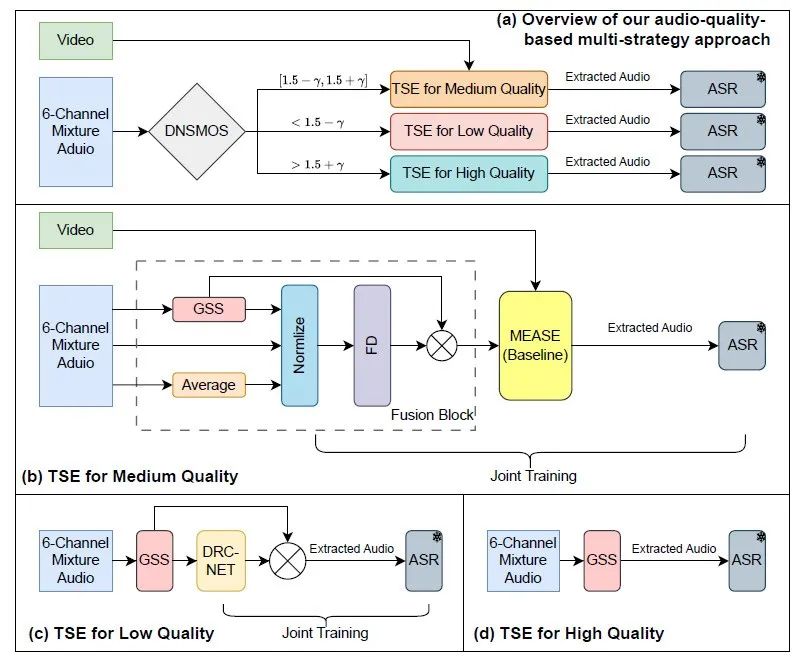
提出的方案
为了应对这种音视频目标说话人提取(AV-TSE)任务,我们首先使用DNSMOS OVRL[5]分数作为音频质量评估标准,将音频分为高中低三组,然后对每组实施不同的提取技术。其次,由于GSS[6]会错误地将目标说话人的语音信号当做干扰说话人去除,因此我们使用多通道融合方法[2],用来恢复GSS提取中丢失的目标语音信号,并进一步使用唇动视频数据的MEASE[1]网络进行目标说话人提取。此外,我们利用DRC-NET模型[7]进行进一步降噪,将原模型中的频谱映射方法[7]修改为频谱掩蔽方法,以平衡噪音的去除和语音的保留。
模型结构
针对不同质量水平的音频,一个关键的考虑因素是优先保留语音减少失真,更多地关注降噪,还是在两者之间寻求平衡。因此,我们根据DNSMOS OVRL分数将音频分为三类:分数高于 1.5 + γ 的被归类为高质量,1.5 – γ 到 1.5 + γ 之间的被认为是中等质量,低于 1.5 – γ 的被命名为低质量。 (一点五)是基线系统在开发集[1]上的DNSMOS OVRL分数,我们认为它是区分音频质量的中间值。阈值 γ 是一个超参数,我们在实验中从{0.1, 0.2, 0.3, 0.4, 0.5}中调整,发现当 γ = 0.3 时结果最好。然后对每个类别应用不同的处理策略,如图3(a)所示。
对于高质量音频,我们直接应用引导源分离(Guilded Source Separation, GSS)方法[6],如图3(d)所示,它在提取多说话人音频时具有最小语音失真的优势。然而,对于中低质量音频,GSS会错误地将目标说话人的语音信号当做干扰说话人去除,并在去除噪音干扰方面效果不佳。因此,需要应用其他方法在GSS初步提取后进一步增强语音信号。
对于中等质量音频,我们增加了一个融合模块(Fushion block),用于合并多通道信息并弥补GSS导致的目标语音信号丢失,并利用多模态特征感知语音增强(Multimodal Embedding Aware Speech Enhancement,MEASE)网络[1]进行进一步提取。如图3(b)所示,Fushion block将8通道输入音频(包括远场6通道音频、其平均值和GSS处理过的音频)合并为单通道输出。8通道音频首先被标准化为-25db的响度。随后,它经过一个频率下采样(FD)层,以合并多通道的幅度信息。FD层的结构类似于[2],包括门控卷积、累积层标准化(cLN)和PReLU。FD层的输出用作远场6通道音频平均幅度的掩码(Mask)。然后将掩蔽的时频域音频转换回时域,并输入到MEASE网络,该网络使用目标说话人的唇动视频作为目标说话者的先验信息,进一步从音频中提取目标语音。其结构类似于官方基线系统[1],只是将音频和视频嵌入提取模块改为了不经过预训练的34层的ResNet结构。
对于低质量音频,我们使用DRC-NET[7]网络在GSS之后增强单通道音频,如图3(c)所示,可以有效地去除噪音和混响干扰。为了将过度增强引起的语音失真降低到最小,我们修改了原始网络结构,从频谱映射转为频谱掩蔽方法,选择了包含相位信息的CRM Mask[8]。网络的其余结构与[7]中描述的保持一致。
训练方式
模型训练分为两个阶段,使用仿真数据对前端系统进行预训练,然后与后端自动语音识别(ASR)系统在真实数据上进行联合训练。

实验
数据集
实验在MISP2023挑战赛数据集上进行。远场6通道数据的仿真方法与[1]中描述的类似。在第一阶段训练期间,我们对干净音频进行动态加噪,随机在干净音频中添加-10db到+20db的噪声,并将其与其他近场麦克风音频结合(模拟干扰人声)。然后,根据房间尺寸添加混响,以模拟远场6通道音频。使用真实场景下的远场6通道音频用于第二阶段训练,即与后端ASR模型联合训练。所有作为语音提取先验信息的唇动视频数据都是由中场摄像机录制。模型效果在MISP 2023挑战赛官方Dev集和Eval集上进行测试。
结果
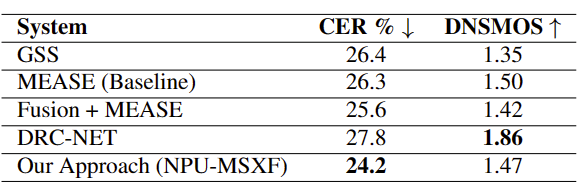
表1展示了在Dev集上进行的方案消融实验。DNSMOS OVRL分数表明,GSS后集成神经网络有效的去除了噪声,但代价是引入了一些语音失真。因此,针对不同音质采用不同的提取策略至关重要,这在Dev集上获得了最低的字错误率(CER)。融合模块与MEASE网络结合使用时,与单独使用MEASE网络相比,实现了更低的CER,证明了融合模块在整合多通道信息方面的有效性。
表1 Dev集上不同模型的CER和DNSMOS得分
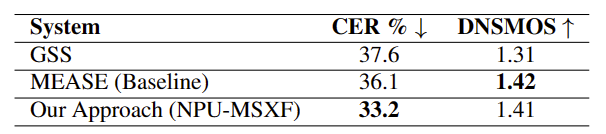
如表2所示,在竞赛排名的Eval集上,我们的方法取得了比GSS和MEASE模型更低的CER,最终在挑战赛中获得了第二名的优异成绩。值得注意的是,更高的DNSMOS OVRL分数并不总是与更低的CER对齐,换句话说,音频质量指标不能单独用于评估后端ASR系统的性能。
表2 Eval集上不同模型的CER和DNSMOS得分
参考文献
[1] S. Wu, C. Wang, H. Chen, Yu. Dai, C. Zhang, R. Wang, H. Lan, J. Du, C. Lee, J. Chen, et al., “The multimodal information based speech processing (misp) 2023 challenge: Audio-visual target speaker extraction,” arXiv preprint arXiv:2309.08348, 2023.
[2] Y. Ju, J. Chen, S. Zhang, S. He, W. Rao, W. Zhu, Y. Wang, T. Yu, and S. Shang, “Tea-pse 3.0: Tencent-ethereal-audio-lab personalized speech enhancement system for icassp 2023 dns-challenge,” in ICASSP. IEEE, 2023.
[3] M. Delcroix, K. Zmolikova, K. Kinoshita, A. Ogawa, and T. Nakatani, “Single channel target speaker extraction and recognition with speaker beam,” in ICASSP. IEEE, 2018.
[4] Y. Dai, H. Chen, J. Du, X. Ding, N. Ding, F. Jiang, and C. Lee, “Improving audio-visual speech recognition by lip-subword correlation based visual pre-training and cross-modal fusion encoder,” in 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2023.
[5] C. Reddy, V. Gopal, and R. Cutler, “Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP. IEEE, 2022.
[6] D. Raj, D. Povey, and S. Khudanpur, “Gpu-accelerated guided source separation for meeting transcription,” in Interspeech, 2022.
[7] J. Liu and X. Zhang, “Drc-net: Densely connected recurrent convolutional neural network for speech dereverberation,” in ICASSP. IEEE, 2022.
[8] D. Williamson, Y. Wang, and D. Wang, “Complex ratio masking for monaural speech separation,” IEEE/ACM transactions on audio, speech, and language processing, 2015.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
