
目前,AI 可以生成多种形式的高质量内容,包括文字(OpenAI 的 GPT 3)、图片(谷歌的 Imagen)、视频(Meta 的 Make-A-Video)等。
各大科技公司在生成式 AI 上“各显神通”,AI 在内容创作上不断突破人们想象力极限,也在逐步“削弱”人类的创造力优势。
近日,谷歌又开发出一种音频生成 AI。此名为 AudioLM 的模型只通过收听音频即可生成逼真的语音和音乐。
AI 生成的音频其实很常见,像生活中用到的语音助手使用自然语言处理声音。OpenAI 曾开发名为 Jukebox 的 AI 音乐系统也令人印象深刻。
但过去用 AI 生成音频,大都需要人们提前准备转录和标记基于文本的训练数据,这需要耗费极大时间和人力。
而谷歌在其官方博文中表示:“AudioLM 是纯音频语言模型,无须借助文本来训练,只是从原始音频中进行学习。”
相较之前的类似系统,AudioLM 生成的音频在语音语法、音乐旋律等方面,具有长时间的一致性和高保真度。
9 月 7 日,相关论文以《AudioLM: 一种实现音频生成的语言建模方法》(AudioLM: a Language Modeling Approach to Audio Generation)为题提交在 arXiv 上。
正如音乐从单个音符构建复杂的音乐短语一样。生成逼真的音频需要以不同比例表示的建模信息。而在所有这些音阶上创建结构良好且连贯的音频序列是一项挑战。
据了解,音频语言模型 AudioLM 的背后利用了文本到图像模型的进步来生成音频。
近年来,在大量文本上训练的语言模型,除了对话、总结等文本任务,也在高质量图像上展示出优秀的才能,这体现了语言模型对多类型信号进行建模的能力。
但从文本语言模型转向音频语言模型,仍有一些问题需要解决。比如,文本和音频之间不是一一对应关系。同一句话可以有不同风格的呈现方式。此外,谷歌还在其官网提到:“音频的数据速率要更高,用数十个字符就可表示的书面句子,其音频波形通常含有几十万个值。”
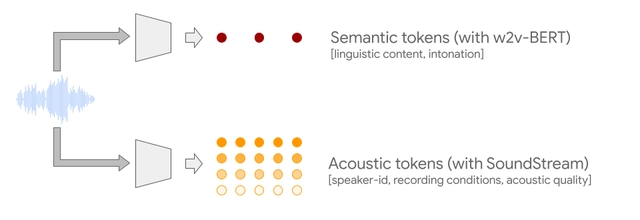
为解决这些问题,研究人员采用了语义和声学两种音频令牌。
语义令牌(语义标记来自音频框架 w2v-BERT)捕获语音、旋律等局部依赖性和语法、和声等全局长期结构。但是,语义令牌创建的音频保真度较差。因此谷歌还利用了由 SoundStream 神经编解码器生成的声学令牌,该令牌捕获音频波形的详细信息。
(来源:谷歌)
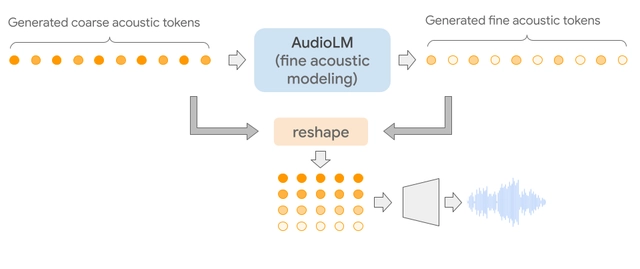
在经过对音频序列的声学属性、结构等分别进行建模,以及用精细声学模型为语音添加生动特征几个步骤后,声学令牌被送到 SoundStream 解码器以再建波形。
(来源:谷歌)
谷歌还展示 AudioLM 的一般适用性,在被要求继续语音或音乐,并生成在训练期间未看到的新内容时,AudioLM 实现了效果流畅、风格接近的音频生成。
特别是,使用 AudioLM 生成的钢琴音乐比使用现有 AI 技术生成的钢琴音乐听起来更自然,后者感觉往往很混乱。
为了生成逼真的钢琴音乐,AudioLM 必须在钢琴键被击中时捕捉每个音符中包含的许多微妙的振动,生成的音乐还必须在一段时间内保持其节奏与和声。
对此,在卡内基梅隆大学研究计算机生成音乐的教授罗杰·丹嫩伯格(Roger Dannenberg)对媒体提到,AudioLM 在重新创造人类音乐中固有的一些重复模式方面出奇地擅长,或表明它正在学习某种结构的多个层次。
AudioLM 经过训练,可以了解哪些类型的声音片段经常一起出现,并且反向使用该过程来生成句子。除了音乐,它还可以模仿原始说话者的口音和节奏,并能学习口语中固有的停顿和感叹等特点。经测试,AudioLM 生成的语音与真实语音几乎无法区分。
据了解,AudioLM 远远超出了语音的范围,可以模拟任意音频信号。这可方便扩展到其他类型的音频,以及将 AudioLM 集成到编码器-解码器框架中,以执行文本到语音转换或语音到语音转换等条件任务。
然后,更自然的语音生成技术,可以用作视频和幻灯片的背景音轨,帮助改善在医疗等环境下工作的可访问性工具和机器人。
未来,研究团队还希望创造更复杂的声音,就像一个乐队使用不同的乐器,或模仿热带雨林中嘈杂的声音。
但值得注意的是,AI 生成音频这项技术仍有一些问题需要去面对,比如,是否有必要向音乐家支付版税?这个问题已经随着图像生成模型的出现而出现。
此外,AI 生成的音频正变得与真实语音难以区分,这使得其很容易被用来传播错误信息。
研究人员在论文中也提到,他们已经在考虑并努力缓解以上问题,例如,通过开发相关工具,来区分自然声音和 AudioLM 产生的声音,并在 AI 生成的产品中加入水印,以防止可能的滥用。
最后,在 AudioLM 上的工作目前主要是出于研究目的,谷歌还没有计划在更大范围内发布它。
参考资料:
https://ai.googleblog.com/2022/10/audiolm-language-modeling-approach-to.html
https://www.technologyreview.com/2022/10/07/1060897/ai-audio-generation/
https://arxiv.org/abs/2209.03143
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
