
9月21日,OpenAI 发布了一个名为「Whisper 」的神经网络,声称其在英语语音识别方面已接近人类水平的鲁棒性和准确性。
「Whisper 」式一个自动语音识别(ASR)系统,研究团队通过使用从网络上收集的68万个小时多语音和多任务监督数据,来对其进行训练。
训练过程中研究团队发现,使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。
此前有不同研究表明,虽然无监督预训练可以显著提高音频编码器的质量,但由于缺乏同等高质量的预训练解码器,以及特定于数据集中的微调协议,因此在一定程度上限制了模型的有效性和鲁棒性;而在部分有监督的方式预训练语音识别系统中,其表现会比单一源训练的模型呈现出更高的鲁棒性。
对此,在「Whisper 」中,OpenAI 在新数据集比现有高质量数据集总和大几倍的基础上,将弱监督语音识别的数量级扩展至68万小时;同时,研究团队还演示了在这种规模下,所训练模型在转移现有数据集的零射击表现,可消除任何特定于数据集微调的影响,以实现高质量结果。
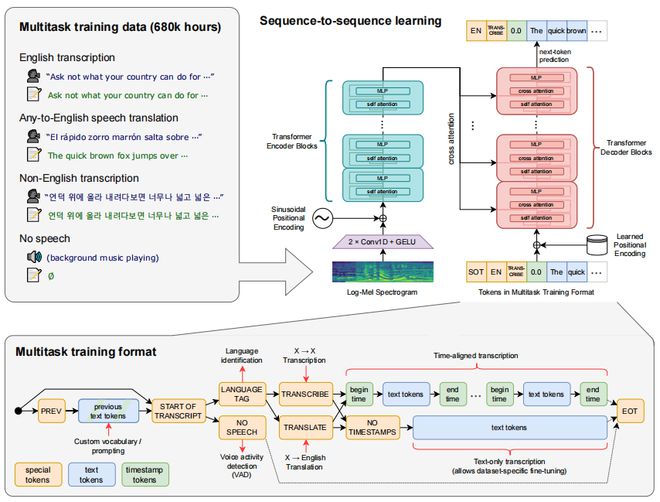

在许多不同的语音处理任务中训练一个序列到序列的转换器模型,包括多语言语音识别、语音翻译、口头语言识别和语音活动检测;所有任务都表示为要由解码器预测的标记序列,允许单一模型取代传统语音处理管道的不同阶段;多任务训练格式使用一组特殊的标记,作为任务指定者或分类目标
Whisper 架构采用一种简单的端到端方法,通过编码器-解码器 Transformer 来实现:输入音频被分成30秒的块,转换成 log-Mel 频谱图后传递到编码器。解码器可预测相应的文本标题,并与特殊标记混合,由这些标记指导单个模型执行诸如语言识别、短语级时间戳、多语言语音转录和英语语音翻译等任务。

值得一提的是,由于「Whisper 」是在一个庞大且多样的数据集上进行,没有针对任何特定的数据集进行微调,因此它不会击败专门研究 LibriSpeech 性能的模型。
此外研究团队还发现,当在许多不同的数据集上测量「Whisper 」的零样本性能时,「Whisper 」相比其他模型表现更加稳健,错误率降低了 50%。
除了足够大的数据集规模外,「Whisper 」还支持多种语言的转录,以及将这些语言翻译成英语。
当前在68万小时音频中,共11.7万个小时覆盖了96中其他语言,还包括12.5万个小时的转录和翻译数据,即大约有三分之一是非英语的。
「Whisper 」会交替执行以原始语言转录或翻译成英语的任务,对此研究团队发现,这种方法在学习语音到文本的翻译方面特别有效,并且优于 CoVoST2 到英语翻译零样本的监督 SOTA。
目前,「Whisper 」已开源,可用于对语音识别方面的进一步研究。
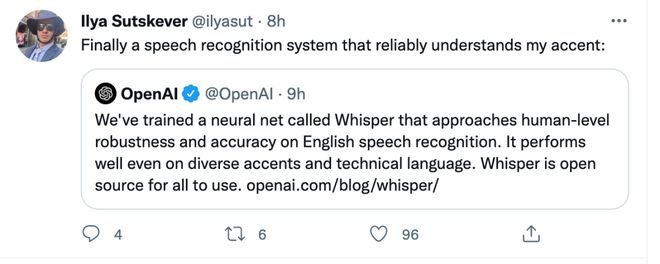
OpenAI 创始人 Ilya Sutskever 对此表示,“终于有一个能理解我说话的可靠的语音识别系统。”
作者 | 黄楠
编辑 | 陈彩娴
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。