
本文提出了压缩和预测任务的等价性,并鼓励从压缩视角来评估大模型,其贡献有:
- 提出了压缩和预测任务的等价性(“prediction-compression equivalence”):文章指出,压缩和预测本质上是等价的,因此可以用预测模型做压缩;
- 探究了大模型的无损压缩能力:总结了“预测模型+算术编码”的压缩方式,并把 NLP 大模型用于压缩;
- 尝试用基于文本训练的大模型做跨模态通用编码器:文中用在文本数据上训练好的大模型,在音频和图像数据上进行压缩,得到的压缩效果可超过针对性的编码器(e.g. PNG, FLAC);
- 提供了关于 scaling law 的新视角:指出了数据集大小、模型规模和压缩性能的关系,这意味着简单地增加模型的规模并不总是解决问题的方法;
- 关于 tokenization 的探究:作者发现,虽然 tokenization(也可以被视为预压缩过程)通常不会提高压缩性能,但它可以增加上下文信息,因此可被用来提高压缩性能。
论文题目:Language Modeling Is Compression
来源:arxiv
作者:Delétang G, Ruoss A, Duquenne P A, et al.
内容整理: 赵研
介绍
预测与压缩
为什么压缩和预测本质上是等价的
压缩基本上是一种高效表示数据的方法。预测模型的目标是从历史数据中预测未来的数据或输出。如果一个模型能够准确地预测数据,那么这意味着它已经学会了数据的某种结构或模式。知道这些结构或模式可以使我们更有效地表示或编码数据,从而实现压缩。
为什么可以用 NLP 大模型做高效的压缩
大型模型有更多的参数,这意味着它们有更大的容量来学习和记住数据中的复杂模式。这种高度的模式识别能力使得大型模型能够更准确地预测数据,因此也能够更有效地进行压缩。
高效的数据压缩 = 预测模型 + 统计编码方法
当预测模型与算术编码结合使用时,可以实现高效的数据压缩。这种组合的核心思想是:预测模型提供一个字符或一个 token 出现的概率分布,而算术编码利用这些概率分布来高效地编码数据。这意味着,压缩的效果主要取决于概率模型的性能。然而,并不是所有的应用或数据都适合使用预测模型进行压缩。例如,一些高度随机或噪声大的数据可能不适合使用预测模型进行压缩。
算术编码
虽然有多种方法可以实现无损压缩(e.g. Huffman编码、算术编码、ANS),但算术编码在码长方面是最优的。
算术编码尝试使每个编码的位数接近于其真实的信息内容(i,e.,符号的负对数概率)。这意味着算术编码得到的码率是非常接近熵的,是理论上的最优编码。
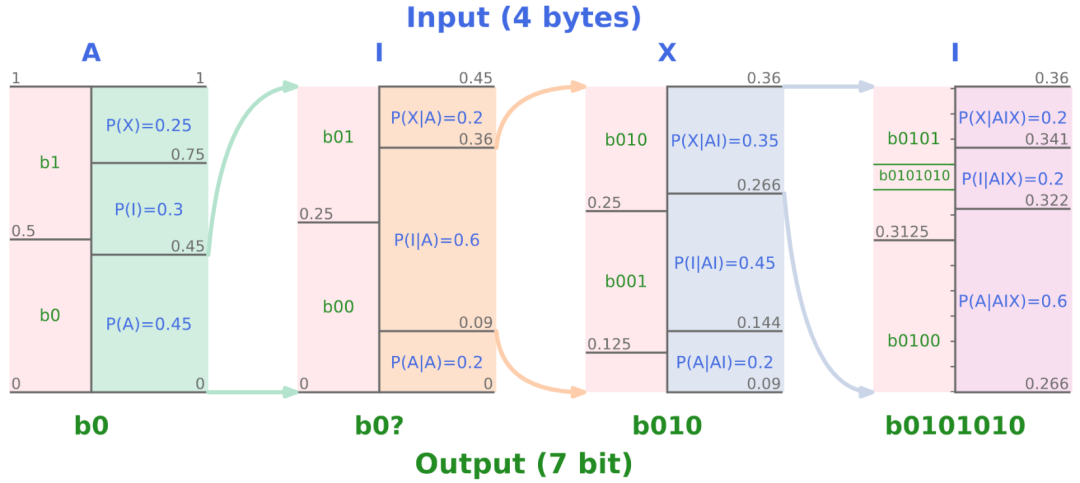
具体过程
- Step 1. 模型预测
对于要编码的数据序列中的每一个数据项,预测模型会提供一个概率分布,表示每个可能的数据项出现的概率。例如,对于文本数据,预测模型可能会预测下一个字符是’a’的概率为0.1、是’b’的概率为0.05、是’c’的概率为0.15,等等。 - Step 2. 算术编码
算术编码开始时,定义一个 [0, 1) 的概率区间。对于每一个要编码的符号,算术编码会将当前的概率范围划分为若干子区间,每一个子区间对应一个可能的符号,其大小正比于该数据项出现的概率。
例如,如果有三个字符’a’、’b’和’c’,它们的预测概率分别是0.1、0.05和0.15,那么初始的 [0, 1) 区间可能会被划分为以下三个子区间:”a” [0, 0.1);”b” [0.1, 0.15);”c” [0.15, 0.3),然后,选择与当前符号对应的子范围,并以此为基础继续细分后续符号的区间。通过不断地递归细分,会产生一个非常具体的小区间,该区间唯一地表示原始数据序列,因此,从该区间中随机选择一个概率值,即可作为该序列的编码输出。
解码时,可以使用相同的预测模型和区间划分方法,从编码的数值反向推导出原始数据序列。
基于 NN 模型的数据压缩(以 Transformer 为例)
基于 Transformer 的大模型在多种预测任务中都表现出色,因此被认为是与算术编码一起使用的理想候选对象。
在线压缩与离线压缩
- 在线压缩(Online compression): 模型直接在要压缩的数据上进行训练;
- 离线压缩(Offline compression): 模型首先在外部数据集上预训练好参数,然后用它来压缩另一个数据集。
虽然 Online compression 的性能一般好于 Offline,但编解码都需要在线训练,非常耗时。
上下文长度(Context length)的重要性
Transformer 引入了 attention 机制,具有较好的上下文学习能力,因此可根据上下文自适应输出各 token 的概率分布(可类比传统编码中的CABAC)。而如何设置上下文长度,对模型的压缩性能具有很大的影响。
- 上下文长度决定了模型一次可压缩的最大字节
在神经网络模型中,上下文是输入到模型中的连续的信息块或序列,也就是说,上下文长度决定了模型一次可以考虑的信息量。在压缩场景中,需要对每个 token 做概率预测,而这个预测时基于上下文进行的,一个具有更长上下文的模型可能会更好地利用前面信息进行高效压缩。因此,上下文长度会决定模型一次可压缩的最大字节数量。 - Transformer 模型的上下文限制
Transformer 模型一次只能压缩约 2KB 的 token(每个 token 用 2-3 字节编码),同时还需要大量的计算资源。这意味着,Transformer模型在处理大量数据时可能会受到限制。
具体来说,一些预测任务(e.g. algorithmic reasoning, long-term memory),需要很长的上下文。这意味着,要成功处理这些任务,模型需要能够考虑并使用大量的信息。由于现有的 Transformer 模型在上下文长度方面有限制,所以扩展它们的上下文长度是当前研究的一个关键挑战。
从压缩视角来评估大模型
文章建议从压缩视角来研究和评估大模型,也就是说,通过分析模型在压缩任务中的表现,我们可以了解其在预测任务中的潜在问题。作者在文中,验证了一些 NLP 大模型的 offline 跨模态压缩能力。
关于”scaling law”在压缩任务中的理解
在大模型研究中,将模型规模与其性能之间的关系,定义为”scaling law”。该规律对压缩任务同样适用,但除了模型效率的问题,还有另一个发现:在压缩任务中,当模型规模超过某一点后,压缩性能可能反而会下降。
实验设定
Compressor 中用到的大模型
- vanilla Decoder-only Transformer
- Chinchilla-like 模型
Baselines
- 通用编码器:gzip 和 LZMA2;
- 针对图像的编码器 PNG,针对音频的编码器 FLAC。
数据集
跨模态
为了评估压缩的通用能力,研究者选择了三种不同的数据模态:文本、图像和音频,为了确保结果之间可以比较,所有数据集的大小都被限制为1GB。
- 文本:enwik9
- 图像:ImageNet
- 音频:LibriSpeech
输入设置
编码器能处理的上下文长度各不相同,Transformer 的上下文限制为 2048B,Chinchilla 约 10KB,gzip 为 32KB,而 LZMA2 几乎没有上下文长度限制。
- 有两种方式可以处理超过上下文长度的序列:1)逐字节滑动,2)将输入序列分块输入。由于第一种方法比较耗时,因此选择第二种方法,将所有数据集分为 2048 Byte 的序列,然后逐个输入到编码器中;
- 传统编码器通常在其输出中包括一个 header,该 header 可能比压缩数据大,所以对所有批次只计算一次;
- 由于分块会降低上下文长度远大于2048的编码器的性能,因此也验证了它们在未分块数据集上的压缩率。
实验结果
两种压缩率
1. raw compression rate
- 不考虑模型本身的存储码率(model size),只考虑压缩出的数据码率;
- 每个模型参数用 float 16 的精度编码(2 Byte)。
2. adjusted compression rate
- 将 model size 也作为压缩后码率的一部分;
- 这样算的话,只有数据集较大时,用较大的模型才比较划算(数据集太小时,可能导致压缩比>1)。
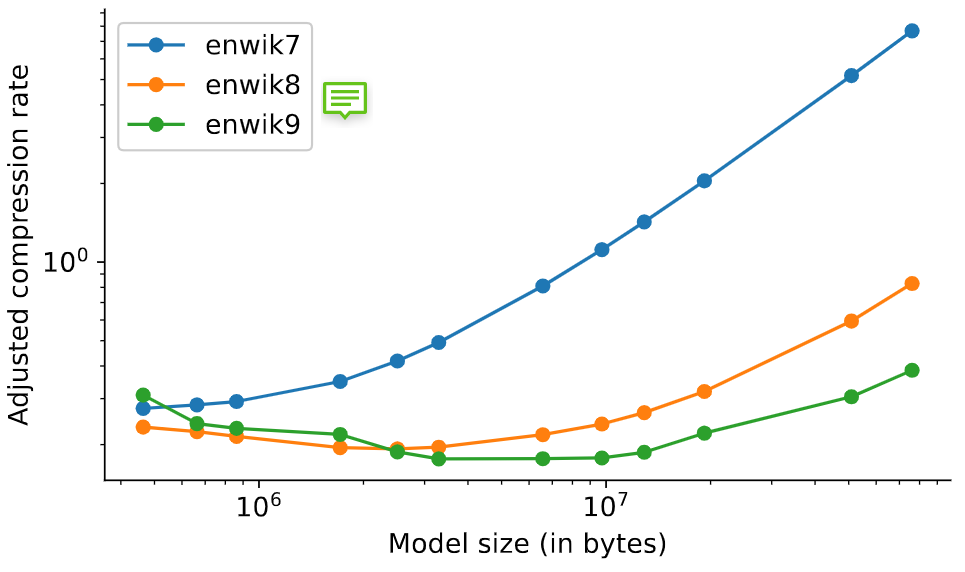
压缩率比较
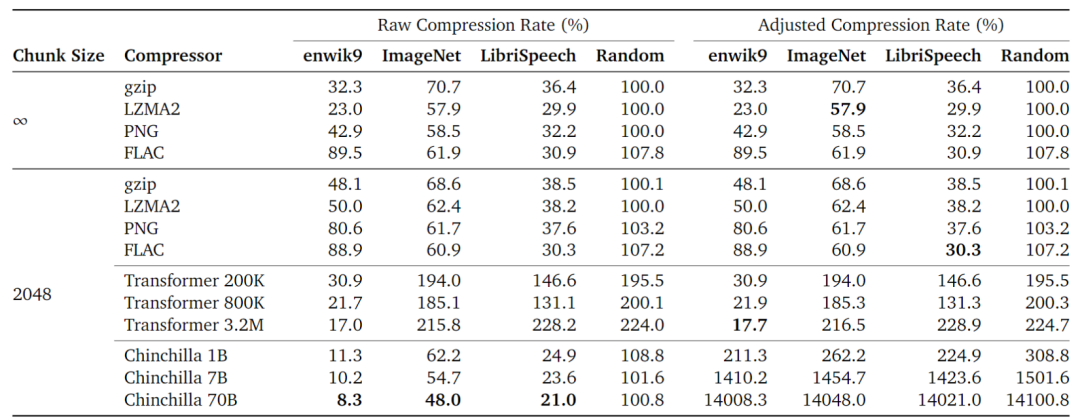
- 不限制 chunk size 时,传统编码器的效果都得到了明显提升,说明上下文长度对编码性能有很大影响;
- 尽管 Chinchilla 主要在文本上训练,但也表现得像通用编码器,甚至在图像和音频上超过了其他 baseline;
- 较小的 Transformer 模型在 enwik8 上训练后,只能在相近的数据集(enwik9)上取得较好压缩率;
- 大模型虽然有较好的压缩性能,但如果考虑到其自身的数据量,在 1G 数据集上压缩就显得很不划算。理论上,如果数据集是无限的,我们可以忽略模型的大小。实际中,大模型只能在TB级(或更大)的数据集上实现有意义的压缩率(Adjusted Compression Rate)。
Tokenization 也是一种压缩
Transformer 模型通常不是在原始输入数据上进行训练,而是在其 tokenized 版本上进行训练(为了提高效率和性能),结果是,Transformer 实际上是在已压缩的数据上进行训练,其中 tokenizer 起到了压缩器的作用。为了研究 tokenization 对压缩性能的影响,文中在 enwik8 上用不同的 tokenizer 训练了 Transformer 模型:
- ASCII(i.e. 大小为 256 的 alphabet);
- 在 enwik8 上训练的大小不同的 byte-pair encoding(token 数量为 1K, 2K, 5K, 10K, 20K 不等)。
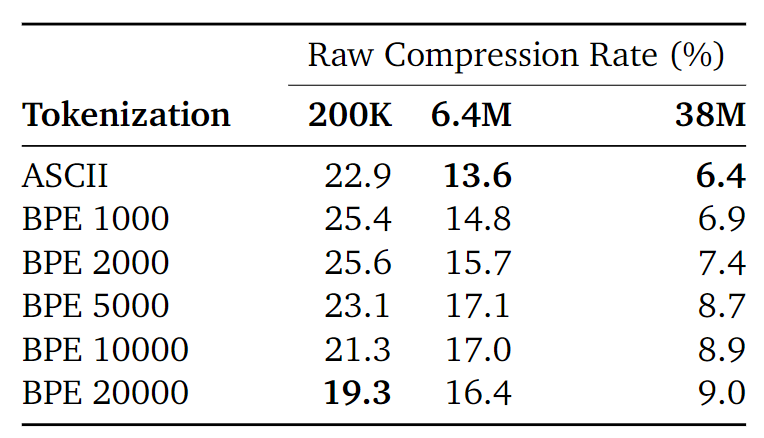
增加 token 数量(i.e. alphabet size)会减少序列的长度,并增加模型上下文中的信息量,但这也造成了压缩的挑战:当 token 的 alphabet 增大时,模型必须从更大的可能的符号集合中进行预测,输出的可能性增加,也就造成模型对概率分布的预测更加困难,这增加了模型的不确定性。
理论上讲,由于 tokenization 是无损压缩,这两种效应该会相互抵消。但实验表明,对于小模型,增加 token 数量可以提高压缩性能;而对于大模型,拥有更大的tokens 数量似乎会损害模型的最终压缩率。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
