
在过去的两年中,自动语音识别(Automatic Speech Recognition, ASR)在商用上取得了重要的发展,其中一个衡量指标就是:
多个完全基于神经网络的企业级 ASR 模型成功上市,如 Alexa、Rev、AssemblyAI、ASAPP 等。
2016 年,微软研究院发表了一篇文章,宣布他们的模型在已有 25 年历史的 “Switchboard” 数据集上,达到了人类水平(通过单词错误率来衡量)。
ASR 的准确性仍在不断提高,在更多的数据集和用例中逐渐达到人类水平。
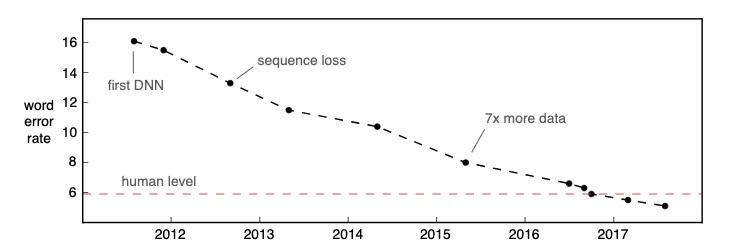
随着 ASR 技术的识别准确度大幅提升,同时应用场景越来越丰富,我们相信:现在还不是 ASR 商用的巅峰,该领域的研究与市场应用还有待发掘。
我们预计未来十年 AI 语音的相关研究和商业系统将重点攻克以下五个领域 :
1 多语言 ASR 模型
” 在未来十年,我们将在生产环境中部署真正的多语言模型,使开发人员能够构建任何人都能理解任意语言的应用程序,从而真正向全世界释放语音识别的力量。”
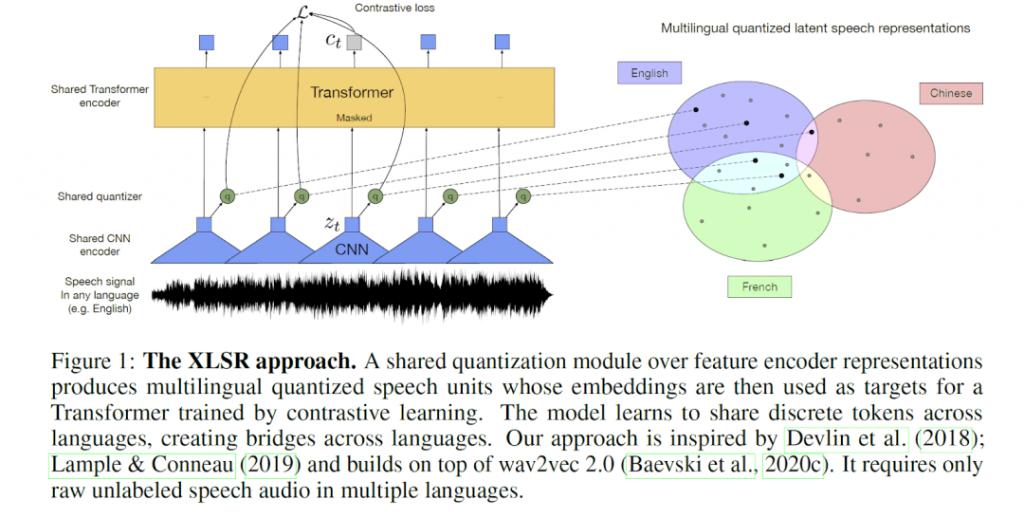
图源:Alexis Conneau 等人在 2020 年发表的 “Unsupervised cross-lingual representation learning for speech recognition” 论文
如今的商用 ASR 模型主要使用英语数据集进行训练,因此对英语输入具有更高的准确性。由于数据可用性和市场需求,学术界和工业界对英语的长期关注度更高。法语、西班牙语、葡萄牙语和德语等商业流行语言的识别准确度虽然也较为合理,但显然存在一个训练数据有限且 ASR 输出质量相对较低的语言长尾。
此外,大多数商业系统都是基于单一语言,这无法适用于许多社会特有的多语言场景。多语言可以采用背靠背语言的形式,例如双语国家的媒体节目。亚马逊最近推出了一款集成语言识别(LID)和 ASR 的产品,在处理这一问题上取得了长足进步。相比之下,跨语言(也称为语码转换)是个人使用的一种语言系统,该系统可以将两种语言的单词和语法结合在同一个句子中。这是一个学术界继续取得有趣进展的领域。
正如自然语言处理领域采用多语言方法一样,我们将会看到 ASR 在未来十年也会效仿。随着我们学习如何利用新兴的端到端技术,我们将会训练可以在多种语言之间进行迁移学习的大规模多语言模型。Meta 的 XLS-R 就是一个很好的例子:在一个演示中,体验者可以说 21 种语言中的任何一种,而不需要指定某种语言,模型最终都会翻译成英语。通过理解和应用语言之间的相似性,这些更智能的 ASR 系统将为低资源语言和混合语言用例提供高质量的 ASR 可用性,并将实现商业级别的应用。
2 丰富的标准化输出对象
” 在未来十年,我们相信商业 ASR 系统将输出更丰富的转录对象,其中包含的内容将不止简单的单词。此外,我们预计,这种更丰富的输出将得到 W3C 等标准组织的认可,以便所有 API 都将返回类似构造的输出。这将进一步释放世界上每个人的语音应用潜力。”
尽管国家标准技术研究院(NIST)在探索 ” 丰富转录 ” 方面有着悠久传统,但在将其纳入 ASR 输出的标准化和可扩展格式方面仍是浅尝辄止。丰富转录的概念最初涉及大写、标点和日记化,但在某种程度上扩展到说话人角色和一系列非语言性言语事件。预期的创新包括转录来自不同说话者、不同情绪和其他副语言特征的重叠语音,以及一系列非语言甚至非人类的语音场景和事件,还可以转录基于文本或语言多样性的信息。Tanaka 等人描绘了一个用户可能希望在不同丰富程度的转录选项中进行选择的场景,显然,我们预测的附加信息的数量和性质是可指定的,这取决于下游应用。
传统的 ASR 系统能够在识别口语单词的过程中生成多个假设的网格,这些已被证明在人工辅助转录、口语对话系统和信息检索中大有裨益。在丰富的输出格式中包含 n-best 信息将鼓励更多用户使用 ASR 系统,从而改善用户体验。虽然目前不存在用于构建或存储语音解码过程中当前生成或可能生成的附加信息的标准,但 CallMiner 的开放语音转录标准(OVTS)朝这个方向迈出了坚实的一步,使企业易于探索和选择多个 ASR 供应商。
我们预测,在未来,ASR 系统将以标准格式产生更丰富的输出,从而支持更强大的下游应用程序。例如,ASR 系统可能会输出全部可能网格,并且应用程序可以在编辑转录内容时使用这些附加数据进行智能自动转录。类似地,包括附加元数据(如检测到的区域方言、口音、环境噪声或情绪)的 ASR 转录可以实现更强大的搜索应用。
3 面向所有人的大规模 ASR
” 在这十年中,大规模的 ASR(即私有化、可负担、可靠和快速)将成为每个人日常生活的一部分。这些系统将能够搜索视频,索引我们参与的所有媒体内容,并使世界各地的听力受损消费者能够访问每个视频。ASR 将是对每一个音频和视频都实现可访问和可操作的关键。”


我们可能都在大量使用音视频软件:播客、社交媒体流、在线视频、实时群聊、Zoom 会议等等。然而相关的内容实际上很少被转录。如今,内容转录已经成为 ASR API 的最大市场之一,并将在未来十年呈指数级增长,特别是考虑到它们准确性和经济性。话虽如此,ASR 转录目前仅用于特定应用程序(广播视频、某些会议和播客等)。因此,许多人无法访问此媒体内容,并且在广播或活动结束后很难找到相关信息。
在未来,这种情况将会改变。正如 Matt Thompson 在 2010 年预测的那样,在某种程度上,ASR 价格廉价并被广泛普及,以至于我们将体验到他所谓的 ” 演讲性 “。我们预计,未来几乎所有音频和视频内容都将被转录,并且可立即访问、可存储、可大规模搜索。但 ASR 的发展不会到此停滞,我们还希望这些内容具有可操作性。我们希望消费或参与的每个音视频会提供额外的上下文,例如从播客或会议中自动生成的见解,或视频中关键时刻的自动总结等等,我们希望 NLP 系统可以将上述处理日常化。
4 人机协同
” 到本世纪末,我们将拥有不断发展的 ASR 系统,它就像一个活的有机体,在人类的帮助或自我监督下不断学习。这些系统将从现实世界中的不同渠道学习, 以实时而非异步的方式理解新单词和语言变体,自我调试并自动监控不同的用法。”

随着 ASR 成为主流并涵盖越来越多的用例,人机协同将发挥关键作用。ASR 模型的训练很好地体现了这一点。如今,开源数据集和预训练模型降低了 ASR 供应商的准入门槛。然而,训练过程仍然相当简单:收集数据、注释数据、训练模型、评估结果、改进模型。但这是一个缓慢的过程,并且在许多情况下,由于调整困难或数据不足而容易出错。Garnerin 等人观察到,元数据缺失和跨语料库表示的不一致性使得在 ASR 性能方面难以保证同等的准确性,这也是 Reid 和 Walker 在开发元数据标准时试图解决的问题。
在未来,人类将通过智能手段高效地监督 ASR 训练,在加速机器学习方面发挥日益重要的作用。人在回路方法将人工审查员置于机器学习 / 反馈循环中,可以对模型结果进行持续审查和调整。这会使机器学习更快、更高效,从而产生更高质量的输出。今年早些时候,我们讨论了 ASR 的改进如何使 Rev 的人工转录员(称为 “Revvers”)能够对 ASR 草案进行后期编辑,从而提高工作效率。Revver 的转录可以直接输入到改进的 ASR 模型中,形成良性循环。
对于 ASR,人类语言专家仍然不可或缺的一个领域是反向文本规范化(ITN),他们将识别的字符串(如 “five dollars”)转换为预期的书面形式(如 “$5″)。Pusateri 等人提出了一种使用 ” 手工语法和统计模型 ” 的混合方法,Zhang 等人继续沿用这些思路,用人工制作的 FST 约束 RNN。
5 负责任的 ASR
” 与所有人工智能系统一样,未来的 ASR 系统将坚持更严格的人工智能伦理原则,以便系统平等对待所有人,可解释性程度更高、对其决策负责、并尊重用户及其数据的隐私。”

未来的 ASR 系统将遵循人工智能伦理的四项原则:公平性、可解释性、尊重隐私和问责制。
公平性:无论说话者的背景、社会经济地位或其他特征如何,公平的 ASR 系统都能识别语音。值得注意的是,构建这样的系统需要识别并减少我们的模型和训练数据中的偏差。幸运的是,政府、非政府组织和企业已经着手创建识别和减轻偏见的基础设施。
可解释性:ASR 系统将不再是 ” 黑盒 “:它们将根据要求对数据收集与分析、模型性能与输出过程进行解释。这种附加的透明度要求可以对模型训练和性能进行更好的人为监督。与 Gerlings 等人一样,我们从一系列利益相关者(包括研究人员、开发人员、客户,以及 Rev 案例中的转录学家)的角度来看待可解释性。研究人员可能想知道输出错误文本的原因,以便缓解问题;而转录学家可能需要一些证据来证明 ASR 为什么会这么认为,以帮助他们评估其有效性,特别是在嘈杂的情况下,ASR 可能比人 ” 听 ” 得更好。Weitz 等人在音频关键词识别的背景下,为终端用户实现可解释性采取了重要的初步措施。Laguarta 和 Subirana 已将临床医生指导的解释纳入用于阿尔茨海默症检测的语音生物标记系统。
尊重隐私:根据各种美国和国际法律,” 语音 ” 被视为 ” 个人数据 “,因此,语音记录的收集和处理受到严格的个人隐私保护。在 Rev,我们已经提供了数据安全和控制功能,未来的 ASR 系统将进一步尊重用户数据的隐私和模型的隐私。在许多情况下,这很可能涉及将 ASR 模型推向边缘(在设备或浏览器上)。语音隐私挑战正在推动这一领域的研究,许多司法管辖区,如欧盟,已经开展立法工作。隐私保护机器学习领域有望引起大家对技术这一关键方面的重视,使其能够被公众广泛接受和信任。
问责制:我们将对 ASR 系统进行监控,以确保其遵守前三项原则。反过来需要投入资源和基础设施,以设计和开发必要的监测系统,并针对调查结果采取措施。部署 ASR 系统的公司将对其技术的使用负责,并为遵守 ASR 伦理原则做出具体努力。
值得一提的是,作为 ASR 系统的设计者、维护者和消费者,人类将负责实施和执行这些原则——这是人机协同的又一个示例。
参考链接:
https://thegradient.pub/the-future-of-speech-recognition/
https://awni.github.io/speech-recognition/
作者 | Mig ü el Jett é
编译 | bluemin
编辑 | 陈彩娴
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
