
本文提出了 DreamSparse ,这是一个框架,使冻结的预训练扩散模型能够生成几何和身份一致的新视图图像。具体而言,DreamSparse包含了一个几何模块,旨在从稀疏视图中捕获3D特征作为3D先验。随后,引入空间引导模型来将这些3D特征图转换为用于生成过程的空间信息。然后,这些信息被用于指导预训练的扩散模型,使其能够在不调整的情况下生成几何一致的图像。利用预训练扩散模型中的强图像先验,DreamSparse能够为对象和场景级别的图像合成高质量的新视图,并推广到开放集图像。实验结果表明,其框架可以有效地从稀疏视图中合成新的视图图像,并且在训练和开集类别图像中都优于baseline。
来源:Arxiv
题目:DreamSparse: Escaping from Plato’s Cave with 2D Frozen Diffusion Model Given Sparse Views!
作者:Paul Yoo, Jiaxian Guo, Yutaka Matsuo, Shixiang Shane Gu
论文链接:https://arxiv.org/abs/2306.03414
内容整理:桂文煊
介绍
最近的工作开始探索稀疏视图新视图合成,特别是专注于从有限数量的具有已知相机姿势的输入图像(通常为2-3)生成新视图。其中一些试图在 NeRF 中引入额外的先验,例如深度信息,以增强对稀疏视图场景中 3D 结构的理解。然而,由于在少数视图设置中可用的信息有限,这些方法难以为未观察到的区域生成清晰的新图像。为了解决这个问题,SparseFusion 和 GenNVS 提出学习扩散模型作为图像合成器,用于推断高质量的新视图图像,并利用来自同一类别内其他图像的先验信息。然而,由于扩散模型仅在单个类别中进行训练,因此它在生成看不见的类别中的对象时面临困难,并且需要对每个对象进行进一步的提炼,这使得它仍然不切实际。
在本文中,我们研究了利用预训练的扩散模型(如 Stable Diffusion)中的 2D 图像先验进行可推广的新视图合成,而无需基于稀疏视图进行进一步的每对象训练。然而,由于预先训练的扩散模型不是为 3D 结构设计的,直接应用它们可能会导致几何和纹理不一致的图像,从而损害生成对象的身份的一致性。为了解决这个问题,本文引入了 DreamSparse ,这是一个旨在利用 2D 图像的框架,使用几个视图合成新的视图图像。为了将 3D 信息注入预先训练的扩散模型中,并使其能够合成具有一致几何形状和纹理的图像,本文最初采用几何模块作为 3D 几何先验,其灵感来自先前基于几何的工作,其能够聚集多视图上下文图像上的特征图并且学习推断用于新视图图像合成的 3D 特征。这种 3D 先验允许从以前看不见的视点渲染估计,同时保持精确的几何结构。
本文贡献与创新点
由于冻结的预训练扩散模型具有强大的图像合成能力,本文方法提供了几个好处:1)在没有额外训练的情况下推断物体的看不见区域的能力,因为预训练的扩散模型已经具有从大规模图像文本数据集中学习的强大图像先验。2) 强大的泛化能力,允许使用预训练的扩散模型中的强图像先验生成各种类别的图像,甚至在野生图像中生成图像。3) 能够合成高质量甚至场景级别的图像,而无需对每个对象进行额外的优化。4) 由于我们不修改参数或替换预先训练的文本到图像扩散模型的文本嵌入,因此保留了预先存在的模型的文本控制能力。这允许我们通过文本控制来改变合成的新颖视图图像的风格、纹理。
本文的创新点主要如下:
1、感知:用一种3D Geometry Module来聚合3D特征
2、guidance:提出了一种spatial guidance来使用聚合特征引导扩散模型,保证几何一致性
3、identity:提出了一种 noise perturbation method,保证identity一致性
方法
pipeline
本文的 pipeline 如图1所示。其主要可分为两个阶段:第一阶段中,利用 3D 几何模块来估计3D结构并从上下文视图聚合特征;在第二个阶段,利用以几何特征为条件的预先训练的 2D 扩散模型来学习空间引导模型,该空间引导模型引导扩散过程以精确合成底层对象。
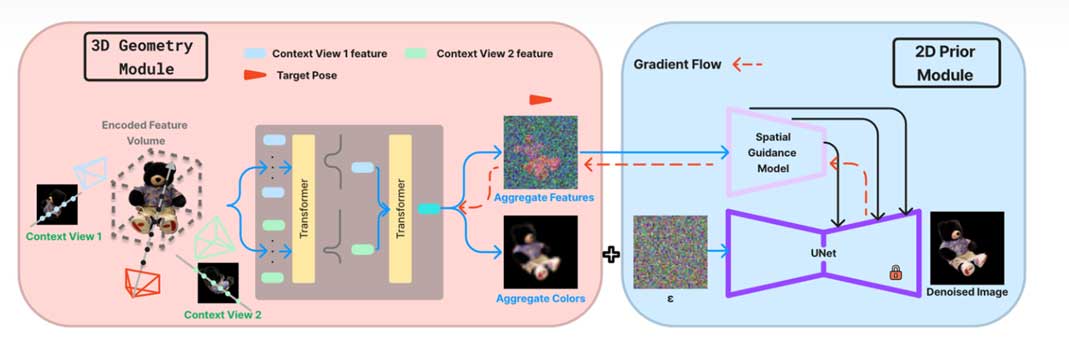

训练3D Geometry Module
为了将 3D 感知注入 2D 扩散模型,本文提出了一种几何模型来提取 2D 扩散模型的具有几何信息的 3D 特征。为了获得几何基础,该过程首先从π目标投射查询射线,并沿射线对均匀间隔的点进行采样。对于每个 3D 点,本文的目标是学习密度加权,以计算沿查询射线的特征的加权线性组合。随后,这种每射线特征在多个上下文图像中进行聚合,从而对我们要重建的 3D 结构产生统一的视角。最后,通过从目标视图进行光线投射来渲染 π 目标处的特征图。接下来,我们将介绍此模型的详细信息。具体做法是:对于单张图像逐点密度加权,利用 ResNet 主干提取语义特征并且 reshape 成 4 维体积表示,双线性采样对齐空间维度,三线性插值拼接特征向量,线性投影层加权;上下文图像特征聚合就是对每条查询射线 target,计算每个相应上下文图像的相应射线特征,然后聚合。具体算式如下。
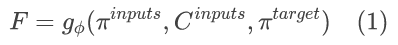
为了增强几何一致性,直接从变换器输出中获得聚合权重,并线性组合从上下文图像中提取的RGB颜色值,以在查询视图中呈现粗略的颜色估计E。具体算式如下。
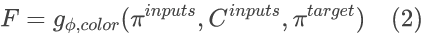
最终的损失函数为:
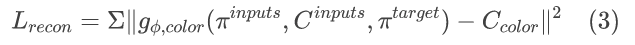
为 spatial guidance训练 controlnet
由于3D特征F和预训练的扩散模型的输入之间的模态间隙,3D特征不能直接用作预训练的散射模型的输入。为了利用3D特征中的3D信息,提出了空间引导模块,将3D特征转换为引导,以纠正在扩散过程中形成细粒度空间信息的空间特征(通常是第4层之后的特征图)。为了从3D特征中获得这种指导,本文在ControlNet之后构建了空间指导模块,该模块训练所有编码器块的单独副本以及来自Stable Diffusion的U-Net的中间块,其中1×1卷积层在每个块之间初始化为零。其具体算式如下:
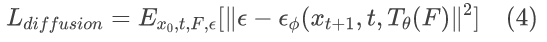

noise perturbation method
空间引导模块本身能够引导预先训练的扩散模型合成具有一致几何形状的新视图图像。但它仍然不能总是合成与上下文视图具有相同身份的图像。为了缓解这个问题,本文将噪声扰动添加到来自几何模型的新视图估计E中,并使用预先训练的扩散模型(例如Stable Diffusion)对结果进行去噪,以便它可以利用来自估计的同一信息。
实验结果
本文将该框架和baseline算法进行多方位比较,结果表明优于其他baseline方法。



总结
本文的gemometry感知和引导的方法值得学习,但其仍具有一定程度的限制:3D几何模块难以生成复杂的场景,尤其是那些具有非标准几何或复杂细节的场景。这是由于几何模块的容量有限,数据有限,其需要引入更强的几何主干,并在更大的数据集上进行训练。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。