

研究意义
指代视频目标分割是指从一个视频序列中分割出由一段文字语言所描述的目标对象。这种多模态任务为人机交互提供了一个更加自然和友好的方式,是研究跨模态视频分割大模型的基础性技术,也是实现 “通用人工智能” 的关键技术之一。
然而当前的方法为了减少模型的计算消耗,均没有考虑对视频序列的帧间一致性进行建模,导致最终的目标预测掩码在时空一致性上存在缺陷。
本文工作
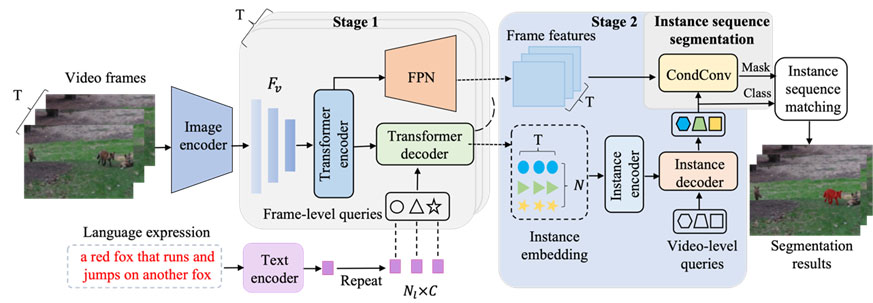
为了解决上述问题,本文基于多模态Transformer架构提出了时空层级查询策略,分两级逐步进行目标的时空表征学习。
在第一阶段,我们提出帧级空间信息提取模块,使用语言特征作为目标查询嵌入,独立地和视频序列中的每一帧进行信息交互,生成包含目标空间信息的低维度实例嵌入;
在第二阶段,提出时空信息聚合模块,在第一阶段生成的低维度实例嵌入上学习一个具有时空表征信息的视频级实例嵌入,从而实现对目标的时空一致性建模和时空表征学习。
由于采用了分级机制和降维思想,使得模型即学习到目标的时空表征,又显著减少了模型的计算负担,提升了模型的运行效率。
本文的创新点如下:
(1) 提出了一种新颖的基于时空层级查询的指代视频目标分割算法STHQ,解决了当前该领域方法缺乏目标时空一致性建模和时空表征学习不足等问题。
(2) 提出了两级查询机制,通过分级和降维的思想,以更加高效的形式构建了先空间后时空的目标时空表征学习体系。
实验结果
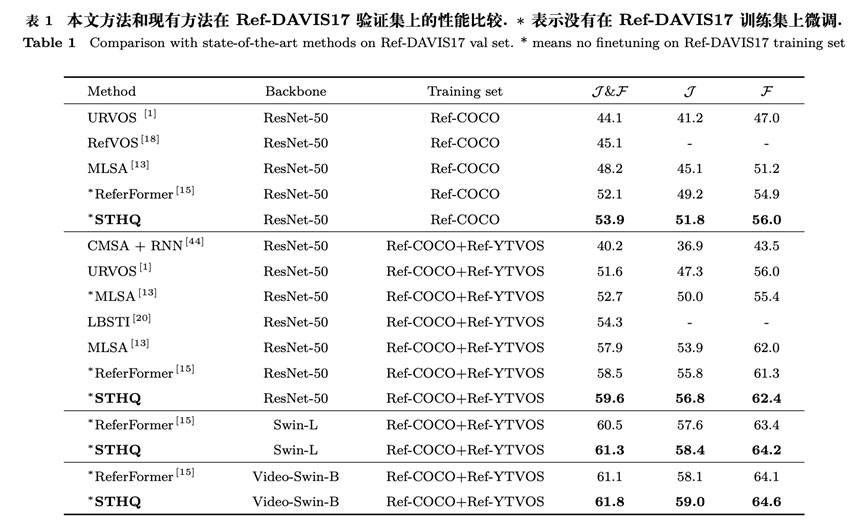
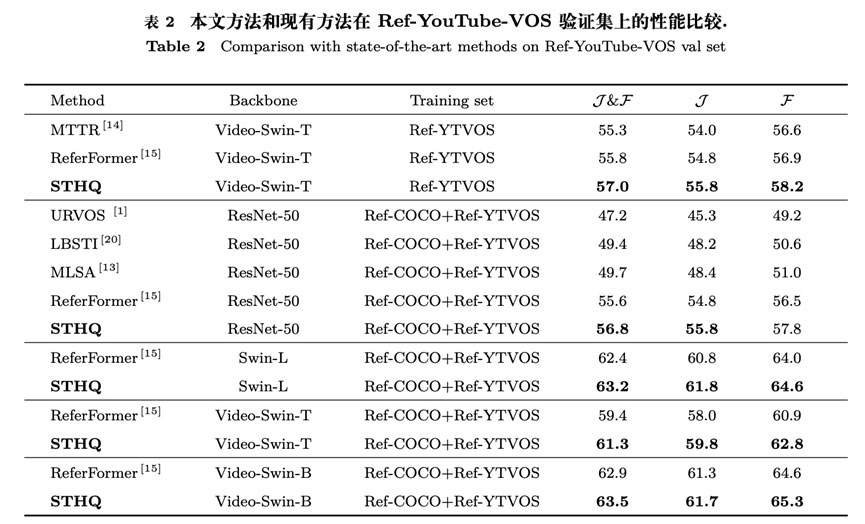
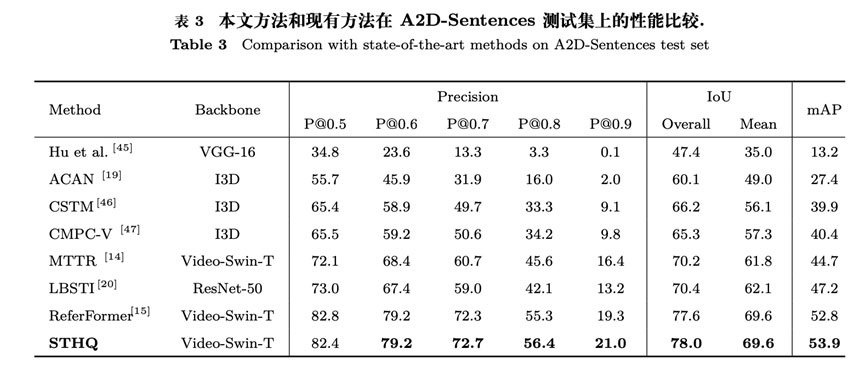
本文提出的STHQ方法在三个基准数据集上和当前的先进方法进行了对比,实验结果表明本文提出的算法超越了现有方法,实现了最佳性能,证明了算法的有效性和先进性。
文章信息
兰猛,张乐飞,杜博,张良培. 基于时空层级查询的指代视频目标分割. 中国科学: 信息科学, doi: 10.1360/SSI-2023-0030
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
