
2021年,国家广电总局发布《广播电视和网络视听“十四五”科技发展规划》,规划中提到,要加快推进制播体系技术升级,推动虚拟主播广泛应用于新闻播报、天气预报、综艺科教等节目生产,创新节目形态,提高制播效率和智能化水平,增加个性化和趣味性。
随着虚拟技术和5G逐渐普及、应用,VR、AI等虚拟技术已经被引入各大媒体,在这些技术推动跟加持之下,AI虚拟主播已经广泛地应用于各类播报场景,未来,各种报道的内容形态和表现形式将面临全面升级。视听新媒体中心作为总台移动端新闻阵地,积极响应总局要求,特设计制定了本系统以推动制播体系的技术升级等。
本文作者:
杨继红,姜华,刘银颢。第一作者简介:杨继红(1969—),女,中央广播电视总台高级编辑,博士研究生。参与创建中央广播电视总台5G新媒体旗舰平台“央视频”,作为总策划,开创出“两神山建医院慢直播——见证中国速度”“多语种国庆大阅兵4K直播电影”等全新内容形态,精心打造出“云招聘——央企民企稳就业国聘行动”“云守望 大武汉——从封城到开城全时段大直播”等项目。
中央广播电视总台视听新媒体中心
本文为论文精要,原文刊发于《广播与电视技术》2023年第7期。
NO.1 建设目标
首先明确虚拟人的形象需求,基于现有的虚拟人形象或者进行原画设计,通过相应的技术合成虚拟人的3D形象,虚拟人形象最高支持4K分辨率,同时为虚拟人提供个性化发型、衣服款式、衣服材质、衣服图案及颜色、领带、头饰、眼镜、戒指等外型要素。
打造虚拟人内容生产平台,实现负责生产虚拟人视频,平台具备 TTS 的驱动能力,能够把虚拟人、虚拟背景/绿幕等节目元素,由人工调整控制,就能生产出所需的虚拟人视频,并且还支持多人登录使用。
NO.2 需求分析
2.1 业务需求
2.1.1 虚拟人
以总台真实主持人为原型,通过对真人的影像数字化扫描,创建出跟真人1:1复制的虚拟人模型。通过对真人的动作和表情的深度学习后,让虚拟人模型完成学习训练,使模型具备根据计算机指令要求进行动作和做表情的能力。根据真人的声音和播报习惯,为虚拟人训练一套本人声音复刻的声音库。
2.1.2 内容生产平台
内容生产平台负责生产虚拟人视频,平台具备 TTS 的驱动能力,能够实现虚拟人、虚拟背景/绿幕等节目元素,同时还可以根据需求调节声音、语速、动画、字幕等。虚拟人驱动平台具备基础的节目生产能力,并能够在特定节目期间生产出一档专题节目。最终实现节目的生产更加智能化,具备更强大的内容生产能力,具有更丰富的节目素材资源。
2.2 性能需求
虚拟人生产力平台:支持 20 人同时在线,10 人并发操作。页面请求的响应时间不超过3s。
平台虚拟人渲染服务:支持 4K 视频渲染合成,渲染时间比为1:5,未来可以根据需求,通过扩容硬件提升至1:3。
系统有效工作时间:≥99.9%。
备份性能:备份时不能影响业务系统正常运行,备份数据流量大于 100MB/s。
恢复性能:根据数据备份大小,数据库恢复时间要小于备份数据时间。
2.3 技术需求
2.3.1 建模技术
利用SuperCapture 重光照及脸部 PBR材质扫描建模设备可以高效地采集、处理、生成毛孔级的人脸 3D 模型,并通过软件算法直接获得基于物理的渲染材质和贴图。设备可以高效和自动化地采集和生产高精度人脸数字资产,一次性进行人脸建模和材质生成,为超写实数字人资产的建立提供高质量的数据资产并节省大量工作时间,大幅提高输出效率。数据应用于所有支持 PBR材质的渲染引擎中,如 3DMax、Unity、UE4 等。该技术被广泛地用于好莱坞各大影片的数字演员建模制作中。通过物理光照模型,定量化地反映真实人物的脸部细节和皮肤光照特征信息,使数字演员在影视、游戏画面中的呈现可以达到更加真实的效果。
2.3.2 虚拟人动作定制绑定技术
虚拟人驱动基于传统动画制作的骨骼蒙皮绑定技术进行AI控制,骨骼动画是模型动画的一种(另外一种是顶点动画),包含了骨骼和蒙皮。模型是由mesh组成的,一段段骨骼之间相互连接组成骨架(连接处称之为关节),通过改变骨骼的朝向和位置来生成动画。蒙皮是指把Mesh的顶点附着在骨骼上,并且每个顶点可以被多个骨骼控制。
2.3.3 语音动画合成(STA)技术
系统将用户输入的文本或者是语音,通过网络实时传输到云端,云端接收到以后首先对输入的素材进行整理。如果是语音,系统提供语音识别技术,对语音转文字,然后将最后的文本内容输入STA中。
STA首先采用ETTS技术将文字合成为有感情的语音,或者是调用第三方TTS接口,对音频进行处理,实现语音对虚拟人的口型、唇形以及面部表情、躯体的简单驱动。这种驱动方式需要先将口型、唇形、面部表情、躯体动作等动作列出来,比如人脸的6个基本动作(眯眼与凝视、扬眉与皱眉、点头与摇头),与语音进行合成训练,当碰到某一种语音音调类型时,驱动虚拟人做一些动作、表情等。播报流程及语音交互流程如图1、图2所示。
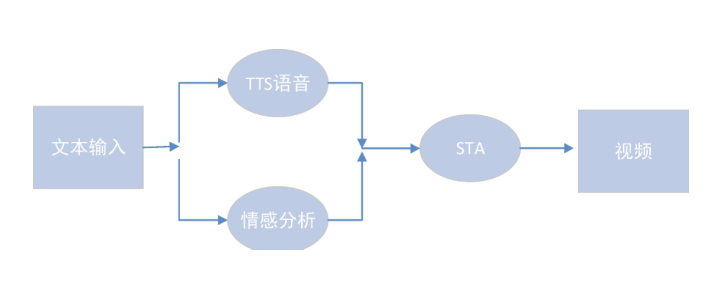
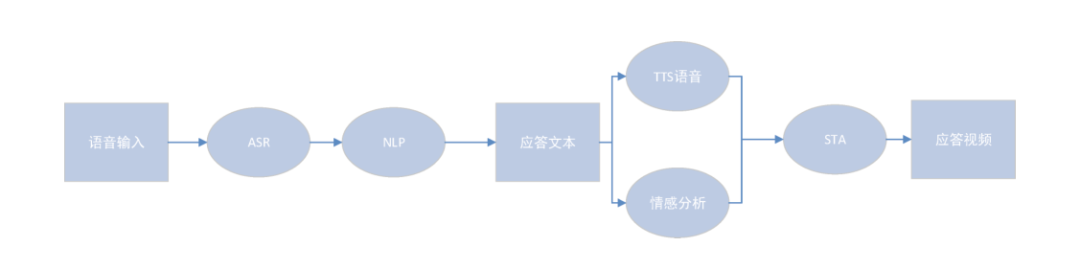
NO.3 总体设计
3.1 运行环境
支持主流 PC 浏览器使用,并根据业务需求提供对应能力的 APi 接口来满足更多平台对生产力平台能力的调用。
3.2 易用性
系统用户界面友好,操作页面应满足个性化设置,功能模块可根据用户角色不同、用户工作任务不同而实现灵活配置。
系统使用操作简便。通过提供下拉菜单、弹出页面等多种展现方式,减少用户操作。页面跳转过程中能够保存页面信息。
3.3 可靠性
系统具备有效的备份措施,保证系统(或数据)损坏(或丢失)后,能够正常地恢复。
系统有一定的容错机制,对于人为操作错误和数据录入错误,提供完善的处理方案;对于系统内部的意外运行错误,提供相应的处理机制,保证系统不异常退出、死机、崩溃;此外,系统有完备的安全措施与容灾备份的处理功能。
需通过对接口建立良好的安全监控机制,确保系统的稳定、健壮、可靠。
必须提供良好的数据安全可靠性策略,采用多种安全可靠的技术手段等,确保系统及数据的安全与可靠。
系统运行方面,提供异常监控机制,随时监控系统的运行状态。系统应记录运行日志。具备有效的错误诊断和恢复机制,避免系统误操作而导致系统崩溃。当系统发生故障时,应及时给出明确的故障信息,不应产生垃圾数据或错误数据。
系统具备 7×24 小时连续服务的能力。系统在连续正常负荷运行过程中,不发生系统响应性能下降、资源占用显著增加等现象。
3.4 可扩展性
要求以微服务架构为系统架构设计风格,减少单体系统的耦合。支持项目发起方对各系统进行功能拓展,支持分布式快速部署新的服务节点,支持新功能模块以微服务方式加入整个系统,方便、快捷地应对业务的快速发展。
3.5 易维护性
要求平台提供统一的访问接口和扩展接口,用户只需要进行简单的界面操作,即可进行复杂的任务分配和监管。
系统参数化配置层面:系统要求提供灵活的业务参数配置功能,能够支持未来业务数据平台平滑演进的要求。
系统日志层面:系统采用的基础软件能够记录系统级操作日志,支撑系统监控管理软件对系统 log 的监测。
应用功能的升级维护层面:应用功能采用 B/S 软件架构方式,采用基于组件的应用逻辑结构,支持不间断业务的升级与维护。
3.6 兼容性
界面设计要求使用成熟的HTML与JS技术,能够自适应屏幕。能够兼容主流浏览器。
3.7 安全性
要求根据信息安全等级保护的要求进行安全设计,并配合项目发起方完成等保测评。在主机、网络、应用、数据等方面均应满足等级保护对安全的要求,无论是用户、程序还是系统均应在可认证的基础上进行可控制的授权访问。在获得用户账号合法性确认基础上,应提供基于角色/权限组/个人的授权管理以及应用程序功能模块对用户权限的正确识别和反应。
3.8 合法性
要求所用所有软件和中间件均合法取得,并且严格遵守相关的协议和相关通用公共授权协议。
3.9 保密要求
平台系统中的所有数据,包括外部导入数据、数据平台自有生成的数据以及数据计算的算法模型均属于项目发起方的资产,所有接触算法模型及所有数据源的工作人员均需遵守数据保密协议。
NO.4 系统架构设计
虚拟人系统采用相关技术基于现有成熟的NLP、CG模型、图像技术和知识对话等能力,并对这些技术进行融合运用,开发出虚拟人的模型管理模块、直播对话辅助系统、相关SDK与API模块。在此基础上完成了AI虚拟人系统、直播虚拟人系统、IP形象定制、SDK/API接口等各大业务模块。系统架构如图3所示。
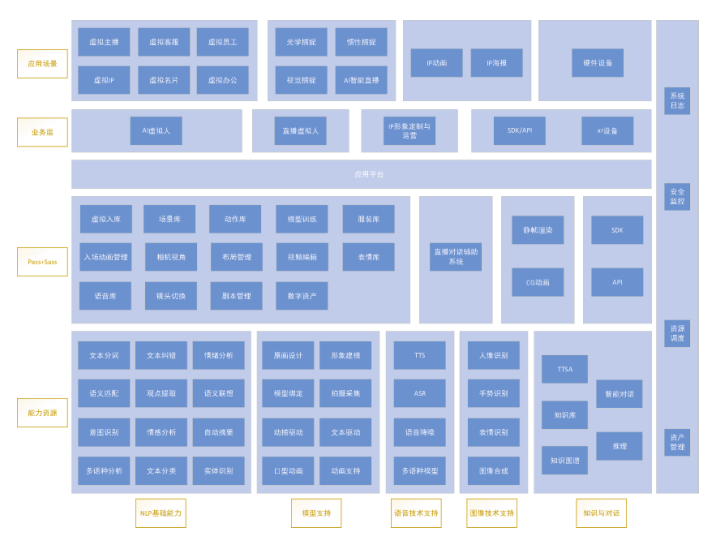
4.1 NLP模块
NLP基础能力模块是整个虚拟人的核心底层,虚拟人只有结合这些NLP能力,才能更加智能。NLP基础模块包括情绪分析、情感分析、语义匹配、观点提取、语义联想、意图识别、自动摘要、多语种分析、文本分类、文本分词、文本纠错、实体识别等模块。
4.2 模型支持
模型支持模块是虚拟人表现方面的基础,只有具备更精细度的模型支持,虚拟人的表现力才更加丰富。模型支持主要包括原画设计、形象建模、模型绑定、拍摄采集、动捕驱动、文本驱动、口型动画、动画支持等。完整的虚拟人从原画设计开始,再到模型建模、绑定、驱动。AI虚拟人则主要通过文本驱动,而部分用于直播或者其他非AI场景的虚拟人则主要通过动捕驱动或者动画支持。
4.3 语音技术支持
语音技术支持模块包括TTS、ASR、语音降噪、多语种模型等,虚拟人的语音交互离不开语音的支持。TTS主要是对NLP分析过的文本进行语音的表达。ASR则主要是用于对交流者的语音进行自动解析。语音降噪主要是为了应对复杂环境,不可能所有场景的语音都是很清晰的,所以语音分析之前需要进行降噪处理,提高语音识别的准确度。
4.4 图像支持
图像支持模块主要包括人像识别、手势识别、表情识别、图像合成等,图像支持模块主要用于摄像头驱动的虚拟人,摄像头驱动的虚拟人可以更好地适应各种虚拟人应用场景;人像识别用于对中之人的人像识别;手势识别则是对中之人的手势、动作进行识别;表情识别主要用于对中之人的面部表情进行捕捉,从而展示在虚拟人的面部;图像合成主要是对采集到的中之人数据进行虚拟人的驱动,虚拟人本质上是3D模型图像,所以图像合成是虚拟人展现的根本技术。
4.5 知识与对话
知识与对话模块主要包括TTSA、知识库、知识图谱、智能对话、语义推理,这个模块主要是对NLP能力的运用,使虚拟人的对话更加智能。同时系统在整体业务逻辑上也有全局的系统日志、安全监控、资源调度资产管理能力,使系统的运行更加稳定。
NO.5 功能设计
5.1 虚拟人定制
虚拟人定制制作流程如图4所示。
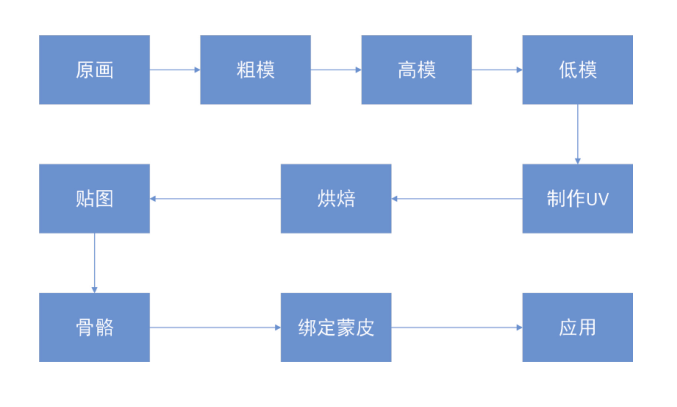
5.1.1 虚拟人分类
根据目前虚拟人的分类,可以分为真身复刻虚拟人、写实类虚拟人以及卡通形象虚拟人,其中写实类虚拟人分为超写实、高精度、中精度、低精度这4类。虚拟人分类如图5所示。

5.1.2 虚拟人制作
1. 制作概述
虚拟人制作,包含虚拟人原画设计、虚拟人建模、发型材质设计、衣服材质设计、表情库设计、表情绑定、口型设计、口型绑定、动作库设计、骨骼绑定、动作绑定和衣服绑定骨骼。
2. 虚拟人定制
根据定制人的风格来设计外形建模采集方案,包括但不限于发型、衣服款式、衣服材质、衣服图案及颜色、领带、头饰、眼镜、戒指等外型要素,最后形成相应的真人数字人。
3. 虚拟人声音
基于最新语音合成深度学习技术,只需要用户提供少量的干净录音数据,机器就可以快速学习并生成可使用的语音合成音库,为用户的后续产品提供专属的、独一无二的合成声音。
用户可根据自己的产品形态和对声音风格的需求,进行专属定制,确保客户定制音库的专属性,提升产品辨识度和行业差异性。
4. 虚拟人动作表情
根据定制人物日常习惯,提取出不少于两个有个人特色的肢体动作,通过机器深度学习,还原真人说话时的动作和表情。且确保播报时的肢体动作和表情自然。
5. 绑定
模型完成以后的第二个环节就需要由动画绑定师对角色模型进行骨骼驱动和动画,这里同样要求动画师具有一定的人体解剖知识,对人体的面部表情肌肉和一些肢体语言运动规律和节奏感具有丰富的经验,这样才能赋予虚拟数字人生命。还包括要会运用很多技术点,比如蒙皮、动作捕捉、表情混合、毛发、渲染、场景灯光,以及镜头语言的合理运用等等。最后就是语音表达,让虚拟人会说话,会交互。
6. 驱动
内容输入方式包括文本输入和语音输入。如果是文本输入,需要在客户端将文本内容通过网络传入云端,在云端运用语音合成技术(ETTS),或者接入第三方TTS能力,将用户输入的文本合成为语音,实现虚拟人的语音播报。其中ETTS是有感情的TTS,一般的TTS比较机械化,而ETTS则是在TTS过程中,保留类似真人的音调和韵律,使虚拟人的语音听起来更有感情。
语音输入则首先需要系统运用ASR语音识别技术,将语音转换成计算机方便计算的文本,然后传到云端,运用ETTS文本合成语音技术和STA语音动画合成技术,通过语音驱动虚拟人进行语音播报,实现虚拟人的唇形、面部、身体的简单驱动。
5.2 内容生产力平台
5.2.1 基础功能
用户可以选择布局、人、声音配置、语速和背景等进行基础设置。
5.2.2 AI驱动内容合成
AI驱动内容合成是一款集节目数据分析管理、AI素材、AI相似度对比、大数据管理、内容合成、数据可视化为一体的虚拟人生产力智能系统模块,能够帮助企业解决智能化内容生产、账号运营、低成本精准引流、业务场景、服务场景、服务效率等问题的AI内容生产力平台。
5.2.3专业词库
词库维护,指用户可对自主内容检查和合规检测模块的关键词进行补充,其中,可对内容检查模块的淫秽色情、暴恐违禁、政治敏感、低俗辱骂、专业术语、行业词汇等6块内容进行关键词补充;可对合规检测模块的新闻禁用和广告禁用内容进行补充。
5.2.4高清虚拟视频
驱动虚拟人进行文本内容播报,支持选择人(可选择1个或2个)、选择人服装、选择人声音、选择背景或场景、创作播报脚本、在线实时生成视频和导出视频。
在生成视频过程中如果任务增多,系统会默认进行任务队列管理模式,对任务文件处理以及相应的数据进行传输,最后形成4K高精度的视频输出。
5.2.5视频剪辑
平台支持用户对素材进行剪辑,支持音频、视频、图片等素材,可对素材进行音量大小、音视频倍速、淡入淡出、位置大小、视频调色、特效等方面的调整。可支持用户对素材进行切割、裁剪、删除等操作,支持用户进行撤销、恢复等操作。可以对视频添加字幕、贴纸、滤镜、转场、特效等操作,完成以后对视频进行导出。
5.2.6系统设置
可自定义设置系统logo,查看账号信息、生成虚拟视频可用时长、系统到期时间等。
NO.6 结束语
随着AI在广电行业的深入普及,对图像的深度学习成为最基础的AI能力,并广泛用于各行业的方方面面。作为技术研究者,我们需要在持续发展的技术道路上不断探索,不断试错,对我国广电行业的科技进步不断研究,持续攻关,发挥好总台技术创新者、引领者和普及者的重要作用。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
