
最近出现的生成模型,是一种基于受过训练数据而能够生成新文字或图像的计算工具,为创意产业开启了有趣的新可能性。例如,它们能够让艺术家和数字内容创作者轻松地创作出融合不同图像或视频元素的逼真的媒体内容。
在最近的技术进展的启发下,斯坦福大学、加州大学伯克利分校和Adobe研究人员开发出了一个新模型,可以真实地将特定的人插入到不同的场景中,例如表现他们在健身房锻炼、在海滩上观看日落等。
他们提出的架构是基于一类称为扩散模型的生成模型,在预先发布在arXiv服务器上的一篇论文中介绍,并计划于今年6月在加拿大温哥华举行的计算机视觉和模式识别(CVPR)会议上进行展示。
视觉系统天生具有推断环境或场景中可能发生的行动或互动的能力,这个概念被称为’可获得性’。
这是视觉、心理与认知科学领域内广泛研究的主题。在过去二十年中,发展的可行性感知计算模型常常受到其方法和数据集的固有限制的限制。然而,大规模生成模型所展现的令人印象深刻的现实主义显示了进步的有望途径。基于这些见解,我们旨在创建一个模型,能够显式地推断出这些可行性感知。
Kulal及其同事的研究的主要目标是将生成模型应用于可供知觉的任务,以期获得更可靠和现实的结果。在他们最近的论文中,他们特别关注如何将一个人逼真地插入到给定的场景中的问题。

“我们的输入数据为一个人的图像和一个带有指定区域的场景图像,输出则是一个包含该人的真实场景图像,” Kulal解释道。”我们的大规模生成模型是在数百万个视频构成的数据集上训练出来的,具有更强的推广能力,可以适用于新颖的场景和人物。此外,我们的模型还具备一系列有趣的辅助功能,如人物幻象和虚拟试衣。”
Kulal和他的同事使用一种自我监督的训练方法,训练了一种扩散模型,这种生成模型可以将“噪音”转化为所需的图像。扩散模型的基本原理是通过“破坏”它们所训练的数据,向其中添加“噪音”,然后通过反转这个过程来恢复部分原始数据。
在训练过程中,研究人员创建的模型被提供了显示在给定场景中运动的人的视频,并随机选择了每个视频中的两个帧。第一个帧中的人被遮蔽,意味着人周围的像素区域被变成了灰色。
该模型随后尝试使用第二帧中相同的未掩蔽的个体作为条件信号,重建在这个掩蔽帧中的个体。随着时间的推移,该模型可以学习逼真地复制人类在特定场景中的外观。
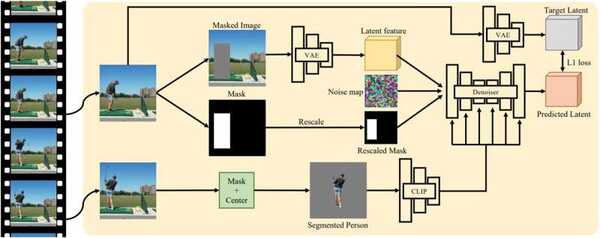
“我们的方法迫使模型从场景背景中推断出可能的姿势,重新调整人物的姿势并协调插入,” Kulal表示。”这种方法的一个关键因素是我们的数据集,由数百万个人类视频组成。由于规模大,与 Stable Diffusion 模型相似的架构,我们的模型对各种输入的推广效果非常好。”
研究人员在一系列的初步测试中评估了他们的生成模型,他们使用新的人和场景图片进行喂入,然后观察它是如何将这些人物放置在场景中的。结果发现,该模型表现出色,所生成的编辑图像看起来非常逼真。他们的模型所预测的便利性比过去引入的非生成模型更好,并且在更多样化的环境中有效。
Kulal表示:“我们非常兴奋地发现这种模型在广泛的场景和人物图像中的有效性,准确地识别多数情况下的适当能力。我们预计我们的发现将显著为感知能力和相关领域的未来研究做出贡献。在机器人研究中,识别潜在的交互机会至关重要,这方面的影响也是重大的。此外,我们的模型在创建逼真的媒体(如图像和视频)方面具有实际应用。”
在未来,Kulal和他的同事开发的模型可以集成在很多创意软件工具里,以增加它们图片编辑功能的广度,最终支持艺术家和媒体创作者的工作。它还可以添加到照片编辑智能手机应用程序中,使用户可以轻松而真实地将一个人插入照片中。
“这项工作为未来的研究提供了几个潜在的途径,”Kulal补充道。“我们考虑将更大的可控性纳入生成的姿势中,例如ControlNet等最新工作提供了相关的洞见。除了静态图像,我们还可以扩展这个系统,生成人在场景中运动的逼真视频。我们还对模型的效率感兴趣,是否可以使用更小更快速的模型达到相同的质量。最后,本文介绍的方法并不仅限于人类,我们可以将这种方法推广到所有物体。”
—煤油灯科技victorlamp.com编译整理—
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
