


近日,微软的研究人员推出了komos -1,这是一种多模态模型,据报道,它可以分析图像内容,解决视觉难题,执行视觉文本识别,通过视觉智商测试,并理解自然语言指令。研究人员认为,多模态人工智能(集成了文本、音频、图像和视频等不同模式的输入)是构建可在人类水平上执行一般任务的人工通用智能(AGI)的关键步骤。
研究人员在他们的学术论文《语言不是你所需要的全部:将感知与语言模型对齐》《Language Is Not All You Need: Aligning Perception with Language Models.》中写道:“作为智能的基本部分,多模态感知是实现人工通用智能的必要条件,就知识获取和现实世界的基础而言。”
来自Kosmos-1论文的可视化示例展示了该模型分析图像并回答有关图像的问题,从图像中读取文本,为图像编写说明,并进行了22 – 26%的准确性的视觉智商测试(下文将详细介绍)。

当媒体充斥着关于大型语言模型(LLM)的新闻时,一些人工智能专家指出,多模态人工智能是通往通用人工智能的潜在途径,这种假设的技术表面上能够取代人类完成任何智力任务(以及任何智力工作)。AGI是OpenAI的既定目标,OpenAI是微软在人工智能领域的关键业务合作伙伴。
在这种情况下,Kosmos-1似乎是一个纯粹的微软项目,没有OpenAI的参与。研究人员称他们的创造为“多模态大语言模型”(MLLM),因为它的根源在于自然语言处理,就像纯文本的LLM,如ChatGPT。它表明:为了让Kosmos-1接受图像输入,研究人员必须首先将图像翻译成LLM可以理解的一系列特殊符号(基本上是文本),Kosmos-1论文对此进行了更详细的描述:
- 对于输入格式,我们将输入平展为带有特殊标记的序列。具体地说,我们使用和来表示序列的开始和结束。特殊标记和指示编码图像嵌入的开始和结束,例如,“document </g>”是一个文本输入,而“<s>段落<image>图像嵌入<段落</s> “是一个交错的图像-文本输入。
- ... 嵌入模块用于将文本标记和其他输入形式编码为向量。然后将嵌入数据输入解码器。对于输入令牌,我们使用一个查找表将它们映射到嵌入。对于连续信号(例如图像和音频)的模态,也可以将输入表示为离散的代码,然后将它们视为“外语”。
微软使用来自网络的数据训练Kosmos-1,包括来自the Pile(一个800GB的英文文本资源)和Common Crawl的摘录。训练结束后,他们在几项测试中评估了Kosmos-1的能力,包括语言理解、语言生成、光学字符识别-无文本分类、图像字幕、视觉问题回答、网页问题回答和零镜头图像分类。据微软称,在许多测试中,Kosmos-1的表现超过了目前最先进的模型。
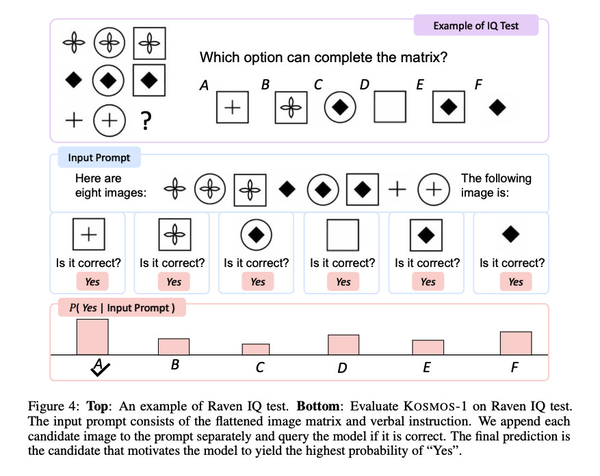
特别有趣的是Kosmos-1在Raven渐进推理中的表现,该测试通过呈现一系列形状并要求测试者完成该序列来测量视觉智商。为了测试Kosmos-1,研究人员给它填写了一个测试,一次一个,每个选项都完成了,并询问答案是否正确。Kosmos-1只能在22%的时间内正确回答Raven测试中的一个问题(26%的时间经过微调)。这绝不是一个扣篮,方法上的错误可能会影响结果,但Kosmos-1在Raven智商测试中击败了随机概率(17%)。
尽管Kosmos-1代表了多模态领域的早期步骤(其他人也在追求这种方法),但很容易想象,未来的优化可能会带来更显著的结果,允许AI模型感知任何形式的媒体并对其采取行动,这将极大地增强人工助手的能力。在未来,研究人员表示,他们希望扩大Kosmos-1的模型规模,并整合语音功能。
微软表示,它计划让开发者可以使用Kosmos-1,尽管在这篇文章发表时,文章引用的GitHub页面上没有明显的kosmos特定代码。
参考链接:https://arstechnica.com/information-technology/2023/03/microsoft-unveils-kosmos-1-an-ai-language-model-with-visual-perception-abilities/
—煤油灯科技victorlamp.com编译整理—
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。