
AWS 今天推出了用于PArallel的Palace,一种用于全波电磁模拟的并行有限元代码。Palace被AWS量子计算中心用于执行复杂电磁模型的大规模3D模拟,并实现量子计算硬件的设计。
为什么建造Palace?
计算建模通常需要科学家和工程师在模型保真度、时钟时间和计算资源之间做出妥协。基于云的 HPC 的最新进展已将超级计算机的强大功能交到世界各地的科学家和工程师手中,现在用户希望利用它来加速现有的模拟工作负载并模拟更大、更复杂的模型。
Palace 使用科学计算社区的可扩展算法和实现,并支持计算基础设施的最新进展,以提供最先进的性能。在 AWS 上,这包括用于快速联网的Elastic Fabric Adapter (EFA)和使用定制英特尔处理器或AWS Graviton 处理器实现卓越性价比的HPC 优化的Amazon Elastic Compute Cloud (EC2)实例。Palace 等开源软件还允许用户在探索大型参数化设计空间时利用基于云的弹性 HPC 并行执行任意数量的模拟,不受专有软件许可模型的约束。
所以,AWS创建了 Palace ,因为虽然存在许多适用于计算物理学广泛应用的高性能开源工具,但很少有用于大规模并行、基于有限元的计算电磁学的开源解决方案。Palace 支持广泛的仿真类型:本征模式分析、频域和时域中的驱动仿真,以及用于集中参数提取的静电和静磁仿真。作为一个开源项目,它还可以由希望为工业相关问题添加新功能的开发人员完全扩展。MFEM 有限元离散化库使 Palace 的大部分内容成为可能,该库可实现高性能、可扩展的有限元研究和应用程序开发。
Palace 增加了支持基于云的数值模拟和 HPC 的开源软件生态系统,支持开发自定义解决方案和模拟服务的云基础设施,并为您提供比现有替代方案更多的选择。
Palace 的主要功能包括:
- 使用可选材料或辐射损耗(包括集总阻抗边界)的本征模计算。用于电路量化的能量参与比(EPR)和用于预测介电损耗的接口或批量参与比的自动后处理。
- 基于表面电流激励和集总或数值波口边界的频域驱动仿真。使用统一频率空间采样或自适应快速频率扫描算法进行宽带频率响应计算。
- 用于瞬态电磁分析的显式或完全隐式时域求解器。
- 通过静电和静磁问题公式提取集总电容和电感矩阵。
- 支持结构化和非结构化网格的各种网格文件格式,具有内置的统一或基于区域的并行网格细化。
- 借助MFEM 库,可支持任意高阶有限元空间和曲线网格。
- 用于求解线性方程组的可扩展算法,包括几何多重网格 (GMG)、并行稀疏直接求解器和代数多重网格 (AMG) 预调节器,可在从笔记本电脑到 HPC 系统的各种平台上实现快速性能。
量子硬件设计的电磁模拟实例
在这里,我们将展示两个示例应用程序,展示 Palace 的一些关键特性及其作为数值模拟工具的性能。对于所有呈现的应用程序,我们将基于云的 HPC 集群配置为在 Amazon Linux 2 操作系统上使用 GCC v11.3.0、OpenMPI v4.1.4 和 EFA v1.21.0 编译和运行 Palace。在每种情况下,我们都使用COMSOL Multiphysics进行几何准备和网格生成预处理,但 Palace 支持多种网格文件格式以适应不同的工作流程,包括那些使用完全开源软件的工作流程。
Transmon 量子比特和读出谐振器
第一个示例考虑了超导量子器件设计中遇到的一个常见问题:模拟单个 transmon 量子位耦合到读出谐振器,具有用于输入/输出的端接共面波导 (CPW) 传输线。超导金属层被建模为 c 面蓝宝石衬底顶部的无限薄的完美导电表面。
本征模式分析用于计算线性化传输和读出谐振器模式频率、衰减率以及相应的电场和磁场模式。考虑了两个有限元模型:一个具有 2.462 亿个自由度的精细模型,以及一个具有 1550 万个自由度的粗略模型,与精细模型相比计算频率相差 1%。在四面体网格上,在精细模型中使用三阶符合 H(curl) 的 Nédélec 元素以及在粗模型中使用类似的一阶元素对控制Maxwell方程进行离散化。图 1 显示了 transmon 模型的 3D 几何结构和用于模拟的网格视图。图 2 还显示了两个计算出的本征模式中每一个的磁场能量密度的可视化。
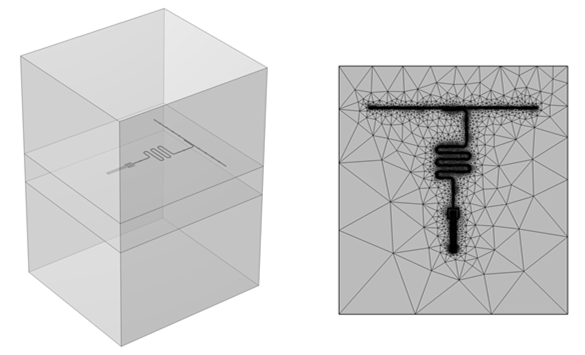
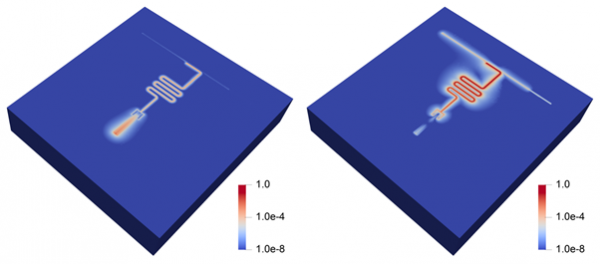
图 2:使用 ParaView 对磁场能量密度进行可视化,在整个计算域上按最大比例缩放,从模拟的线性化transmon本征模(左)和读出谐振器本征模(右)计算。
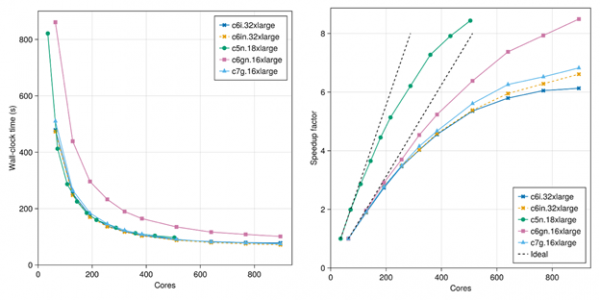
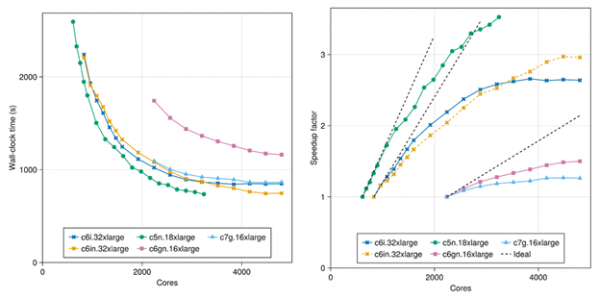
对于这两个模型,我们扩展了用于模拟的核心数量,以研究在使用各种EC2实例类型时,Palace在AWS上的可扩展性。图 3 绘制了粗略模型的模拟挂钟时间和计算的加速因子,而图 4 绘制了更高保真度精细模型的它们。我们观察到粗略模型和精细模型的模拟时间分别约为 1.5 分钟和 12 分钟,这是通过 EC2 的可扩展性实现的。另请注意,c7g.16xlarge 实例类型采用最新一代 AWS Graviton3 处理器,性能优于上一代 c6gn.16xlarge,通常与最新的基于 Intel 的实例类型的性能相匹配。
超导超材料波导
展示 Palace 功能和性能的第二个示例涉及基于集总元件微波谐振器链的超导超材料波导模拟。构建此模型是为了预测 Zhang 等人在《科学》杂志中提到的设备的传输特性。采用Palace的自适应快速扫频算法,在4 ~ 8 GHz的频率范围内,以1 MHz的分辨率进行驱动模拟,计算了该超材料的频率响应。
我们考虑从具有2.422亿个自由度的单个晶胞(参见下面的图5)开始增加复杂性的模型,并增加到具有14亿个自由度的21个晶胞。模拟此设备的复杂性来自大范围长度尺度的几何特征,相对于 2 cm 的整体模型长度,迹线宽度为 2 μm。用于模拟的 EC2 实例的数量随着超材料单元的数量而增加,以保持每个处理器的自由度数量不变。
图 5 显示了 1、4 和 21 个晶胞模拟案例的超材料波导几何结构。图 6 绘制了每个模拟案例的计算滤波器响应,其中我们看到频率响应随着晶胞重复次数的增加而变得更加复杂。使用自适应快速频率扫描算法计算的解决方案针对几个均匀采样的频率进行了检查,并且两种解决方案在整个频带上都显示出良好的一致性。
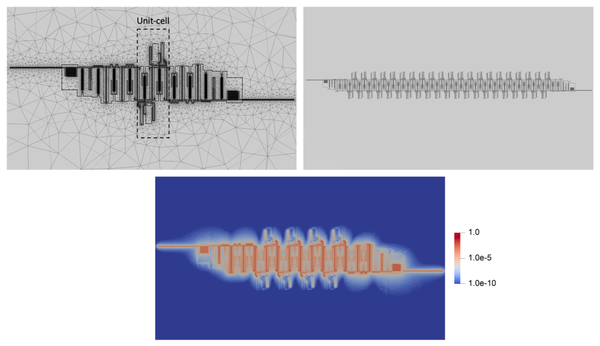
图 5:用于超材料波导仿真的 1、4 和 21 晶胞重复模型,两端均采用工程设计的锥度。4 个晶胞重复(底部)可视化电场能量密度,根据 Palace 在 6 GHz 下计算的解在整个计算域上按最大比例缩放的电场能量密度。
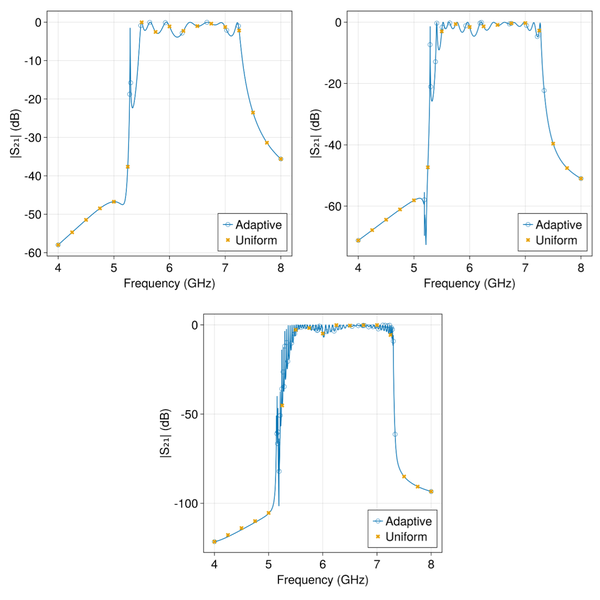
图 6: 4(左上)、8(右上)和 1 个晶胞重复模型在 4 至 8 GHz 范围内的模拟传输。空心圆圈表示 Palace 的自适应快速扫频算法使用的自动采样频率。在几个均匀间隔频率上计算频率响应的解也被绘制出来,以证明自适应快速扫频的准确性。
我们在图7中绘制了随着模型变得更加复杂,跨越来越多的核心运行模拟所需的时间。所有模型都在 c6gn.16xlarge 实例上模拟,最大案例使用 200 个实例或 12,800 个内核。当使用自适应快速频率扫描时,壁钟模拟时间更高,但这是因为均匀扫描仅在17个采样频率上提供频率响应,而快速自适应扫描的分辨率更高,使用4001个点。对于21晶胞重复,如果每个频率点顺序采样,则均匀频率扫描大约需要27天才能达到相同的精细1 MHz分辨率。
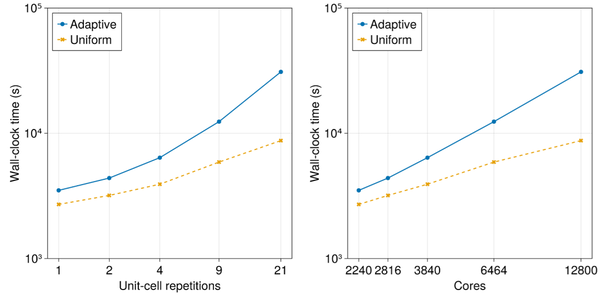
图 7:超材料波导示例的模拟挂钟时间随着晶胞重复次数和相应使用的内核数量的增加。
结论
随着模型复杂度的增加,模拟时间的增加,即使每个核心的自由度保持大致不变,这归因于为每个频率组装的线性方程组变得更加难以求解,收敛所需的线性求解器迭代次数更多。同样,自适应扫频需要更多的频率样本,因此需要更多的壁钟模拟时间,以保持随着模型中单元数量的增加指定的误差容限。
参考链接:https://aws.amazon.com/cn/blogs/quantum-computing/aws-releases-open-source-software-palace-for-cloud-based-electromagnetics-simulations-of-quantum-computing-hardware/
—煤油灯科技victorlamp.com翻译整理—
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
