
2022年,生成模型(Generative models)取得了巨大的进展。不仅可以从自然语言提示中生成逼真的 2D 图像,也在合成视频和 3D 形状生成方面有着不俗的表现。
虽然目前的生成模型可以生成静态的 3D 对象,但合成动态场景更加复杂。而且,由于目前缺少现成的 4D 模型集合(无论是有或没有文本注释),相比于 2D 图像和视频生成,由文本到 4D 的生成更加困难。
那么,如何基于简单的文本直接生成复杂的 3D 动态场景呢?
一种可能的方法是,从预先训练好的 2D 视频生成器开始,从生成的视频中提取 4D 重建。然而,从视频中重建可变形物体的形状是一项非常具有挑战性的工作。
近日,来自 Meta 的研究团队结合视频和 3D 生成模型的优点, 提出了一个新的文本到 4D(3D+时间)生成系统——MAV3D(Make-A-Video3D)。
据介绍,该方法使用4D 动态神经辐射场(NeRF),通过查询基于文本到视频(T2V)的扩散模型,对场景外观、密度和运动一致性进行了优化。
同时,由特定文本生成的动态视频可以从任何摄像机位置和角度观看,并且可以合成到任何 3D 环境中。

图|由MAV3D生成的样本。行表示时间的变化,列表示视点的变化。最后一列显示其相邻列的深度图像。(来源:该论文)
研究团队表示,MAV3D 是第一个基于文本描述生成 3D 动态场景的方法,可以为视频游戏、视觉效果或 AR/VR 生成动画 3D 资产。相关研究论文以“Text-To-4D Dynamic Scene Generation”为题,已发表在预印本网站 arXiv 上。
据论文描述,MAV3D 的实现不需要任何 3D 或 4D 数据,而且 T2V 模型也只是在文本-图像对和未标记的视频数据上训练的。
以往研究证明,仅仅使用视频生成器优化动态 NeRF 不会产生令人满意的结果。为了实现由文本到 4D 的目标,必须克服以下 3 个挑战:
- 找到一个端到端、高效且可学习的动态 3D 场景的有效表示;
- 有一个监督来源,因为没有可供学习的大规模(文本,4D)数据集。
- 需要在空间和时间上缩放输出的分辨率,因为 4D 输出域是内存密集型的和计算密集型的。
那么,由简单的文本描述到复杂的 3D 动态场景生成,具体是如何实现的呢?
首先,研究团队仅充分利用了三个纯空间平面(绿色),渲染单个图像,并使用 T2I 模型计算 SDS 损失。
然后,他们添加了额外的三个平面(橙色,初始化为零以实现平滑过渡),渲染完整的视频,并使用 T2V 模型计算 SDS-T 损失。
最后,即超分辨率微调(SRFT)阶段,他们额外渲染了高分辨率视频,并将其作为输入传递给超分辨率组件。
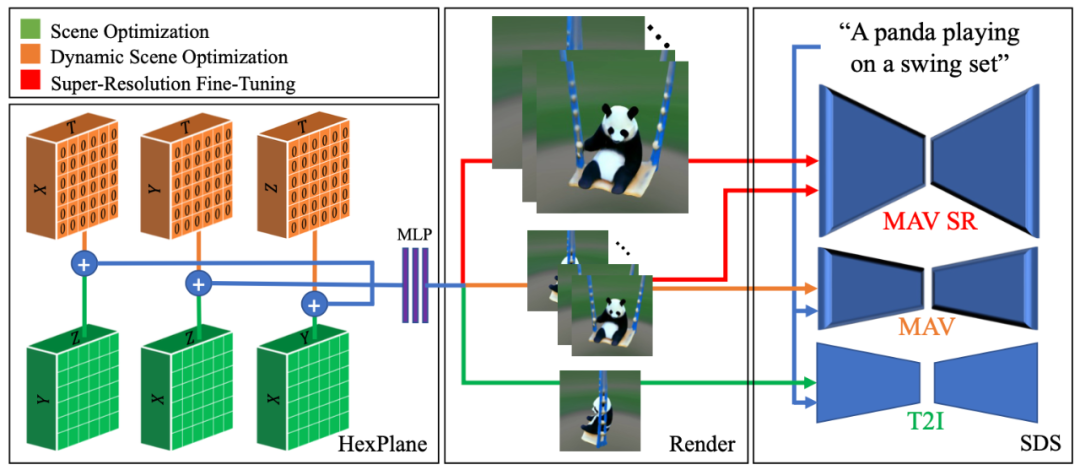
图|MAV3D 的实现路径(来源:该论文)
另外,MAV3D 也可以完成由图像到 4D 应用的转换。给定一个输入图像,通过提取它的 CLIP embedding,并以此来约束(condition)MAV3D。
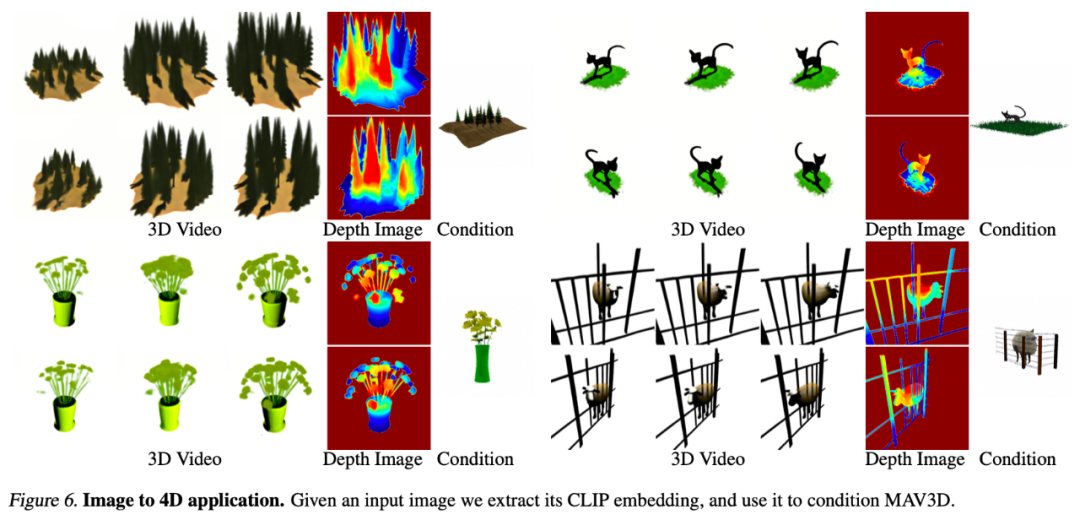
图|图像到4D应用。
然而,这一方法也存在一定的局限性。例如,在实时应用中,将动态 NeRF 转换为不相交网格序列的效率很低。研究团队认为,如果直接预测顶点的轨迹,或许可以改进。
此外,利用超分辨率信息已经提高了表示的质量,但对于更高细节的纹理还需要进一步改进。
最后,表示的质量取决于 T2V 模型从各种视图生成视频的能力。虽然使用依赖于视图的提示有助于缓解多面问题,但进一步控制视频生成器将是有帮助的。
参考链接
https://arxiv.org/abs/2301.11280
https://make-a-video3d.github.io/
本文来自微信公众号“学术头条”(ID:SciTouTiao),作者:学术头条,转载请注明出处。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
