
本文主要描述音视频同步原理,及常见的音视频同步方案,并以代码示例,展示如何以音频的播放时长为基准,将视频同步到音频上以实现视音频的同步播放。
1.音视频同步简单介绍
对于一个播放器,一般来说,其基本构成均可划分为以下几部分:
数据接收(网络/本地)->解复用->音视频解码->音视频同步->音视频输出。
基本框架如下图所示:
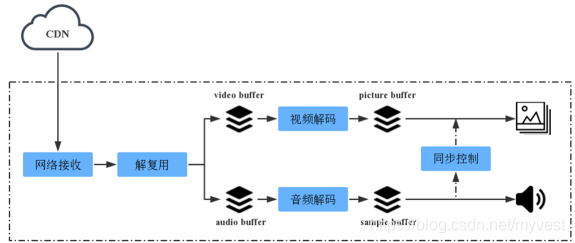
播放器基本框图
为什么需要音视频同步?
媒体数据经过解复用流程后,音频/视频解码便是独立的,也是独立播放的。而在音频流和视频流中,其播放速度都是有相关信息指定的:
- 视频:帧率,表示视频一秒显示的帧数。
- 音频:采样率,表示音频一秒播放的样本的个数。
在这里插入图片描述
- 一帧的播放时间,难以精准控制。音视频解码及渲染的耗时不同,可能造成每一帧输出有一点细微差距,长久累计,不同步便越来越明显。(例如受限于性能,42ms才能输出一帧)
- 音频输出是线性的,而视频输出可能是非线性,从而导致有偏差。
- 媒体流本身音视频有差距。(特别是TS实时流,音视频能播放的第一个帧起点不同)
所以,解决音视频同步问题,引入了时间戳:
首先选择一个参考时钟(要求参考时钟上的时间是线性递增的);
编码时依据参考时钟上的给每个音视频数据块都打上时间戳;
播放时,根据音视频时间戳及参考时钟,来调整播放。
所以,视频和音频的同步实际上是一个动态的过程,同步是暂时的,不同步则是常态。以参考时钟为标准,放快了就减慢播放速度;播放快了就加快播放的速度。
接下来,我们介绍媒体流中时间戳的概念。
2.DTS和PTS简介
2.1I/P/B帧
在介绍DTS/PTS之前,我们先了解I/P/B帧的概念。I/P/B帧本身和音视频同步关系不大,但理解其概念有助于我们了解DTS/PTS存在的意义。
视频本质上是由一帧帧画面组成,但实际应用过程中,每一帧画面会进行压缩(编码)处理,已达到减少空间占用的目的。
编码方式可以分为帧内编码和帧间编码。
内编码方式:
即只利用了单帧图像内的空间相关性,对冗余数据进行编码,达到压缩效果,而没有利用时间相关性,不使用运动补偿。所以单靠自己,便能完整解码出一帧画面。
帧间编码:
由于视频的特性,相邻的帧之间其实是很相似的,通常是运动矢量的变化。利用其时间相关性,可以通过参考帧运动矢量的变化来预测图像,并结合预测图像与原始图像的差分,便能解码出原始图像。所以,帧间编码需要依赖其他帧才能解码出一帧画面。
由于编码方式的不同,视频中的画面帧就分为了不同的类别,其中包括:I 帧、P 帧、B 帧。I 帧、P 帧、B 帧的区别在于:
- 「I 帧(Intra coded frames)」:I 帧图像采用帧I 帧使用帧内压缩,不使用运动补偿,由于 I 帧不依赖其它帧,可以独立解码。I 帧图像的压缩倍数相对较低,周期性出现在图像序列中的,出现频率可由编码器选择。
- 「P 帧(Predicted frames)」:P 帧采用帧间编码方式,即同时利用了空间和时间上的相关性。P 帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P 帧图像中可以包含帧内编码的部分,即 P 帧中的每一个宏块可以是前向预测,也可以是帧内编码。
- 「B 帧(Bi-directional predicted frames)」:B 帧图像采用帧间编码方式,且采用双向时间预测,可以大大提高压缩倍数。也就是其在时间相关性上,还依赖后面的视频帧,也正是由于 B 帧图像采用了后面的帧作为参考,因此造成视频帧的传输顺序和显示顺序是不同的。
也就是说,一个 I 帧可以不依赖其他帧就解码出一幅完整的图像,而 P 帧、B 帧不行。P 帧需要依赖视频流中排在它前面的帧才能解码出图像。B 帧则需要依赖视频流中排在它前面或后面的I/P帧才能解码出图像。
对于I帧和P帧,其解码顺序和显示顺序是相同的,但B帧不是,如果视频流中存在B帧,那么就会打算解码和显示顺序。
正因为解码和显示的这种非线性关系,所以需要DTS、PTS来标识帧的解码及显示时间。
2.2时间戳DTS、PTS
- DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。
- PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
当视频流中没有 B 帧时,通常 DTS 和 PTS 的顺序是一致的。但如果有 B 帧时,就回到了我们前面说的问题:解码顺序和播放顺序不一致了,即视频输出是非线性的。
比如一个视频中,帧的显示顺序是:I B B P,因为B帧解码需要依赖P帧,因此这几帧在视频流中的顺序可能是:I P B B,这时候就体现出每帧都有 DTS 和 PTS 的作用了。DTS 告诉我们该按什么顺序解码这几帧图像,PTS 告诉我们该按什么顺序显示这几帧图像。顺序大概如下:

从流分析工具看,流中P帧在B帧之前,但显示确实在B帧之后。
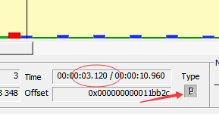
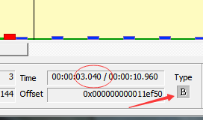
需要注意的是:虽然 DTS、PTS 是用于指导播放端的行为,但它们是在编码的时候由编码器生成的。
以我们最常见的TS为例:
TS流中,PTS/DTS信息在打流阶段生成在PES层,主要是在PES头信息里。
标志第一位是PTS标识,第二位是DTS标识。
标志:
00,表示无PTS无DTS;
01,错误,不能只有DTS没有PTS;
10,有PTS;
11,有PTS和DTS。
PTS有33位,但是它不是直接的33位数据,而是占了5个字节,PTS分别在这5字节中取。

TS的I/P帧携带PTS/DTS信息,B帧PTS/DTS相等,进保留PTS;由于声音没有用到双向预测,它的解码次序就是它的显示次序,故它只有PTS。
TS的编码器中有一个系统时钟STC(其频率是27MHz),此时钟用来产生指示音视频的正确显示和解码时间戳。
PTS域在PES中为33bits,是对系统时钟的300分频的时钟的计数值。它被编码成为3个独立的字段:
PTS[32…30][29…15][14…0]。
DTS域在PES中为33bits,是对系统时钟的300分频的时钟的计数值。它被编码成为3个独立的字段:
DTS[32…30][29…15][14…0]。
因此,对于TS流,PTS/DTS时间基均为1/90000秒(27MHz经过300分频)。
PTS对于TS流的意义不仅在于音视频同步,TS流本身不携带duration(可播放时长)信息,所以计算duration也是根据PTS得到。
附上TS流解析PTS示例:
#define MAKE_WORD(h, l) (((h) << 8) | (l))
//packet为PES
int64_t get_pts(const uint8_t *packet)
{
const uint8_t *p = packet;
if(packet == NULL) {
return -1;
}
if(!(p[0] == 0x00 && p[1] == 0x00 && p[2] == 0x01)) { //pes sync word
return -1;
}
p += 3; //jump pes sync word
p += 4; //jump stream id(1) pes length(2) pes flag(1)
int pts_pts_flag = *p >> 6;
p += 2; //jump pes flag(1) pes header length(1)
if (pts_pts_flag & 0x02) {
int64_t pts32_30, pts29_15, pts14_0, pts;
pts32_30 = (*p) >> 1 & 0x07;
p += 1;
pts29_15 = (MAKE_WORD(p[0],p[1])) >> 1;
p += 2;
pts14_0 = (MAKE_WORD(p[0],p[1])) >> 1;
p += 2;
pts = (pts32_30 << 30) | (pts29_15 << 15) | pts14_0;
return pts;
}
return -1;
}3.常用同步策略
前面已经说了,实现音视频同步,在播放时,需要选定一个参考时钟,读取帧上的时间戳,同时根据的参考时钟来动态调节播放。现在已经知道时间戳就是PTS,那么参考时钟的选择一般来说有以下三种:
- 将视频同步到音频上:就是以音频的播放速度为基准来同步视频。
- 将音频同步到视频上:就是以视频的播放速度为基准来同步音频。
- 将视频和音频同步外部的时钟上:选择一个外部时钟为基准,视频和音频的播放速度都以该时钟为标准。
当播放源比参考时钟慢,则加快其播放速度,或者丢弃;快了,则延迟播放。
这三种是最基本的策略,考虑到人对声音的敏感度要强于视频,频繁调节音频会带来较差的观感体验,且音频的播放时钟为线性增长,所以一般会以音频时钟为参考时钟,视频同步到音频上。
在实际使用基于这三种策略做一些优化调整,例如:
- 调整策略可以尽量采用渐进的方式,因为音视频同步是一个动态调节的过程,一次调整让音视频PTS完全一致,没有必要,且可能导致播放异常较为明显。
- 调整策略仅仅对早到的或晚到的数据块进行延迟或加快处理,有时候是不够的。如果想要更加主动并且有效地调节播放性能,需要引入一个反馈机制,也就是要将当前数据流速度太快或太慢的状态反馈给“源”,让源去放慢或加快数据流的速度。
- 对于起播阶段,特别是TS实时流,由于视频解码需要依赖第一个I帧,而音频是可以实时输出,可能出现的情况是视频PTS超前音频PTS较多,这种情况下进行同步,势必造成较为明显的慢同步。处理这种情况的较好方法是将较为多余的音频数据丢弃,尽量减少起播阶段的音视频差距。
4.音视频同步简单示例代码
代码参考ffplay实现方式,同时加入自己的修改。以audio为参考时钟,video同步到音频的示例代码:
- 获取当前要显示的video PTS,减去上一帧视频PTS,则得出上一帧视频应该显示的时长delay;
- 当前video PTS与参考时钟当前audio PTS比较,得出音视频差距diff;
- 获取同步阈值sync_threshold,为一帧视频差距,范围为10ms-100ms;
- diff小于sync_threshold,则认为不需要同步;否则delay+diff值,则是正确纠正delay;
- 如果超过sync_threshold,且视频落后于音频,那么需要减小delay(FFMAX(0, delay + diff)),让当前帧尽快显示。
如果视频落后超过1秒,且之前10次都快速输出视频帧,那么需要反馈给音频源减慢,同时反馈视频源进行丢帧处理,让视频尽快追上音频。因为这很可能是视频解码跟不上了,再怎么调整delay也没用。 - 如果超过sync_threshold,且视频快于音频,那么需要加大delay,让当前帧延迟显示。
将delay*2慢慢调整差距,这是为了平缓调整差距,因为直接delay+diff,会让画面画面迟滞。
如果视频前一帧本身显示时间很长,那么直接delay+diff一步调整到位,因为这种情况再慢慢调整也没太大意义。 - 考虑到渲染的耗时,还需进行调整。frame_timer为一帧显示的系统时间,frame_timer+delay- curr_time,则得出正在需要延迟显示当前帧的时间。
{
video->frameq.deQueue(&video->frame);
//获取上一帧需要显示的时长delay
double current_pts = *(double *)video->frame->opaque;
double delay = current_pts - video->frame_last_pts;
if (delay <= 0 || delay >= 1.0)
{
delay = video->frame_last_delay;
}
// 根据视频PTS和参考时钟调整delay
double ref_clock = audio->get_audio_clock();
double diff = current_pts - ref_clock;// diff < 0 :video slow,diff > 0 :video fast
//一帧视频时间或10ms,10ms音视频差距无法察觉
double sync_threshold = FFMAX(MIN_SYNC_THRESHOLD, FFMIN(MAX_SYNC_THRESHOLD, delay)) ;
audio->audio_wait_video(current_pts,false);
video->video_drop_frame(ref_clock,false);
if (!isnan(diff) && fabs(diff) < NOSYNC_THRESHOLD) // 不同步
{
if (diff <= -sync_threshold)//视频比音频慢,加快
{
delay = FFMAX(0, delay + diff);
static int last_delay_zero_counts = 0;
if(video->frame_last_delay <= 0)
{
last_delay_zero_counts++;
}
else
{
last_delay_zero_counts = 0;
}
if(diff < -1.0 && last_delay_zero_counts >= 10)
{
printf("maybe video codec too slow, adjust video&audion");
#ifndef DORP_PACK
audio->audio_wait_video(current_pts,true);//差距较大,需要反馈音频等待视频
#endif
video->video_drop_frame(ref_clock,true);//差距较大,需要视频丢帧追上
}
}
//视频比音频快,减慢
else if (diff >= sync_threshold && delay > SYNC_FRAMEDUP_THRESHOLD)
delay = delay + diff;//音视频差距较大,且一帧的超过帧最常时间,一步到位
else if (diff >= sync_threshold)
delay = 2 * delay;//音视频差距较小,加倍延迟,逐渐缩小
}
video->frame_last_delay = delay;
video->frame_last_pts = current_pts;
double curr_time = static_cast<double>(av_gettime()) / 1000000.0;
if(video->frame_timer == 0)
{
video->frame_timer = curr_time;//show first frame ,set frame timer
}
double actual_delay = video->frame_timer + delay - curr_time;
if (actual_delay <= MIN_REFRSH_S)
{
actual_delay = MIN_REFRSH_S;
}
usleep(static_cast<int>(actual_delay * 1000 * 1000));
//printf("actual_delay[%lf] delay[%lf] diff[%lf]n",actual_delay,delay,diff);
// Display
SDL_UpdateTexture(video->texture, &(video->rect), video->frame->data[0], video->frame->linesize[0]);
SDL_RenderClear(video->renderer);
SDL_RenderCopy(video->renderer, video->texture, &video->rect, &video->rect);
SDL_RenderPresent(video->renderer);
video->frame_timer = static_cast<double>(av_gettime()) / 1000000.0 ;
av_frame_unref(video->frame);
//update next frame
schedule_refresh(media, 1);
}作者:wusc’blog
来源:https://blog.csdn.net/myvest/article/details/97416415
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
