
分享 WebRTC.ventures 团队在开发语音 AI 应用上结合基础知识和实际指导的简明见解。
解决延迟问题
优先考虑简短回复而不是简短提示,以加快对话速度
在实时 WebRTC 应用中,最小化延迟至关重要。虽然 LLM 处理输入的速度比生成输出的速度快,但缩短响应时间的关键在于促使模型生成简洁的答案,而不是仅仅专注于缩短输入提示。对于语音 AI 系统来说,这种方法可以确保更自然的对话式交互。工程团队在设计提示时应优先考虑鼓励模型做出简短、高效的回答,同时在输入中保持足够的上下文语境。
确定信息相关性的优先顺序
提示信息的顺序会对模型输出的质量产生重大影响。通过将最关键的细节放在提示信息的首位,工程师可以确保模型立即将重点放在重要的上下文上。这一点在语音应用中尤为重要,因为快速理解可以带来更好的用户体验。
注:为了降低成本,将提示的静态部分放在通话开始时也很有帮助。OpenAI 会缓存 token,因此速度更快,成本更低。
利用特殊 Token 来表达语音上下文
专为语音交互定制的特殊 token 可以显著提升 LLM 的性能。这些 token 提供明确的指令,阐明说话者的意图,并定义任务参数,从而提高交互效率。例如:
<speaker:user> "I'd like to book a flight to Miami tomorrow evening."
<context:intent=travel_booking; urgency=high>
<task:quick_response; required_info=[departure_city, flight_time_options]>
<chain-of-thought:false>
<response_format:concise; max_tokens=50>
<speaker:agent>虽然其中一些内容已经自动添加,并且在使用 ChatGPT 时不可见,但在某些情况下可能值得尝试。
平衡思维链和响应速度
通过 WebRTC 进行语音交互需要即时、清晰的响应。虽然 “思维链(Chain-of-Thought) ”方法能提高推理深度,但也会降低响应速度。在简洁、直接的提示与更深入的推理过程之间进行策略性平衡,既能保证质量,又不影响速度。
优化检索增强生成 (RAG)
混合搜索以获得最佳性能
利用兼具词汇搜索效率和语义搜索灵活性的混合方法,可以获得最佳结果。在某些情况下,这种方法可以提升需要实时数据检索的 WebRTC 语音应用的性能和用户友好度。当然,如果搜索的数据不是特定的单词或短语,传统的 RAG 可能更合适。
绕过 RAG 以获得较小的数据集
如果数据集能够轻松适应 LLM 上下文窗口,则完全省略 RAG 可以简化交互并降低处理开销,从而有利于 WebRTC 的实时响应。在 WebRTC.ventures,如果可能的话,这是我们的首选方法。
更自然的对话:打断、轮流检测和改善的用户体验
超越基本 VAD
虽然语音活动检测 (VAD) 仍然是基础,但 2025 年的系统将越来越多地结合:
- 语义 VAD:OpenAI 的最新模型通过分析语音内容和韵律来预测转向终点,从而减少了 “uhm ”等填充词造成的误报。
- LLM 原生检测: 现在,LiveKit 和 Pipecat by Daily 等框架已将 turn-taking 直接集成到 LLM 推理中,从而实现了双向音频流。
- 基于Transformer的混合模式:Voice Activity Projection (VAP) 等模型使用多层Transformer,通过实时声学和语义分析来预测会话中的轮换。
执行复杂任务的 Agentic AI
虽然通用人工智能 (AGI) 仍面向未来,但像 CrewAI 这样的工具已经支持复杂的多步骤工具调用交互,包括 API 调用、搜索和动态响应生成。此功能极大地丰富了复杂的 WebRTC 应用程序。此外,LiveKit Agents 和 Pipecat 等框架也可用于开发自定义函数调用。
通过 Artifact 加强反馈
语音AI交互中的反馈可以增强用户信任度和可用性。结构化数据(例如JSON或HTML)有助于将LLM操作与语音对话可视化,使用户更容易理解AI驱动的流程。讨论的一种实用格式如下:
<artifact identifier="d3adb33f" type="application/json" title="Example Artifact">
... content ...
</artifact>最近,我们从 OpenAI 看到了一些这样的例子:
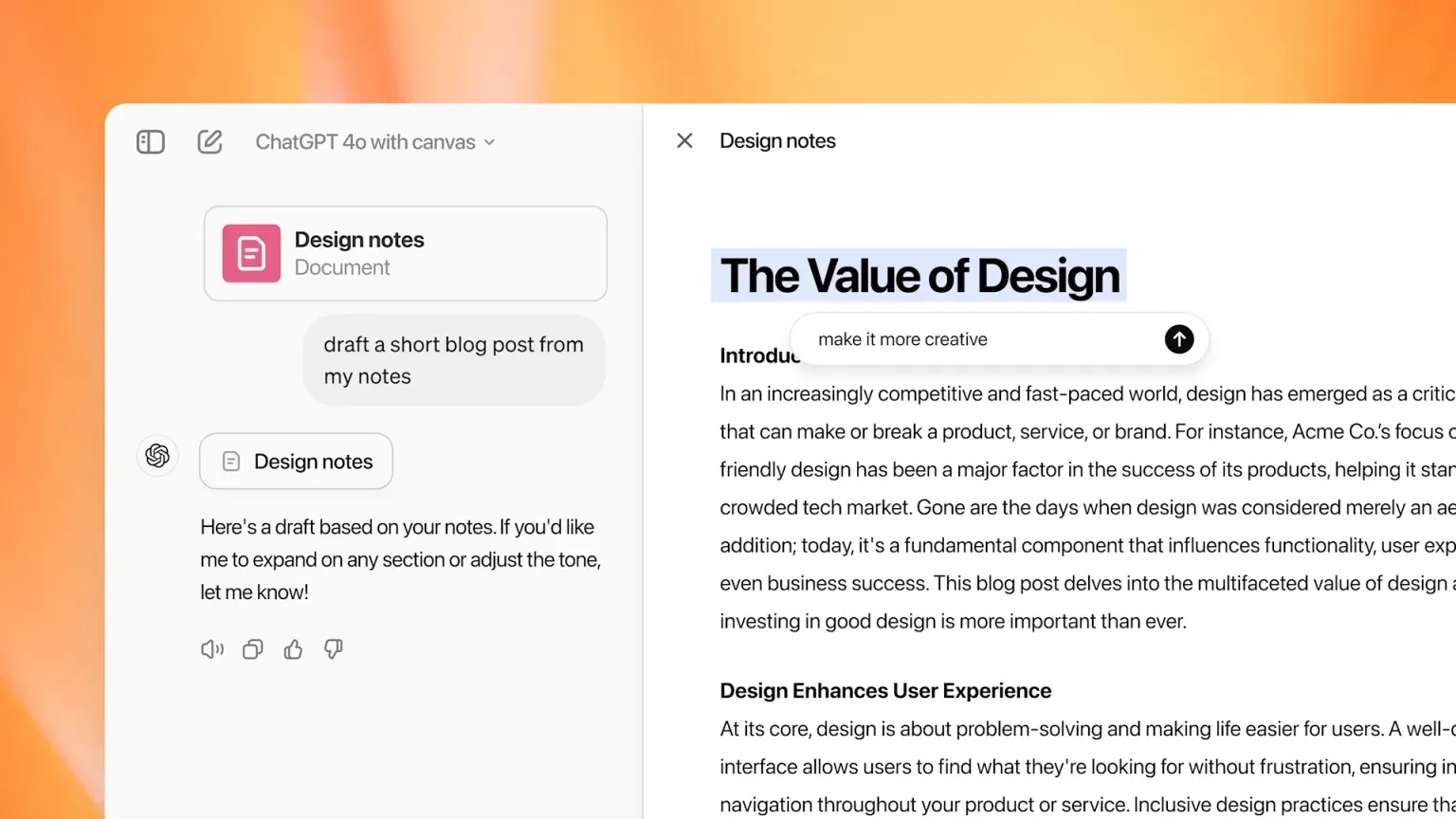
实时浏览器可视化曾经颇具挑战性,但在现代 WebRTC 支持的环境中,它已变得越来越可行。我们将在未来的博客文章中探讨这一点。
可观察性是必须的,使用 LLM Judges 进行评估是可选的
将 Langfuse 等可观察性工具整合到您的部署流程中,有助于及早发现问题并实现有效的 A/B 测试。以指标为驱动的开发可确保持续改进。
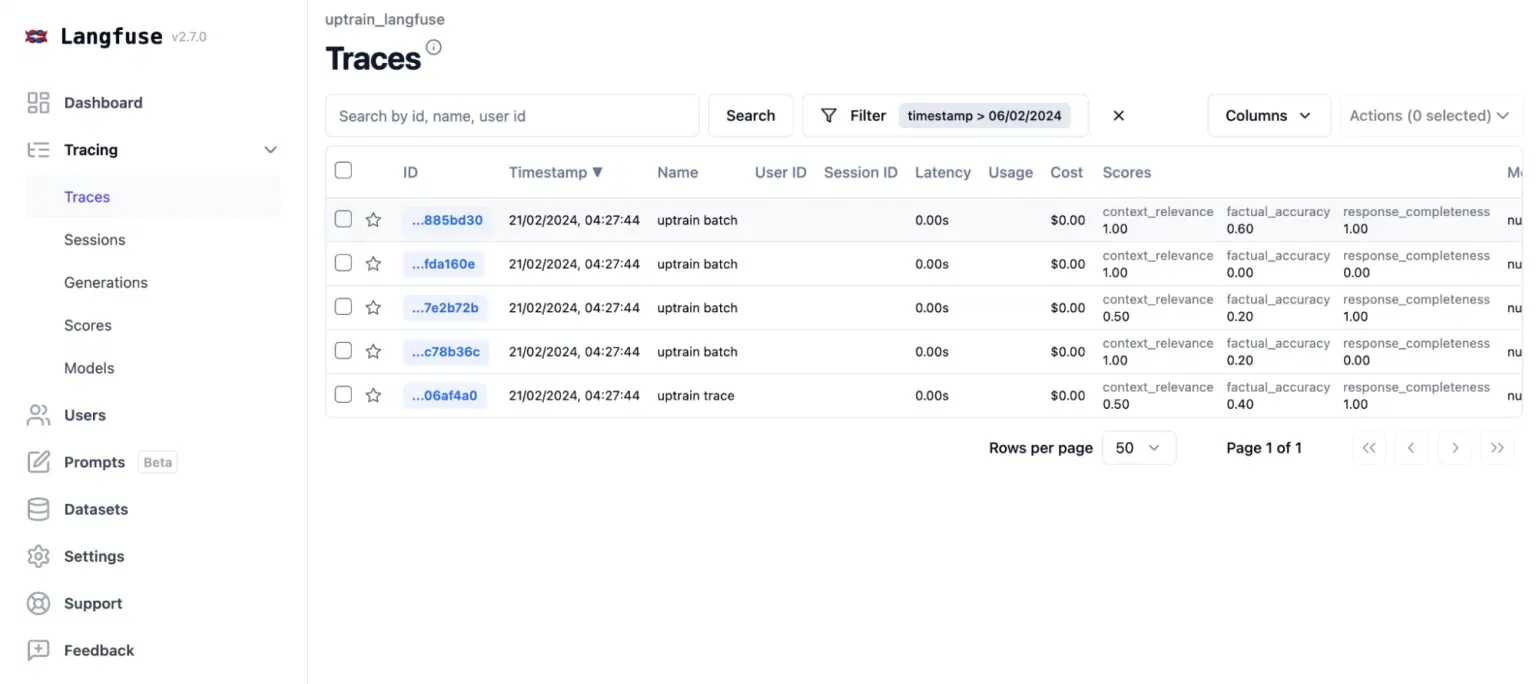
采用 LLM 的自动化评估系统,能够提供可扩展且客观的绩效评估。例如,评估旅行AI代理将涉及:
- 生成合成用户场景
- 具有结构化结果的自动化转录分析
- 补充人工监督以完善自动化判断
使用 LoRA 实现经济高效的模型适配
对大型 LLM 进行全面微调需要大量计算,而且对许多组织而言,成本往往过高。相比之下,低秩自适应 (LoRA) 等技术则提供了一种更高效的替代方案,它通过在模型中注入小型可训练的参数矩阵。这让您能够微调特定行为,同时显著减少训练时间和基础设施成本。您可以使用OpenAI 的微调 API等工具或Amazon SageMaker等平台来应用 LoRA 。
另一种有效的策略是精炼,即训练一个规模较小的学生模型来模仿规模较大的教师模型的行为。精炼模型或小型语言模型 (SLM) 保留了原始模型的大部分功能,但速度更快,更适合在延迟敏感的环境中部署。
多模态语音语言模型 (SLM)
像Ultravox v0.5 和 GPT-4o-mini这样的模型现在可以直接处理音频波形,绕过了传统的语音转文本 (STT) 和文本转语音 (TTS) 流程。这种架构转变释放了新的功能,尤其是在对话流畅性、自然的轮换和细致入微的理解方面,多模态语音语言模型 (SLM) 的性能日益超越传统流程。
尽管 SLM 提供了更加集成和富有表现力的对话体验,但准确性基准仍然青睐传统管道,这使得开发人员可以配对一流的 STT 和 TTS 组件以实现最高精度。
尽管 SLM 前景光明,但它们尚未弥合延迟差距。根据最近的WebRTC Hacks 分析(2025 年 4 月),OpenAI 基于 WebRTC 的 Realtime API 仍然表现出超过一秒的端到端延迟。相比之下,优化良好的基于管道的语音助手通常只需 100-300 毫秒就能响应简短的查询。
结:SLM 是对话式 AI 设计领域的一次巨大飞跃,它提供了更自然、更富有情感响应的交互。然而,它们仍然不如传统流程成熟,工具选项较少,生产支持也不够广泛,不过这种差距正在迅速缩小。
最后的想法
语音 AI 开发正在快速发展,融合了基于文本的提示音工程的经验教训以及实时音频/视频系统的独特考量。通过应用这些策略(从优化提示音到利用混合检索方法),工程团队可以交付适合现代 WebRTC 环境的高性能解决方案。
作者:Alberto Gonzalez
译自:https://webrtc.ventures/2025/04/optimizing-prompts-for-real-time-voice-ai/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/yinshipin/57322.html
