
本文从B站流媒体点直播的日常业务出发,结合具体业务实例详细介绍如何利用算法赋能业务。
作者丨Fiver
来源 | 多媒体 哔哩哔哩技术
背景概述
早在20世纪人们就开始了人工智能的相关研究。当时的算法相对简易,同时硬件水平和数据量的制约,因此当时人工智能的应用十分有限。而随着时代发展,发展出了如决策树、支持向量机、神经网络等各类复杂算法,并发展出了深度学习和强化学习两个重要分支。同时数据时代带来海量数据,以及数据挖掘和数据处理技术的进步。最后,硬件算力的突破,支撑起复杂算法在海量数据上的训练测试,能够处理更复杂问题。算法、数据和硬件三者共同促进人工智能在各个领域的广泛应用,比如图像识别、语音识别、自然语言处理等。
在流媒体点直播业务中存在非常多复杂数据,如高维数据、非线性关系数据、多模态数据、动态或时序数据等。同时业务当中的问题可能是缺乏明确规则或先验知识的,比如预测问题,预测热门稿件;也可能是复杂模式识别问题,比如自然语言处理,处理弹幕文本。这使得利用人为经验或规则很难很好的解决这些实际业务问题。于是我们尝试借助算法能力解决实际问题。本文将从点直播业务出发,结合具体业务问题介绍为何需要借助算法能力、如何借助算法能力以及最终取得什么样的效果。
业务实例
点播优化转码决策
1. 业务背景
在点播业务中,用户投稿的稿件经过h264转码后开放。相比起h264,h265和av1等编码方式(下文统一简称为优化转码)是更先进的视频编码标准,在视频压缩效率上有显著提升。例如,h265相较于h264提供了较高的压缩效率,而av1相较于h265实现进一步提升。因此,相对h264,优化转码在相同画质下,能够有效节省存储空间和带宽。
显然对越多的稿件转出优化转码,就能够节省越多存储和带宽。然而,由于算力资源的限制,对所有点播稿件转出优化转码是存在困难的。于是,需要在有限的算力情况下,尽可能选出“头部稿件”转出优化转码,因为“头部稿件”拥有更多的播放量,对节省带宽有更多的贡献。
这里我们将稿件播放量作为“头部稿件”的评定标准,将“头部稿件”具体定义为:播放量降序排列,占90%总播放量的前n个稿件。于是,点播优化转码决策的问题可以描述为如何从所有稿件中挑选出播放量排序靠前的“头部稿件”。如果等到实际产生足够播放数据后才进行“头部稿件”的筛选来转出优化转码,那在优化转码转出前存在带宽浪费,且由于播放量的周期衰减,转出后的带宽收益也会大打折扣。因此,需要尽早预测出“头部稿件”转出优化转码才能最大化收益。
一个稿件能否在未来有较高的播放量,通常受很多因素影响,比如up主的粉丝量,投币数,up主过往投稿播放量、点赞数,稿件所属分区等。这些因素对播放量的影响不一定都是简单的线性相关,且各个因素之间也会互相影响,很难人为制定一个换算规则。因此需要借助算法学习各个因素到播放量之间的映射关系。
2. 转码决策模型矩阵
根据稿件所处的不同的阶段,设计多个子模型构建算法矩阵进行“头部稿件”的预测。具体而言:稿件开放前,使用up主相关信息和稿件基本信息训练Model1;稿件开放24小时内,基于稿件播放量设计实时决策模型Model2;稿件开放24小时后,除了已有的up主相关信息和稿件基本信息,利用过去一天产生的稿件播放相关数据训练Model3。
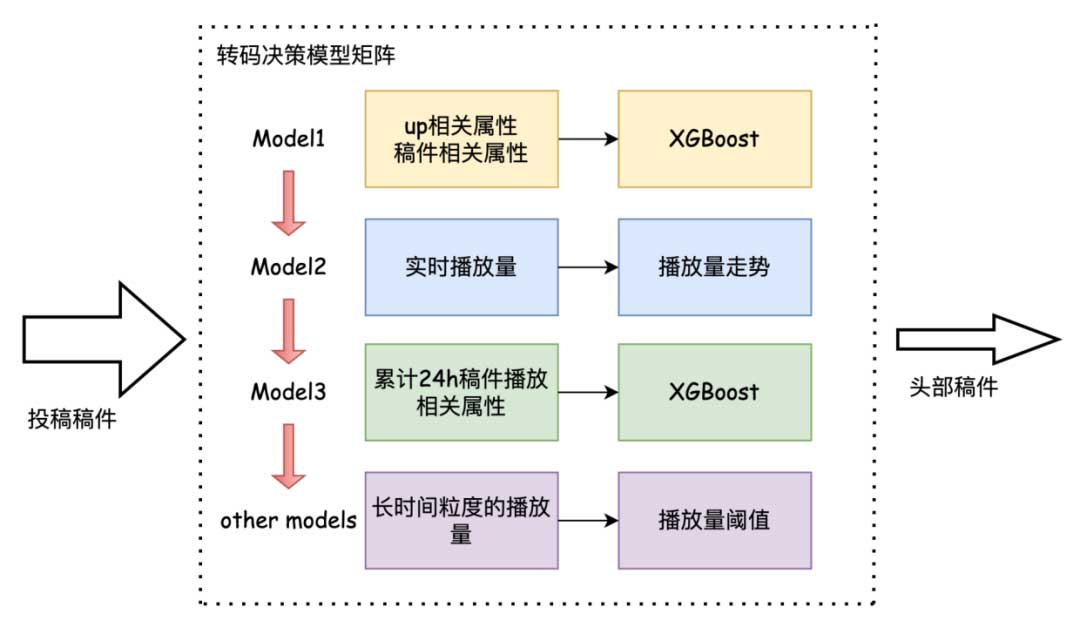
在模型选型上,Model1和Model3选用基于树模型XGBoost。通过计算特征(up主相关信息和稿件相关信息)与标签(是否为“头部稿件”,通过稿件开放后一段时间播放量排序计算获得)之间的相关性,发现特征与标签之间的线性关系普遍较差,但互信息上有显著相关性,这为选择树模型提供了良好的依据。
相比起单颗树模型,XGBoost通过梯度提升训练多棵树逐步优化模型,将弱学习器集成为强学习器。另外,XGBoost在具体的算法和工程实现方面加了许多改进:比如目标函数使用一阶导数和二阶导数,二阶优化更为精准;损失函数上,灵活支持任意可微的损失函数;引入显式的正则化项,有助于控制模型复杂度防止过拟合。另外,将连续值离散化提高分裂点搜索效率,同时支持特征并行搜索和分布式训练,提升处理大规模数据的能力。因此这里选用XGBoost模型。在模型训练中,我们构建了百万条样本,并基于网格搜索进行超参数调优。
Model2模型是基于统计量设计的实时决策模型。通过统计对比“头部视频”与非“头部视频”的在开放后24小时内的实时播放量趋势,发现两者存在明显差异,“头部视频”的播放量通常会有更高的起点和更快的增长速度,基于统计量构建“头部视频”的典型播放量走势,实时决策稿件是否为“头部视频”。
以上三个子模型,存在预测转出优化转码的收益依次递减,而模型决策可用信息量递增的特点。因此构建模型矩阵串行决策,各个子模型互为补充,提升模型决策的稳定和“头部稿件”的召回。具体而言,Model1主要负责筛选出“头部稿件”中更为头部的稿件,这部分稿件播放量更高需要尽早转出,Model2和Model3分别根据实时播放量和累积一天的播放数据决策,依次筛选补充前序模型中遗漏的有播放潜力的稿件,这部分稿件通常是较为腰部或尾部的稿件,对转出实效性相对不那么敏感且在Model1中难以精准识别。
除此之外,在更长的时间粒度上补充决策,此时由于稿件已经产生足够播放数据,直接根据播放量排序截取未转出优化转码的但播放量较高的稿件,或达到一定播放量阈值补充转出优化转码。但由于转出实效性较差,这部分任务收益较小仅作为辅助补充,决策主体部分仍然在以上三个子模型。
3. 模型效果
针对于每日新增稿件,模型决策任务量约10%,其播放量约占所有新稿件播放总量的90%,对于“头部稿件”的召回率约75%。模型自2021年上线以来,模型决策结果已陆续用于h265 av1等多种优化转码的生产,各优化转码播放量占比(vv)逐步提升。
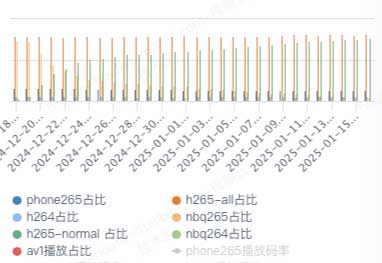
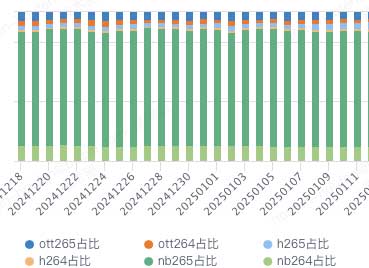
各播放端当前播放占比(vv)如图3-5所示,各端优化转码播放占比稳定处于较高水平。
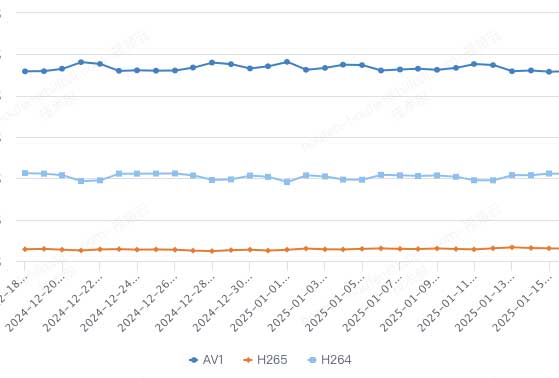
最后,关于各优化转码实际转出任务量。基于模型决策结果,我们针对不同的优化转码进行差异化调整,例如Model2 Model3的补充任务只会用于h265和av1,所以各个优化转码的实际任务量不一定一致。另外,在下一部分将介绍的点播转码资源预估中,我们对转码资源的使用进行了优化,在资源空闲时,实际可转出任务量会根据资源情况超发提升整体资源利用率,而在资源紧缺时也可能对任务进行削减。因此不同优化转码实际任务量存在变动,并不一定严格按照模型决策量的10%转出,以h265和av1为例,目前h265每日任务转出量约为av1三倍。
点播转码资源预估
1. 业务背景
在上文点播优化转码决策中提到,算力资源有限无法对所有稿件进行优化转码,所以需要筛选“头部稿件”。随着投稿量的日益增长,转码决策的任务量也会随之增长,且由于边际效应,在当前基础上继续提升播放占比需要转出更多的任务。这都需要更多的算力资源支持。然而在实际使用中,资源利用率存在周期波动,比如午高峰、晚高峰资源较为紧张,而夜间凌晨时间则较为空闲。资源的不均衡使用会带来两个问题:一是在资源高峰时段容易出现任务排队造成系统压力;二是空闲时段容易造成算力资源浪费。因此,期望转码任务能够根据实际资源情况进行下发或阻塞,实现资源均衡使用及资源利用率提升,能够承接更高任务负载。如果通过人为经验进行调节,通常不够灵活无法处理如资源总量突增或突减的突发状况,资源利用率仍会存在较大波动。因此我们设计了资源量化模型,有效平滑资源利用率曲线和提升资源利用率。
2. 资源量化模型
资源量化模型主要分为两部分:第一部分是资源角度,每隔一分钟预测一次剩余可用资源,实时感知资源变化便于动态调整策略;第二部分是任务角度,差异化任务,预估当前任务所需资源并结合当前可用资源来进行投递,实现资源使用的可控和提升资源利用率。
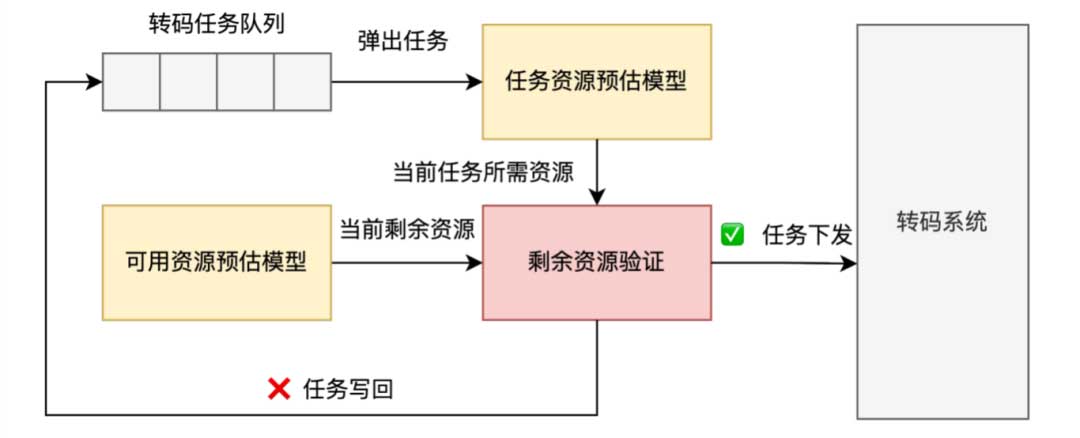
2.1 可用资源预估模型
在可用资源预估中,受到股票交易问题的启发,从“前进方向”、“前进幅度”、“前进幅度修正”三个角度入手。设计了资源预测公式:
valid_core = core * c *(1 – vol + vol_rate) if usage < threshold else 0
参数解释:
- core: 当前剩余核数
- c: 核系数,core归一化后sigmod函数变换
- vol: 波动系数,近半小时资源利用率方差,归一化后tanh函数变换
- vol_rate: 波动方向,近15分钟剩余可用核数拟合直线的斜率,归一化后tanh函数变换
公式当中的资源利用率usage 对应着“前进方向”,利用率小于阈值则进行任务投递,反之停止。公式当中的当前剩余核数core,和核系数c,对应着“前进幅度”,其中核系数反映了当前剩余核数相对全局的情况,公式中的波动系数vol和波动方向vol_rate对应着“前进幅度修正”,其中波动系数表示了近期资源波动情况,波动越大该值越大,而波动方向,可以看成是波动系数的修正,因为波动大也可能是资源变多。5个参数组合在一起相互合作与制约,实现资源空闲时加大下发任务,紧缺时迅速收束阻塞。
2.2 任务资源预估模型
在任务资源预估中,通过数据拟合,发现同一稿件的不同转码方式所需的资源存在高度线性关系,以h265与av1任务之间所需算力资源之间的关系为例:
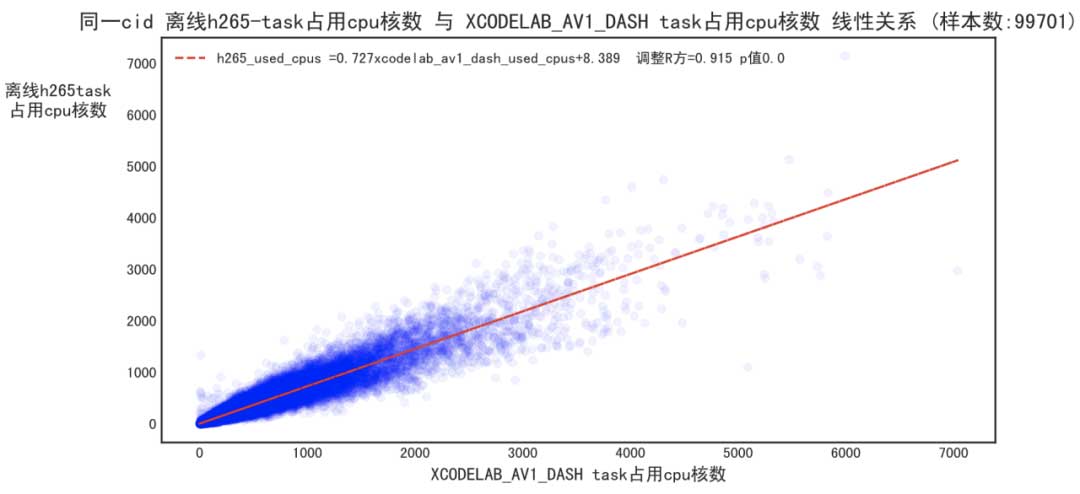
因此我们拟合了各个转码方式之间两两组和的线性关系。在预估当前任务所需的资源时,只需通过该稿件任意一个已有转码方式所消耗的资源量进行线性换算即可。由于在转出各类优化转码之前,稿件至少已经转出h264任务了所以稿件不会出现没有基准转码方式的情况。
3. 模型效果
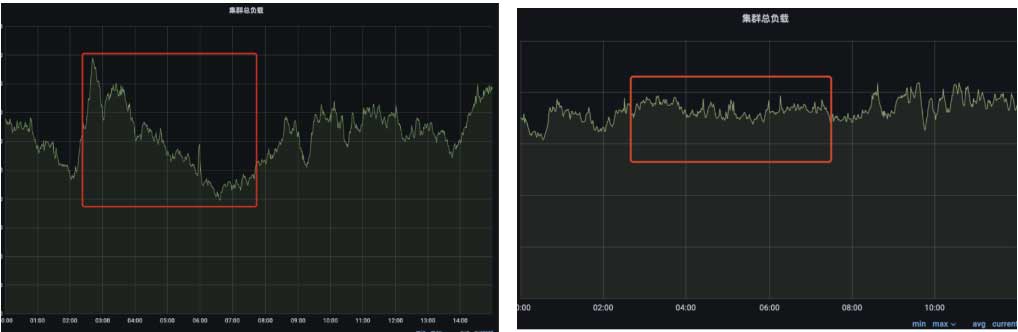
模型按照试点应用到全天应用推进:先在对业务影响较小且算力资源最为空闲的凌晨时段试运行,在验证模型效果之后,推广到全天使用并逐步增加任务量拉升整体资源利用率。
将模型用于凌晨2-8点时段,凌晨资源利用率曲线由陡峭变平滑。凌晨平均资源利用率提升13%,可投递任务量增长25%,提升h265、av1等优化转码任务的播放占比约5%。资源量化模型接入前后对比:
为了进一步提升算力资源利用率承接更多转码任务,我们基于资源量化模型实现quanter任务囤积服务,在全天对优化转码任务进行调控。在资源紧张时服务主动对任务囤积阻塞,在资源空闲时迅速下发拉升资源利用率。由于进入quanter囤积的任务无法保证转码时效性,因此,我们选取转码决策模型中相对尾部的任务和放宽模型决策阈值后新增的任务。另外,针对所有囤积任务,服务内部进行了任务优先级排序,以保证每次任务弹出时总是优先当前高价值任务,而当资源十分紧缺需要丢弃任务时会优先低价值任务。任务排序规则依赖转码决策模型的决策信息和具体优化转码的码率收益。
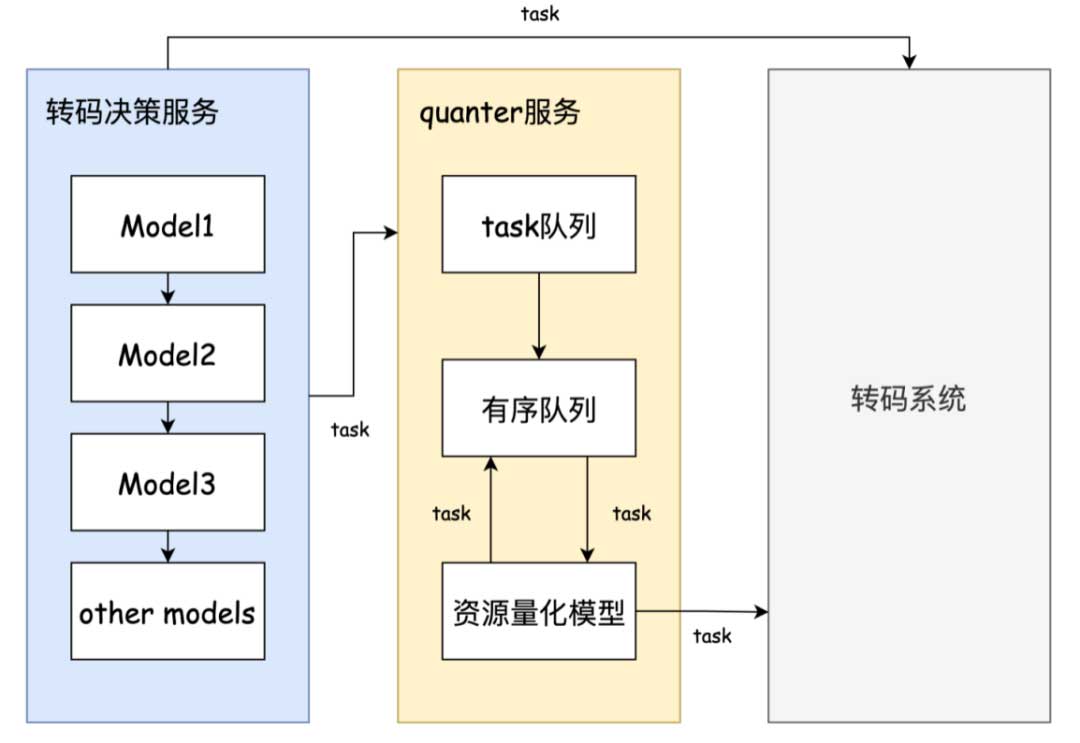
通过任务囤积,quanter服务每日能承载百万级优化转码任务,夜间平均资源率在80%以上,由于白天资源被其他业务占用资源利用率较高,所以在白天资源量化模型主要是抑制避让缓解资源压力,白天利用率提升有限,符合模型预期。
转码耗时预估
前文提到,用户投稿后稿件需要先进行h264转码后开放,为了便于用户了解稿件的转码进度,需要对转码耗时进行预估。而转码耗时相关因素复杂,比如时长、文件大小、帧率等稿件自身相关属性,以及如任务优先级、切片大小、转码资源等转码相关属性。人为制定规则难以捕捉各个特征之间的关系,通常较为粗糙且预估误差较大。本节将简单介绍如何借助算法提升转码耗时准确率。
转码耗时预估模型选用xdeepfm模型。模型结构如下:
前文提到,用户投稿后稿件需要先进行h264转码后开放,为了便于用户了解稿件的转码进度,需要对转码耗时进行预估。而转码耗时相关因素复杂,比如时长、文件大小、帧率等稿件自身相关属性,以及如任务优先级、切片大小、转码资源等转码相关属性。人为制定规则难以捕捉各个特征之间的关系,通常较为粗糙且预估误差较大。本节将简单介绍如何借助算法提升转码耗时准确率。
转码耗时预估模型选用xdeepfm模型。模型结构如下:
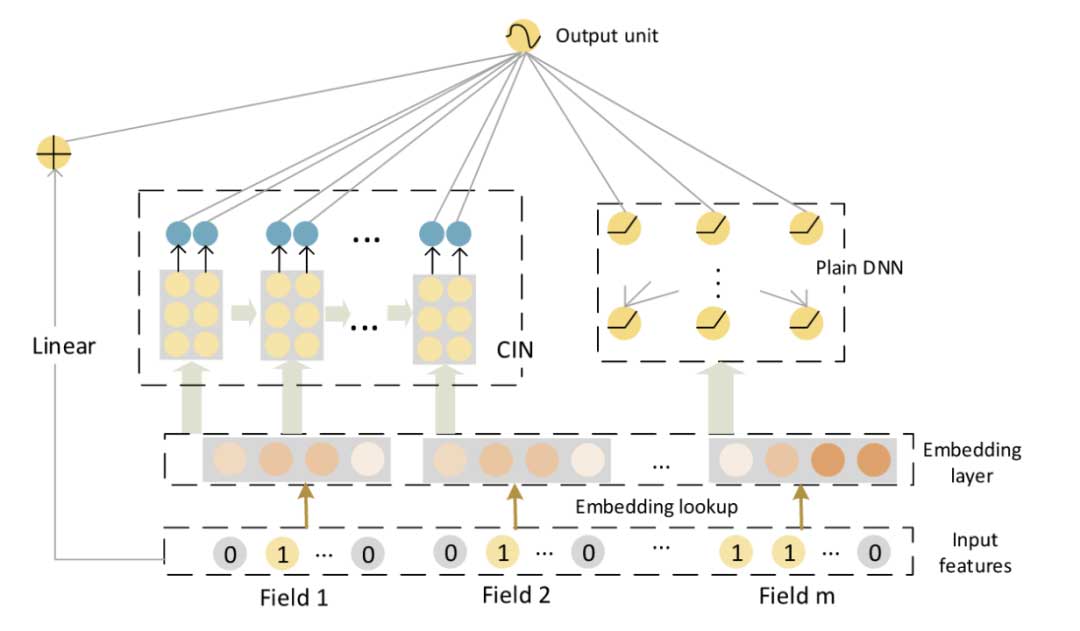
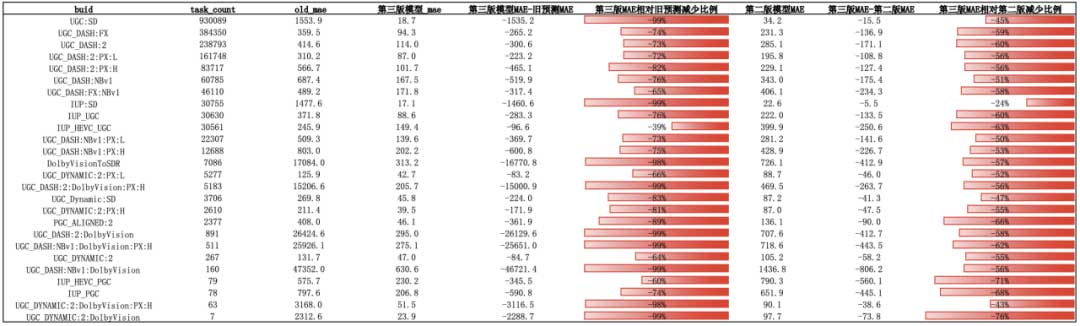
该模型通过线性模块、压缩交互模块、DNN模块分别捕捉特征间的线性关系、高阶显式特征、高阶隐式特征,适用于需要高阶特征交互的问题。我们从稿件信息和转码信息中筛选出54个特征,构建百万条样本进行xdeepfm模型训练。模型测试结果:转码预估与实际耗时平均绝对误差小于5分钟,较人工规则评估误差平均降低70%。详细数据如下:
另外,随着转码流程的优化如流式转码,转码任务的实际耗时分布存在变化。基于旧数据样本训练得到的模型在线上表现逐渐劣化,因此需要根据具体的流程变化情况,重新构建样本训练模型。具体而言,流式转码大大缩短了转码所需时间,那么基于非流式转码数据训练的模型预估结果就会偏大。因此模型需要添加相关特征,如是否为流式转码、流式切片时长等,进行重新训练来纠正旧模型的误差。
除了以上介绍的点播业务,我们也在挖掘对直播业务算法赋能的可能。比如,直播弹幕语义分析,实时识别用户反馈的直播卡顿或直播画质问题,帮助相关技术人员及时排查直播链路上可能存在的问题,提升用户体验。在下一节中,将从该案例简略介绍直播业务的算法赋能。
直播弹幕语义分析
直播弹幕语义分析旨在通过实时分析各个直播间的所有弹幕,从中辨别是否存在反馈直播卡顿或直播画质问题的弹幕,一旦存在较多反馈则触发告警便于相关技术人员及时进行问题排查。
随着Transformer框架提出,自然语言处理领域从理论到实践都获得了巨大的突破。当前我们所熟知的BERT、GPT等模型都是基于此框架发展而来。BERT适合如文本分类、文本相似度之类的文本理解任务,而GPT则更擅长如文本生成、对话系统等的生成任务。在直播弹幕语义分析上,需要模型判断当前弹幕句子是否与目标表达(如卡顿表达)的相似度,显然BERT模型擅长解决该问题。但模型选型上,我们没有直接使用BERT,而是选用SBERT(Sentence-BERT)。因为BERT的输出是基于词的嵌入,没有针对句子的直接表示,用于句子级的任务时通常计算成本较高。而SBERT基于 BERT,在其基础上添加池化层,能够能更好地生成语义上有意义的句子嵌入,通过计算余弦相似度或其他距离指标高效地计算句子或文本之间的相似度。
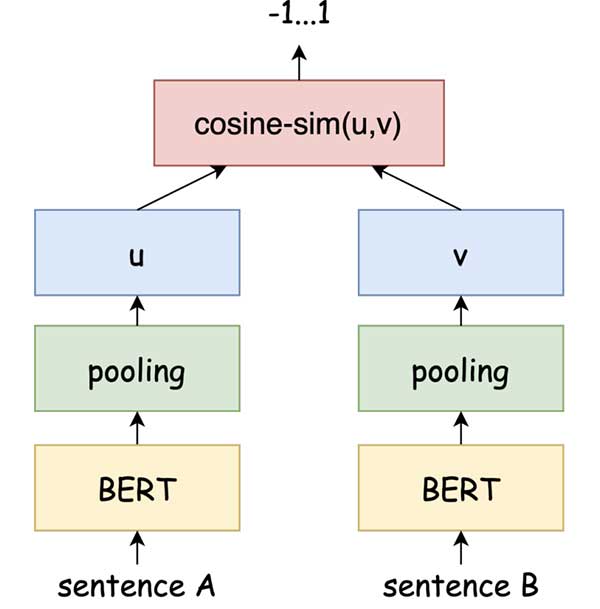
SBERT提供了丰富的预训练模型,这些模型通过海量样本训练得到。但在特定问题想要获得比较好的效果,通常需要对预训练模型进行微调。我们从大量直播弹幕中构建了数十万组句子对,基于预训练模型进行弹幕语义分析模型的训练。由于弹幕表达大多为非正式文本,或存在一些非字面意义的特定表达,如“PPT”、“矿卡”等也可以表达直播卡顿。而高质量训练数据对模型微调至关重要,所以我们在构建训练样本时花费了大量人力尽可能准确标记样本。另外,为了降低模型训练难度,我们将弹幕的卡顿识别和画质负反馈识别(如:画质模糊、掉帧、花屏等)分别进行独立的模型微调,而非集成在同一个模型上。相比起预训练模型,经过微调后的模型,在测试集上,识别准确率由60%左右提升到了95%以上。
直播弹幕语义分析模型已完成部署,服务框架如下图所示:
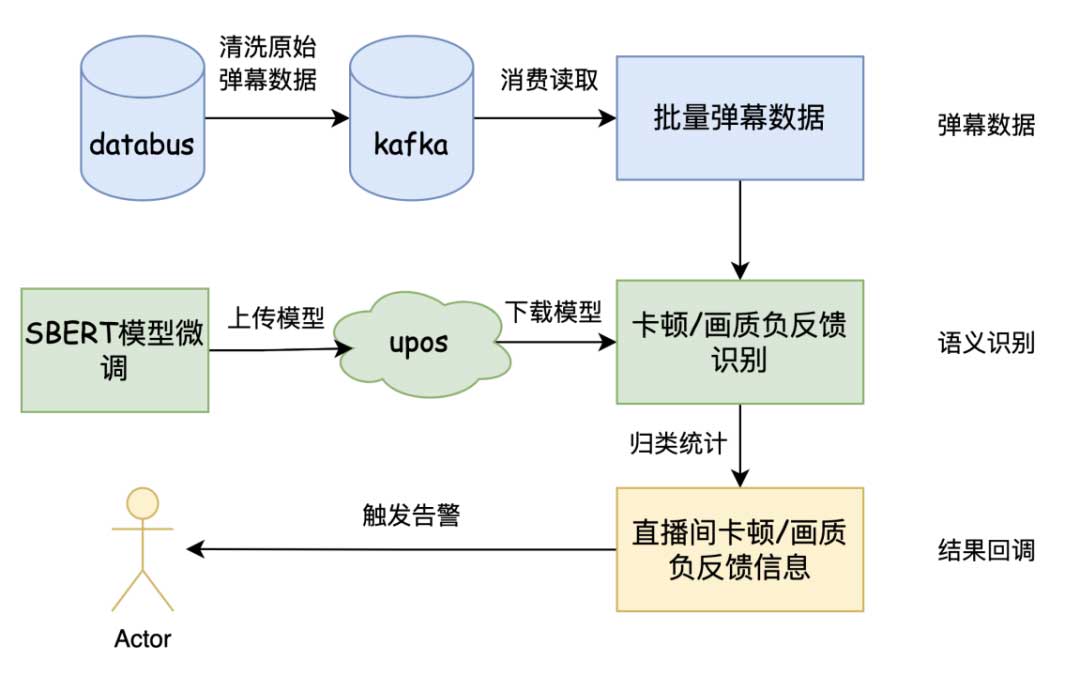
目前只针对头部直播间触发告警,线上触发卡顿告警示例如下:

除了直播弹幕语义分析,我们还在其他直播业务进行算法赋能的尝试。比如,直转点耗时预估,类似前文介绍的点播转码耗时预估,这里应用范围替换为直转点业务。再如,构建直播转码生产稳定评估模型,用于辅助相关技术人员排查直播生产中的问题。业务价值上类似于直播弹幕语义分析。但在直播弹幕语义分析中,从用户弹幕反馈作为输入训练相应模型,而直播生产稳定评估中,从转码生产的基础数据作为输入训练模型。两者信息源存在差异,但目的都是为了便于协助排查直播链路中的异常提升用户观看体验,这里不再详细展开。
总结展望
本文通过“点播优化转码决策”、“点播转码资源预估”、“转码耗时预估”和“直播弹幕语义分析”四个业务实例,具体介绍了如何借助算法赋能业务。通过算法赋能,各个业务上都取得了不错的效果。但各个模型效果仍存在提升空间,且随着实际业务的发展和变化,模型效果可能会出现劣化,因此还需要对已有的模型持续迭代提升。另外,由于实际业务问题种类分散,所需的模型种类也较多。因此我们正在进行模型训练测试框架的搭建,集成已有的算法能力,便于提高模型后续迭代效率和模型在不同业务问题上复用迁移。最后,我们仍然在努力挖掘基于点直播业务或更多业务上的算法赋能,如果有任何问题或想法欢迎随时联系我们。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
