
随着互联网和通讯技术的发展,实时的音频流传输已经成为网络通信的一个非常重要的部分。同时,由于各种因素,比如网络拥堵、带宽限制、硬件故障等,音频数据包在传输过程中可能会丢失,这会对语音通信的质量产生严重影响,造成用户体验下降。最近我们提出了一种针对全频段信号的频带分割丢包隐藏网络(BS-PLCNet),虽然它在ICASSP 2024 PLC挑战赛中取得并列第一的优异成绩,但BS-PLCNet是一个具有8.95G FLOPS的高计算复杂度的模型,仍有较大改进空间。
近期,西工大音频语音与语言处理研究组(ASLP@NPU)和字节跳动合作论文 “BS-PLCNet 2: Two-stage Band-split Packet Loss Concealment Network with Intra-model Knowledge Distillation” 被语音研究顶级会议INTERSPEECH2024接收。作为冠军模型的改进,我们设计了双路径编码器结构(具有非因果路径和因果路径),并利用模型内知识蒸馏策略将未来信息从非因果教师提炼到因果学生路径。BS-PLCNet 2只有BS-PLCNet 40%的参数量以及38%的计算量,在ICASSP 2024 PLC挑战盲集上获得了0.18的PLCMOS提升,实现了SOTA的性能。现对该论文进行简要的解读和分享。
论文题目:BS-PLCNet 2: Two-stage Band-split Packet Loss Concealment Network with Intra-model Knowledge Distillation
合作单位:字节跳动
作者列表:张子晗,夏咸军,黄传增,林丹峰,谢磊
论文Arxiv网址:https://arxiv.org/abs/2406.05961
Demo:https://zzhdzdz.github.io/BS-PLCNet2
背景动机
在过去的几年里,随着互联网的发展,再加上疫情的影响,网络电话语音(VoIP)技术逐渐成为我们日常生活中必不可少的一部分。然而,由于网络拥塞、时延和抖动、硬件故障等多种因素,音频数据包集在传输过程中可能会丢失,这会对语音通信的质量产生严重影响,造成用户体验下降。语音丢包补偿(Packet Loss Concealment,PLC)技术的主要目标是通过各种方式尽可能地恢复或掩饰丢失的数据包,从而保持语音通信的连续性和清晰度。
传统丢包补偿技术主要基于冗余编码或信号处理的插值等方式,如在许多编解码器中采用的前向纠错技术,当检测到不良网络条件时,发送方可以传输有关过去帧的冗余信息,以便恢复短丢包。该技术会引入额外的网络开销和额外的延迟,同时无法处理较长丢包。随着硬件和算法的进步与深度学习技术的发展,一种非常有前景的方法是通过神经网络进行 PLC。基于神经网络的深度PLC方法已经可以在16k Hz采样率实现低延迟的实时丢包补偿,且能够恢复的丢包长度与生成音频的质量都超越了传统算法[1]。然而,全带音频(48k Hz采样率)带来的高计算复杂度,使得高采样率音频的低延迟实时深度PLC仍是一个具有挑战性的问题。
在最近的ICASSP 2024 深度丢包隐藏挑战赛中,我们提出的BS-PLCNet[2]取得了并列第一的优异成绩,能够在20ms延时内实时处理全带音频,但其仍是一个具有8.95G FLOPS的高计算复杂度的模型。为了进一步降低参数量与计算量,同时提高对于长时丢包的补偿效果,我们提出了改进的BS-PLCNet2。我们设计了双路径编码器结构,并在丢包恢复后引入了一个轻量级的后处理模块,以恢复语音失真并去除音频信号中的残留噪声。BS-PLCNet2只有BS-PLCNet 40%的参数量以及38%的计算量,在ICASSP 2024 PLC挑战盲集上获得了0.18的PLCMOS提升。
BS-PLCNet 2
如图2所示,BS-PLCNet 2与BS-PLCNet遵循相同的设计思想,是一个频域模型,丢包音频经过STFT变换到频域,按照频率0-8K Hz与8-24K Hz分为两个频带,分别由宽带模块(Wide-band Module)和高频模块(High-band Module)处理。同时为节省计算量,后处理模块也仅对0-8K Hz的宽带做处理。
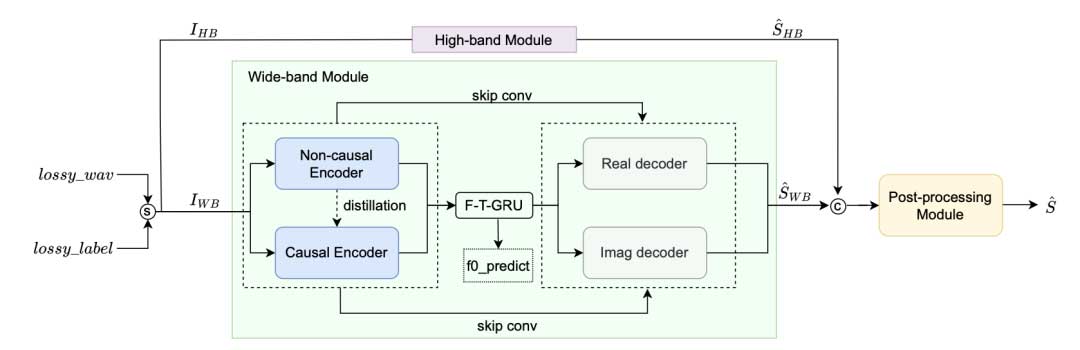


模型内蒸馏
由于因果的PLC模型仅能利用历史信息,与能够展望未来信息的非因果PLC模型相比,信息缺失不可避免的导致模型效果的下降。我们使用双路径卷积和模型内知识蒸馏来解决这个问题。类似的结构在自动语音识别(ASR)[3]和语音转换[4]中也产生了显著的效果。具体来说,双路径卷积基于深度可分离卷积,包含因果路径和非因果路径。在并行的深度卷积层中,通过修改深度卷积的填充模式,实现因果路径和非因果路径。在编码器的门控卷积模块和时频扩展卷积模块(TFDCM)中,所有时间方向上的卷积都被替换为双路径卷积,而其他模块保持不变并在非流式和流式推理中共享参数。在训练过程中,输入数据流并行通过两条不同的路径,并在编码器的输出计算蒸馏损失,使因果编码器输出尽可能接近非因果路径。
与师生(Teacher-Student)网络中典型的知识蒸馏不同,我们只在编码器的卷积层设计双路径,而其他层共享参数。因此,在训练过程中,解码器和瓶颈层可以同时接收因果输入和非因果输入,从而降低了知识迁移的难度。这种方法还允许我们在一个训练步骤中获得非因果与因果两个模型,避免了首先训练教师模型然后蒸馏学生模型的过程。采用模型内知识蒸馏策略,显著降低了训练成本。
网络优化与后处理
与BS-PLCNet相同,我们保留了生成对抗网络(GAN)架构。对于生成器,我们进行了以下改进。首先,我们用深度可分卷积层代替所有卷积层,以降低BS-PLCNet的计算复杂度。其次,修改TFDCM模块的层数。本文提出的层数是根据网络深度动态减少的,而不是采用[2]中固定的4层。随着神经网络层数的加深和特征维数的升高,膨胀卷积的层数相应减少,以适应更高维的信息,并允许更强地关注局部信息。最后,由于边际效应,反复堆叠同一层并不会带来明显的性能提升,经过实验,我们将三层F-T-LSTM替换为了单层F-T-GRU。
受多阶段语音增强网络的启发,我们还引入了一个后处理模块来处理潜在的失真。可能存在的噪音也在这个阶段被处理。考虑到整体计算复杂度的增加,后处理模块只处理0-8kHz频段,采用简单的基于GRU的结构。
实验
实验设置
- 实验数据:Librispeech[5],和第五届DNS竞赛数据集。
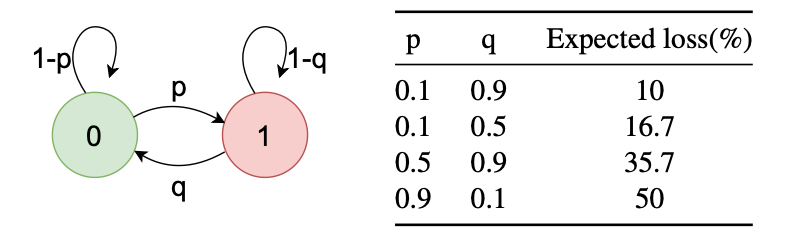
- 丢包仿真:如图3所示,Gilbert-Elliott模型使用两态一阶马尔可夫链来描述当前帧和下一帧的丢包状态,其中0表示无丢包,1表示存在丢包。如果当前帧传输正常,则下一帧丢失的概率为p。如果当前帧丢失,则下一帧不丢失的概率为q。通过设置p和q,可以将期望丢包率r控制为: r=p/(p+q)。这里我们设置p、q取10%-90%,丢包率小于50%。在第一个训练阶段,我们只模拟丢包。在第二训练阶段引入噪声(来自第五届DNS竞赛数据集),SNR设置为10-20dB。
- 测试集:ICASSP 2024 PLC Challenge盲测集和INTERSPEECH 2022 PLC Challenge盲测集。
实验结果
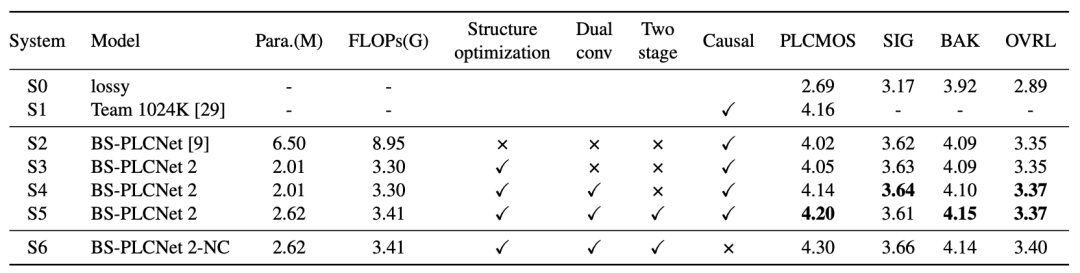
在表1中,我们对提出的方法在ICASSP 2024 PLC挑战赛盲测试集上进行了消融实验,并将其与在挑战赛中并列第一名的另外两个系统Team 1024K和BS-PLCNet进行了比较。对比S2与S3,改进的模型结构在复杂度大幅下降的同时保持了优秀的性能。S4在引入模型内蒸馏后PLCMOS从4.05显著提升到4.14。S5引入后处理模块提高了PLCMOS和DNSMOS,特别是BAK分数,而计算复杂度仅增加了0.11 GFLOPs。
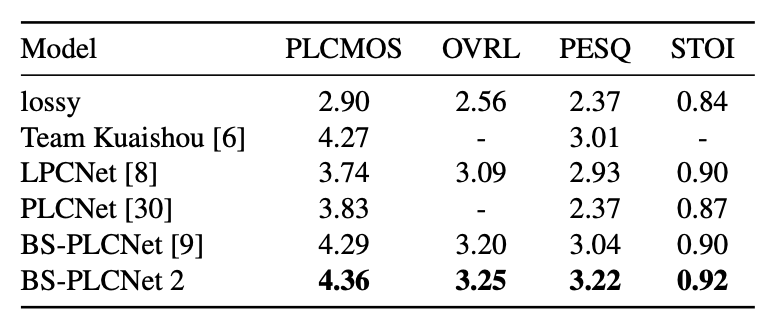
在表2中,我们还使用Interspeech 2022盲测集将我们的系统与挑战赛中排名前三的系统(Team Kuaishou, LPCNet和PLCNet)进行了比较,我们的系统仍然具有明显优势。
样例展示
样例1
未处理丢包音频
丢包补偿后音频
参考文献
[1] L. Diener, S. Sootla, S. Branets, A. Saabas, R. Aichner, and R. Cutler, Interspeech 2022 audio deep packet loss concealment challenge, Interspeech, 2022.
[2] Z. Zhang, J. Sun, X. Xia, C. Huang, Y. Xiao, and L. Xie, BS-PLCNet: Band-split packet loss concealment network with multi-task learning framework and multi-discriminators, ICASSP, 2024.
[3] C. Liang, X.-L.Zhang, B. Zhang, D. Wu, S. Li, X. Song, Z. Peng, and F. Pan, Fast-U2++: Fast and accurate end-to-end speech recognition in joint CTC/attention frames, ICASSP, 2023.
[4] Z. Ning, Y. Jiang, P. Zhu, J. Yao, S. Wang, L. Xie, and M. Bi, DualVC: Dual-mode voice conversion using intra-model knowledge distillation and hybrid predictive coding, ICASSP, 2023.
[5] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, Librispeech: an ASR corpus based on public domain audio books, ICASSP, 2015.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。