
分享音视频技术社群关键帧的音视频开发圈整理的音视频面试题集锦第 25 期。
下面是第 24 期面试题精选,我们来讲讲直播相关功能技术方案:
- 1、直播美颜如何实现?
- 2、直播间礼物特效的如何实现?
- 3、直播连麦的如何实现?
- 4、直播间的回声消除如何实现?
1、直播美颜如何实现?
下面是实现美颜的一种思路:
- 1、降采样。对输入图像进行降采样,缩小其分辨率为
256 * 256。目的是为了加快处理速度,提升算法性能。 - 2、均值模糊。对上一步的结果进行卷积核为
9 * 9的均值模糊,并拆分成水平方向和垂直方向上先后分别进行一次均值模糊,计算量由9 * 9 = 81降为9 + 9 = 18。 - 3、高反差保留。利用模糊后的图和原图做 diff,计算得到图像的高低频信息,将高低频信息用 frame buffer 的 alpha 通道存储,将均值模糊的结果用 rgb 通道存储,以此来减少 draw call 和 GPU 显存占用。
- 4、对步骤 3 结果中的 alpha 通道数据进行均值模糊,同样分为横向和纵向。
- 5、将人脸 mask 静态素材贴到人脸位置。此步骤是为后续做锐化和降噪做铺垫,这里可能会有性能问题,可以根据机型性能选择性开启。
- 6、磨皮。根据输入图的 rgb 计算肤色概率。综合肤色概率、人脸 mask、高低频信息,得到混合系数 kMin,计算磨皮系数
smoothSkinResult = mix(inputColor, blurColor, kMin)进行磨皮。 - 7、对非人脸 mask 区域进行降噪处理。
- 8、锐化。
- 9、美白。使用单张 lut 图进行颜色映射。
2、直播间礼物特效的如何实现?
下面是实现直播间礼物特效的一种思路:
- 1、通过制作 Alpha 通道分离的视频素材;
- 2、在客户端上通过 OpenGL 重新实现 Alpha 通道和 RGB 通道的混合,从而实现在端上播放带透明通道的视频。
3、直播连麦的如何实现?
下面是一种在客户端合流的直播连麦方案:
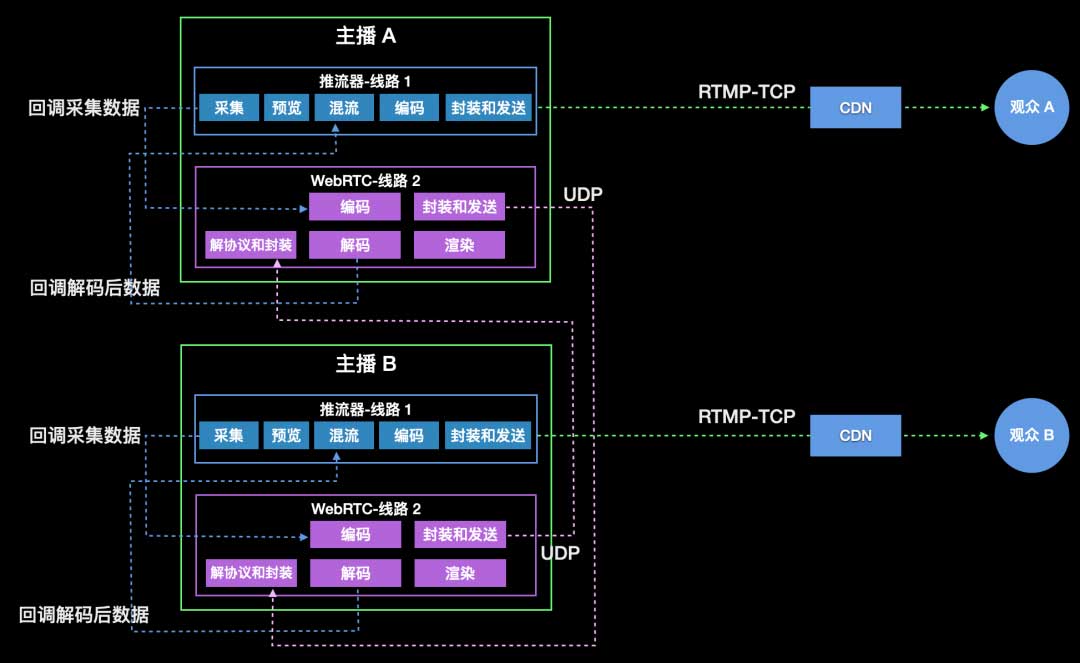

直播连麦在客户端进行合流时,主播端一方面使用 WebRTC 和远端主播连麦通信,一方面使用推流器进行合流和推流操作。其中需要注意:
- WebRTC 采集模块、编码模块要提供数据回调接口和推流器对接。
- WebRTC 回声消除模块要与推流器对接。
- WebRTC 给推流器回调解码后数据(PCM、YUV/Texture)。这个数据是要和播放效果一致的数据,即已回声消除或倍速,如果上抛 texture,要共用 OpenGL context。
- WebRTC 解决底层依赖的编译库冲突问题,FFmpeg、OpenSSL 等。
- 推流器在连麦和非连麦模式切换时,要支持推不同的分辨率和码率,并且刷新 SPS、PPS 信息。
- 播放端要支持直播流在分辨率变化时能够正常切换画面。这里可以通过探测到 SPS、PPS 中的分辨率信息变化时,来刷新解码器。
4、直播间的回声消除如何实现?
直播中发现有回声,可能有如下原因:
- 1、主播在直播的同时用其他设备看自己的直播并且声音外放,这种情况下,外放的直播间声音又被主播自己的麦克风采集再次传输到观众端,观众端连续听到直播间相同的声音,这就是一种回声,这种回声要经过直播延时、传输延时,整体延时可能会达到 6-10s 左右。
- 2、主播在直播的同时用自己的手机外放音乐,这种情况下,如果这个音乐音频有被合成进直播流,而同时又由于音乐外放被麦克风采集到,这时候直播流中就会有两个音乐声,这两个音乐声有一定的延时,通常大概 1s 左右,这就会让直播观众听到回声。
- 3、主播连麦也是容易产生回声的场景。主播 A 的声音传输到主播 B 端,主播 B 的设备如果外放连麦声音,就会将主播 A 的声音采集到再传回给主播 A,主播 A 收到这个声音就会听到自己刚才的说话声,这就是回声。如果还有观众在观看主播 A 的直播间,观众也会听到重复的主播 A 的声音,也是回声。这里需要注意的是虽然听到的是主播 A 的回声,但原因是其实是主播 B 端造成的。
一个常见的回声消除系统一般会包含这些核心模块,如图所示:
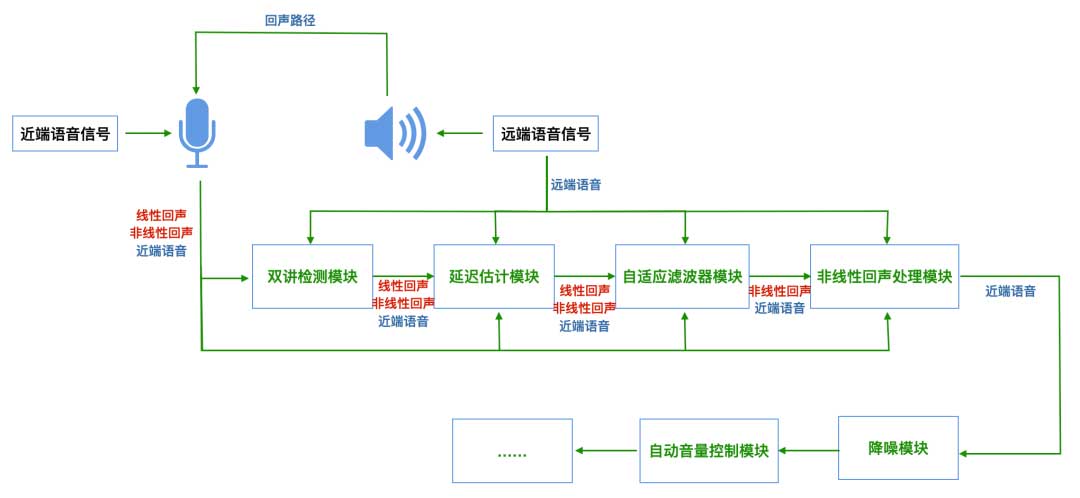
- 双讲检测模块。这里主要是计算麦克风采集的音频信号和对端传过来的音频信号的相关性。如果相关性较高超过一定阈值,则判断麦克风输入的主要是回声;如果相关性较低,则判断麦克风输入的有其他声音。在双讲判断有回声的情况下,接下来就会开始做回声消除了。
- 延迟估计模块。该模块用于估计回声的延时,这个延时对后面进行回声处理很有用。延迟估计比较简单的做法是移动远端音频信号的起始位置,然后和回声信号计算相关性,并找到相关性最大的位置,即我们计算得到的延迟。
- 自适应滤波器模块。回声一般分为线性回声和非线性回声,自适应滤波模块一般用来消除线性回声。自适应滤波的过程就是通过更新声音信号评估公式的系数来找到和麦克风音频信号(认为是回声)最为接近的一组系数,并将公式在该系数下计算的信号从麦克风音频信号中减去,从而消除线性回声。
- 非线性回声处理模块。非线性回声处理模块则用来消除非线性回声。该模块利用前面估计的线性回声信号和经验知识生成估计的非线性回声信号,并在音频信号中减去估计的信号,从而消除非线性回声。这里的经验知识主要是指非线性回声生成原因,手机上主要是扬声器失真。
- 降噪模块。通常一个回声消除系统在做完回声消除后还会做一下降噪,这里的降噪可以包含传统的降噪算法处理来去除一些背景噪声,以及用深度学习降噪算法去掉一些特定噪声。
- 自动音量控制模块。降噪做完后,还可以做一下自动音量控制,将音频信号中声音过小或过大的部分尽量拉平。当然这个模块要放在降噪模块后面,要不然噪音可能会被放大。
总结来讲,一个简单的回声消除系统,通过输入的对端语音信号、麦克风采集的录音信号,经过双讲判断来计算是否有回声,当有回声时会估计回声的延时,并通过自适应滤波器模块消除线性回声,通过非线性回声估计模块消除非线性回声,从而实现回声消除的目的。在消除噪声后,还可以选择性的做一下降噪和自动音量控制来提升音频质量。
更多的音视频知识、面试题、技术方案干货可以进群来看:

版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。