
最近看书学习过程中做了一些笔记,分别和大家一起分享一下,今天首先分享的是H264的帧内预测。
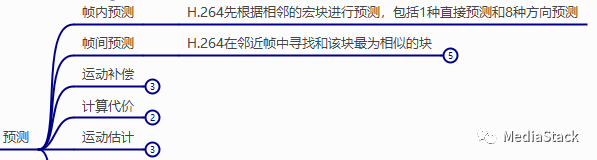
H.264/AVC 标准中规定的 4×4 亮度块的帧内预测样本预测创建方法。如下图所示,有 9 种方向预测模式。未显示的预测模式 2 表示 DC 预测。
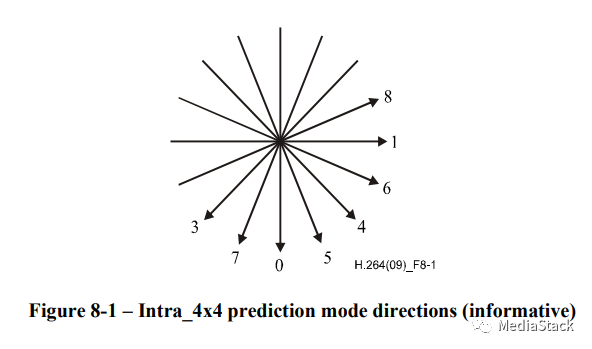
预测器是通过在每个模式的箭头方向上外推要编码的块周围的重建像素来创建的,在标准的8.3章节有做一些介绍:

本文以4*4的帧内预测为例,其相关预测种类可以参考如下表格:

单独看这个可以有一定理解,我们以实际效果图可以更好的理解相关内容,参考如下链接:
https://emericdev.files.wordpress.com/2011/08/intrapred4x4.png
https://www.google.com.hk/url?sa=i&url=https%3A%2F%2Fwww.nveo.org%2Findex.php%2Fjournal%2Farticle%2Fdownload%2F3278%2F2700&psig=AOvVaw2kDcVYU0ytaL7Zp0KZN4fq&ust=1696897220554000&source=images&cd=vfe&opi=89978449&ved=2ahUKEwjbk9fx2OeBAxWTPkQIHayvDzYQr4kDegQIARBv
直接看标准是枯燥乏味的,比如 Intra4x4PredMode解析过程

所以个人一般是看着标准,对着代码,方便理解,甚至有时候进行编译,增加log调试整个流程,进一步掌握相关逻辑。
FFMPEG阅读
FFMPEG定义
借鉴FFMPEG中相关逻辑,介绍如何初始化过程,然后简单介绍帧内预测的函数。
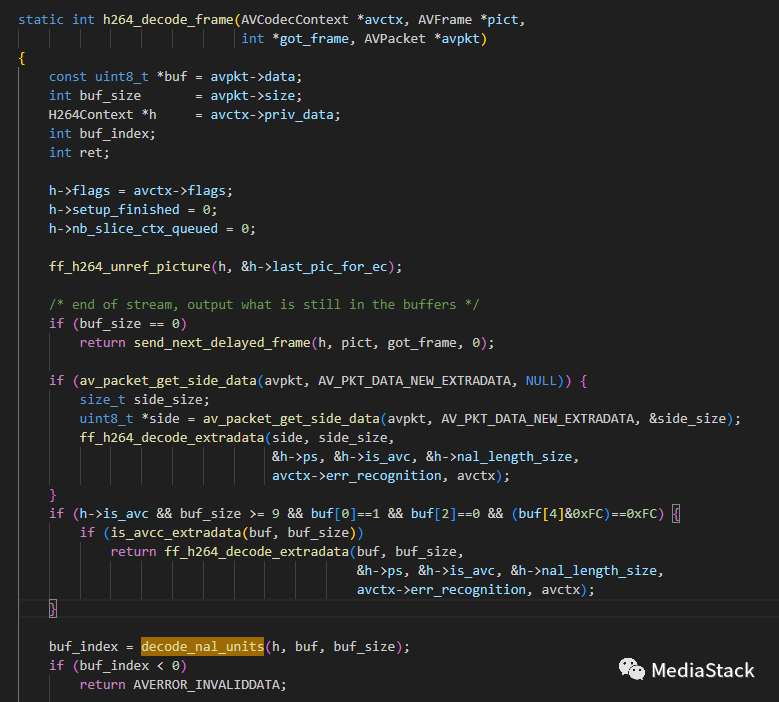
h264_decode_frame()
这个函数会从AVPacket中提取压缩数据,然后调用适当的解码函数(如decode_nal_units)来解码数据。解码后的帧会存储在AVFrame结构体中,并通过设置got_frame来指示已经成功解码了一帧。最后,这个函数可能会返回一个错误代码,以指示解码过程是否成功。
decode_nal_units()
该函数会遍历输入数据,识别并解析每个NAL单元,然后根据NAL单元的类型进行相应的解码操作,这时会调用ff_h264_queue_decode_slice接口;
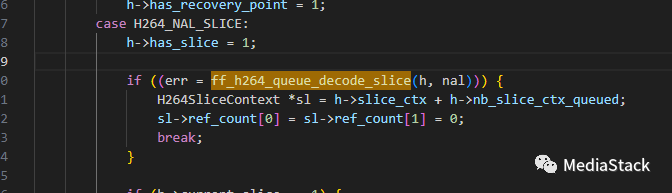
ff_h264_queue_decode_slice()
该函数会将H264NAL结构体中的切片数据加入到H264Context结构体中的解码队列中。然后,在适当的时机,这些切片会被取出并解码。最后,这个函数可能会返回一个错误代码,以指示解码过程是否成功。
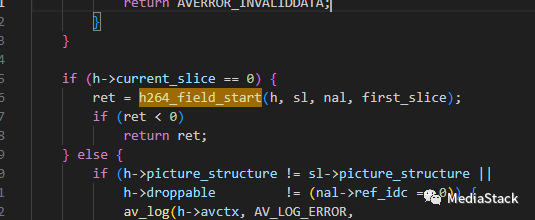
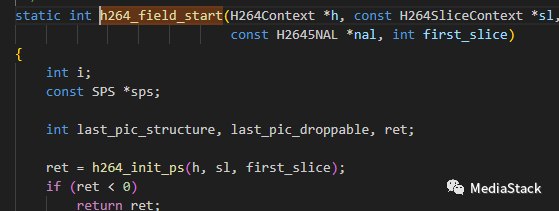
h264_field_start()
该函数解码一个场(或帧)中的第一个切片的切片头部之后被调用。它决定我们是在解码一个新的帧还是在解码场中的第二个场,并进行必要的设置。
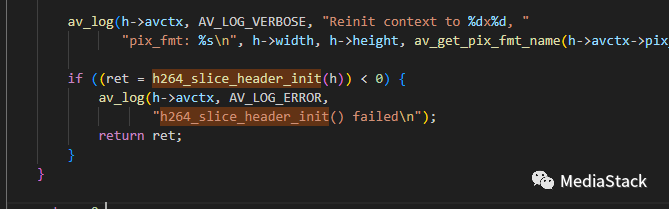
h264_slice_header_init()
该函数用于初始化H.264视频编码中的切片头部。
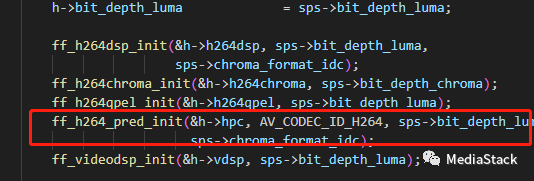
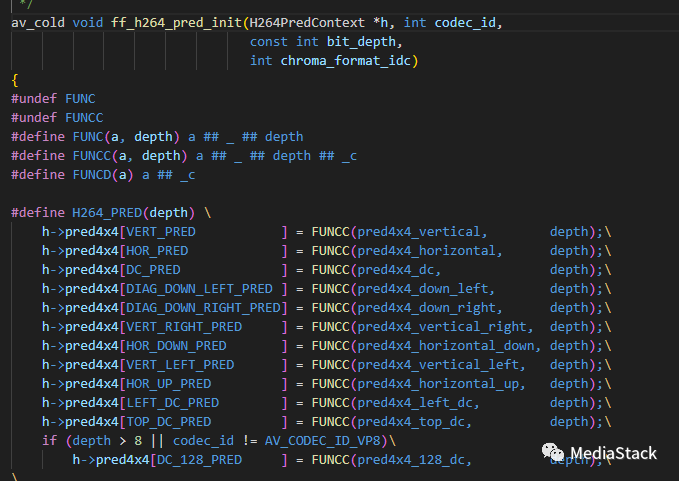
ff_h264_pred_init()
该函数的作用是初始化预测相关的数据结构和参数。内部设置了帧内预测函数指针。具体来说,就是定义了一系列的预测类型,包括垂直预测(VERT_PRED)、水平预测(HOR_PRED)、DC预测(DC_PRED)等等。这些预测类型都被用于H.264的预测功能。
pred4x4_vertical()
这是视频编码库 FFmpeg 中的一个函数,可对 4×4 像素块执行垂直预测。该函数返回一个指向预测的 4×4 像素块的指针。
首先将输入参数转换为适当的类型和单位。
然后,使用AV_RN4PA宏从源数据(src-stride)中读取4个像素值,并将其存储在变量a中。这四个像素值来自当前块上方的行。
接下来,使用AV_WN4PA宏将这四个像素值复制到当前块的每一行。这样,当前块的所有像素都被设置为与其上方相同的值,从而实现了垂直预测。
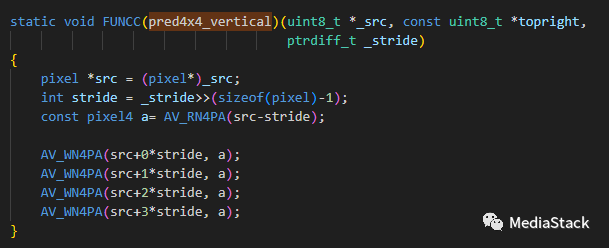
和标准中的解释基本一致,相互促进理解

再比如pred4x4_dc函数
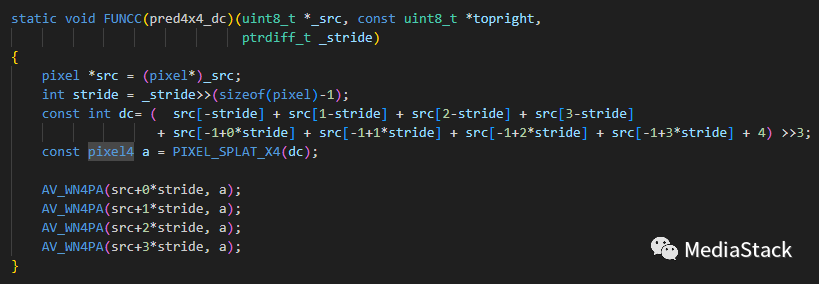
首先将输入参数转换为适当的类型和单位。然后,计算DC值,即当前块上方和左侧像素值的平均值。这是通过对上方四个像素和左侧四个像素求和,然后除以8(右移3位)来实现的。接下来,使用PIXEL_SPLAT_X4宏将DC值复制到一个pixel4类型的变量a中。最后,使用AV_WN4PA宏将变量a的值复制到当前块的每一行。这样,当前块的所有像素都被设置为与其周围相同的值(即DC值),从而实现了DC预测。

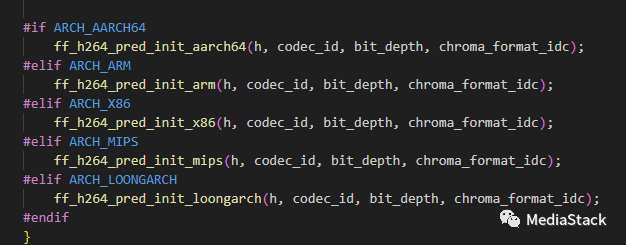
ff_h264_pred_init接下来有一段条件编译块,根据不同的 CPU 架构选择调用不同的函数进行 H.264 解码器的预测初始化。
ARCH_AARCH64、ARCH_ARM、ARCH_X86、ARCH_MIPS 和 ARCH_LOONGARCH 是表示不同 CPU 架构的宏定义。根据当前所使用的 CPU 架构,只有符合条件的代码块会被编译和执行。
下面是每个条件中调用的函数解释:
- ff_h264_pred_init_aarch64():针对 AArch64 架构,执行 H.264 解码器的预测初始化。
- ff_h264_pred_init_arm():针对 ARM 架构,执行 H.264 解码器的预测初始化。
- ff_h264_pred_init_x86():针对 x86 架构,执行 H.264 解码器的预测初始化。
- ff_h264_pred_init_mips():针对 MIPS 架构,执行 H.264 解码器的预测初始化。
- ff_h264_pred_init_loongarch():针对 LoongArch 架构,执行 H.264 解码器的预测初始化。
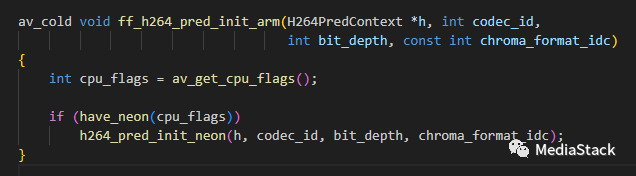
我们以arm为例:
h264_pred_init_neon 函数用于在 NEON 架构下执行 H.264 解码器的预测初始化。NEON 是 ARM 架构的一种向量处理扩展,提供了SIMD(单指令多数据)功能,用于加速音视频处理等任务。
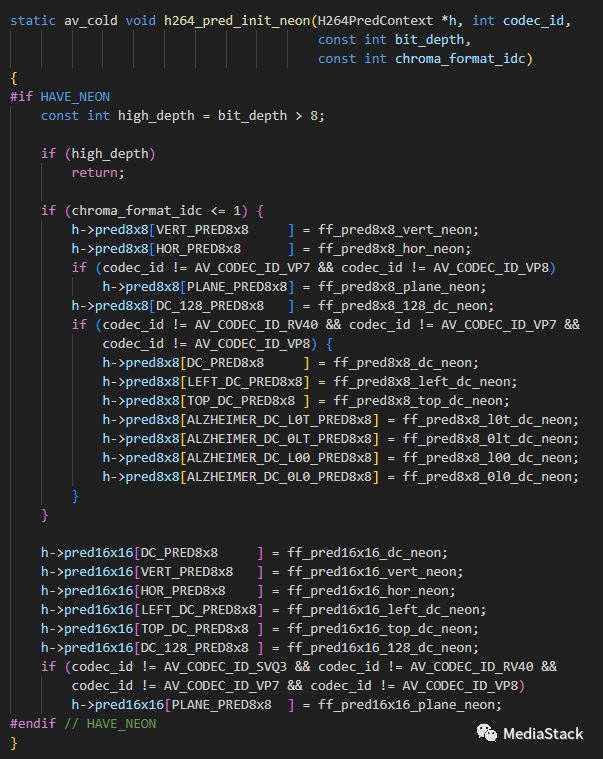
ff_pred8x8_hor_neon函数首先计算源数据(x0-x1)的位置,并将其存储在x2中。然后,将跨度(x1)左移一位,相当于乘以2,因为每个像素占用两个字节。接下来,使用ld1指令从源数据(x2)中加载8个字节(即一个8×8块的上方行),并将其存储在向量寄存器v0中。然后,进入一个循环,将向量寄存器v0中的值复制到当前块的每一行。这是通过使用st1指令将v0中的值存储到目标位置(x0和x2),并更新目标位置来实现的。循环执行4次,因此当前块的所有行都被设置为与其上方相同的值。
至此帧内预测的流程简单介绍完成。
补充知识
SIMD指令
SIMD 是 Single Instruction, Multiple Data(单指令多数据)的缩写,它是一种并行计算技术。SIMD 指令集提供了在单个指令中同时对多个数据元素执行相同操作的能力。
传统的指令集架构执行的是一条指令针对一个数据操作,而 SIMD 指令集通过在一条指令中同时处理多个数据元素,能够显著加快对向量或数组等数据结构的处理速度。这对于许多需要大量重复计算的任务非常有用,例如图像和视频处理、数字信号处理、科学计算等领域。
使用 SIMD 指令集可以将计算任务分解成多个并行的操作,从而充分利用现代处理器中的多个计算单元(如向量寄存器),提高程序的运行效率。每个 SIMD 操作都会对一组数据元素应用相同的算术、逻辑或其他操作。
不同的处理器架构有不同的 SIMD 指令集,如 x86 架构的 SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)和 ARM 架构的 NEON 等。这些指令集为开发人员提供了直接使用 SIMD 功能的底层指令,或者通过编译器内置的向量化优化来自动利用 SIMD 指令集。
可以参考如下链接更多理解SIMD指令:
https://blog.csdn.net/qq_32916805/article/details/117637192
最后想说的是要想非常清晰理解每一种预测的优缺点,需要针对性跟踪相关代码,这个只能自己多动手了,只有亲自动手并跟踪相关代码,才能真正深入理解每种预测方法的优缺点。同时,这也是我们不断进步和提高的必经之路。保持对技术的热情和好奇心,不断学习和探索,相信未来一定会更加美好。
作者信息:我是一枚爱跑步的程序猿,维护公众号和知乎专栏《MediaStack》,有兴趣可以关注,一起学习音视频知识,时不时分享实战经验。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
