
上一篇介绍了DTMF的基本原理,本文以WebRTC中代码进行代码层面的解读,以便能够更好地理解DTMF。
Demo
基本框图如下:
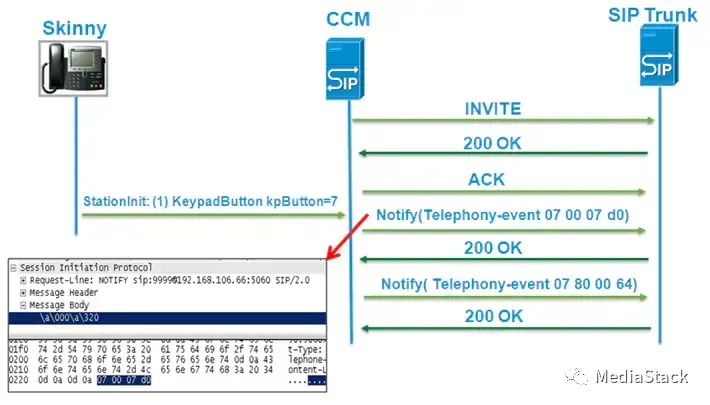
代码走读
Webrtc作为一个开源工具,已经提供了丰富的demo,关于DTMF的相关Demo可以参考如下链接:
https://github.com/webrtc/samples/blob/gh-pages/src/content/peerconnection/dtmf/js/main.js
网页发送
通过main.js我们可以看到发送tone音的接口:
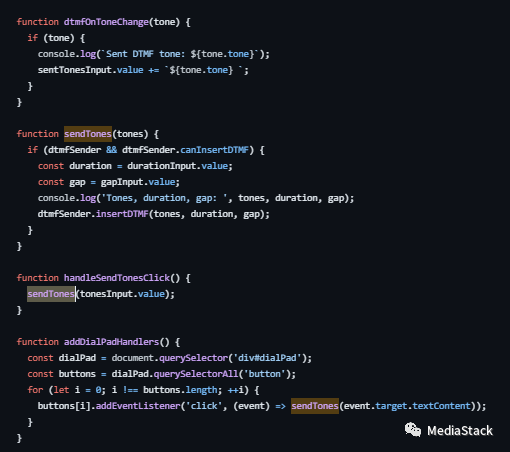
当然在webrtc的代码中也有类似的单元测试实例,相关发送流程类似:
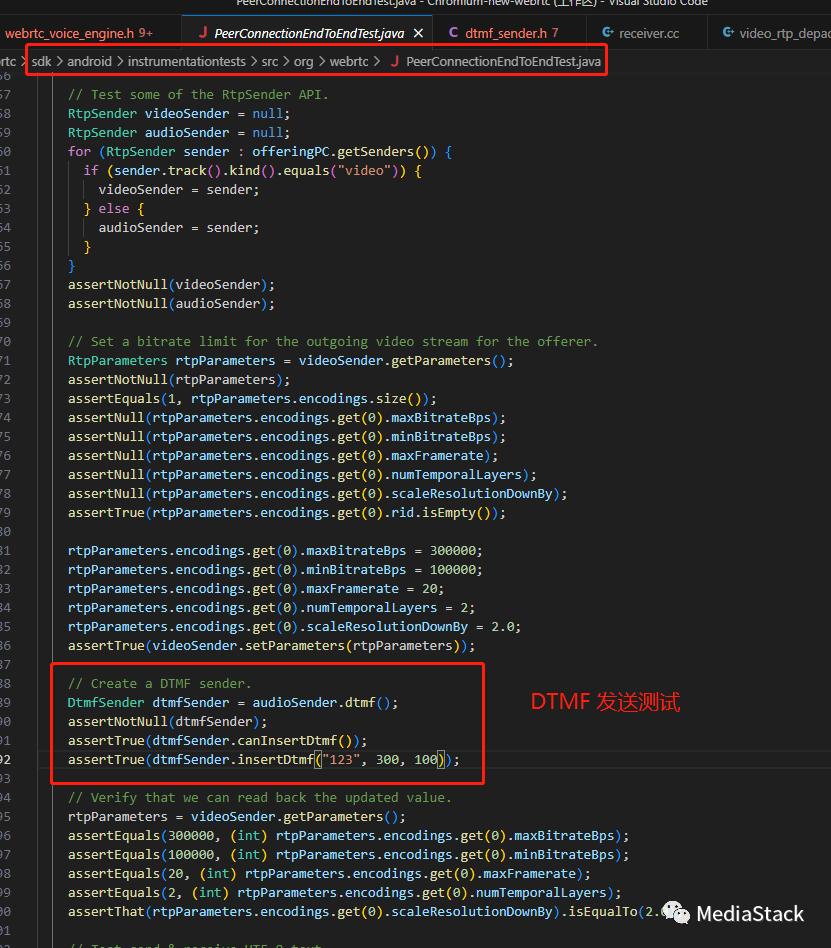
最终都是调用到底层Native层进行相关操作:
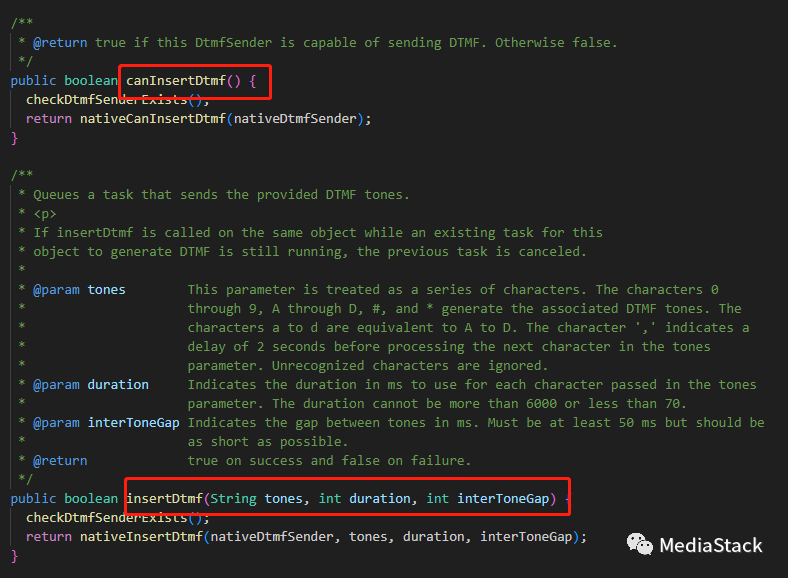
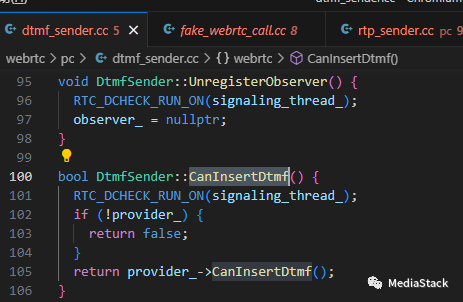
CanInsertDtmf()
CanInsertDtmf()该函数用于检查 DTMF 发送方是否可以插入 DTMF 音。该函数首先检查提供者是否已设置。如果不是,该函数返回 false。如果设置了提供程序,该函数将调用提供程序上的 CanInsertDtmf() 方法。如果提供者可以插入 DTMF 音调,则 CanInsertDtmf() 方法返回 true,否则返回 false。

InsertDtmf()
InsertDtmf()该函数功能用于在呼叫中插入 DTMF 音。

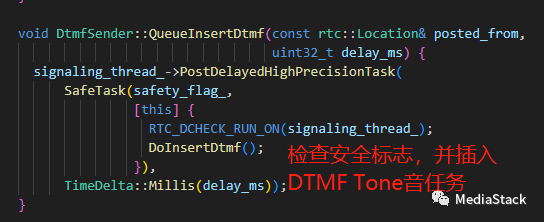
DtmfSender::QueueInsertDtmf()
QueueInsertDtmf() 用于对插入 DTMF 音调的任务进行排队。该任务计划在指定的延迟后运行。该任务将首先检查安全标志是否仍然有效。如果不是,任务将自行取消。如果安全标志仍然有效,任务将调用 DoInsertDtmf() 方法。DoInsertDtmf() 方法将在呼叫中插入 DTMF 音调。
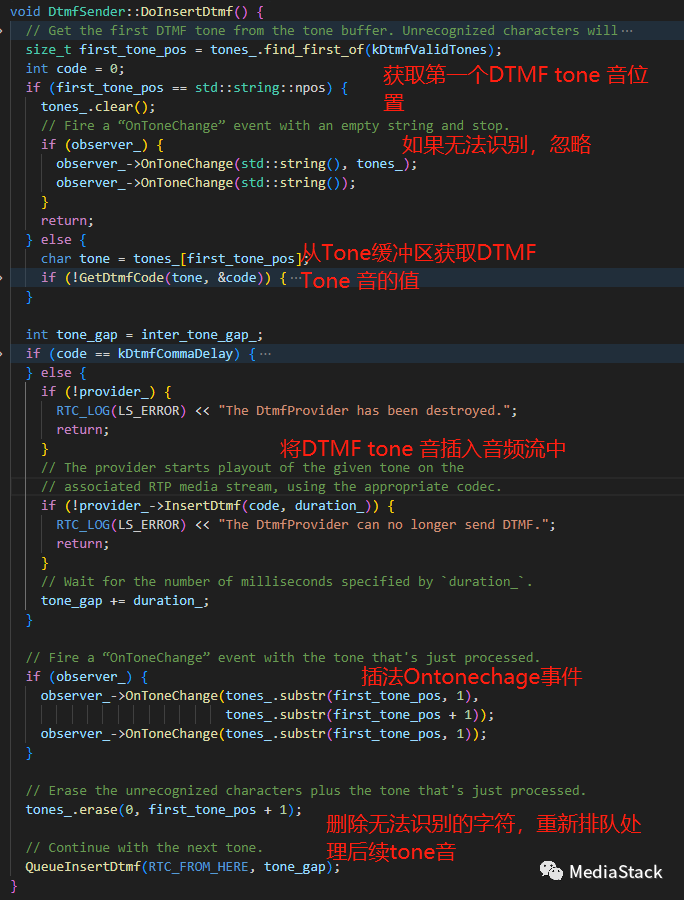
DoInsertDtmf()
DoInsertDtmf负责将 DTMF 音插入音频流。该函数首先从音调缓冲区获取第一个 DTMF 音调。如果无法识别该音调,则会忽略并跳过该音调。否则,该函数将获取音调的 DTMF 代码并将其插入到音频流中。该函数还使用刚刚处理过的音调触发“OnToneChange”事件。最后,该函数擦除无法识别的字符以及刚刚从音调缓冲区中处理的音调,并将另一个调用排队到 DoInsertDtmf 以继续处理音调。
InsertDtmf()
InsertDtmf()用于调用对应的audiochannel完成TelephoneEvent事件插入。
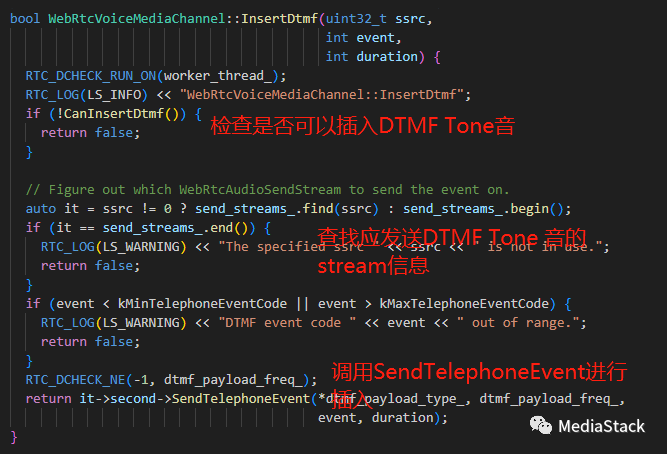
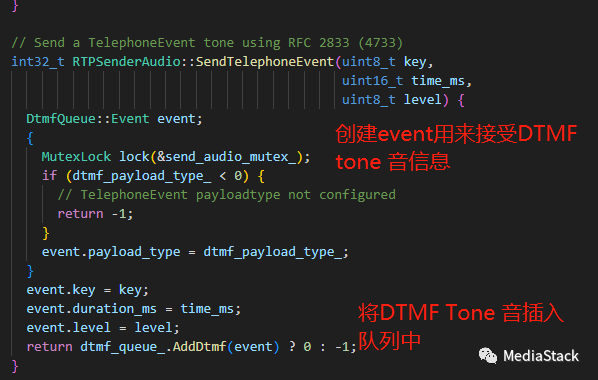
SendTelephoneEvent()
SendTelephoneEvent 负责使用 RFC 2833 (4733) 发送 DTMF 音。
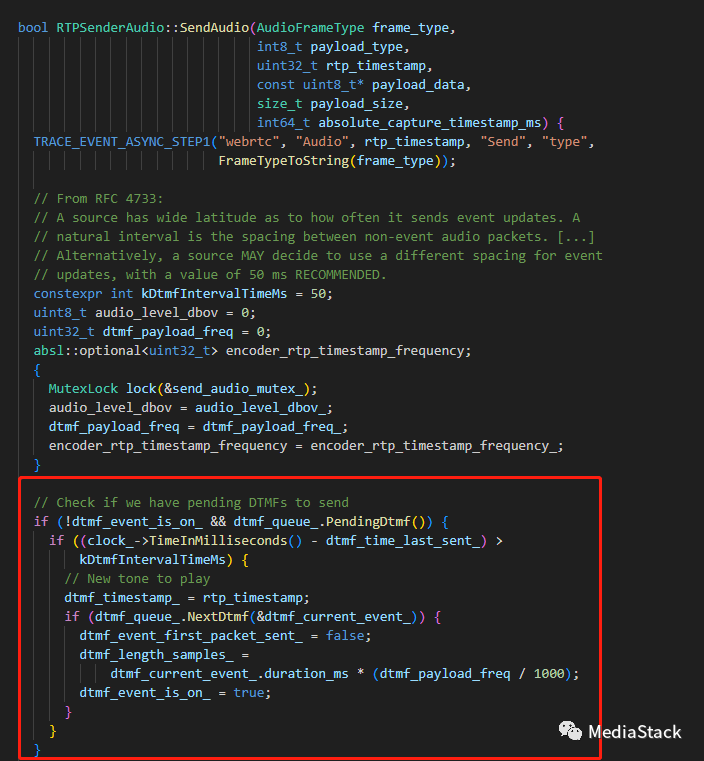
SendAudio()
SendAudio()在检查是否有任何待发送的 DTMF 音调。如果有,代码会检查自上次发送 DTMF 音以来的时间是否大于 DTMF 间隔时间。如果是,代码会从 DTMF 队列中获取下一个 DTMF 音并开始发送。
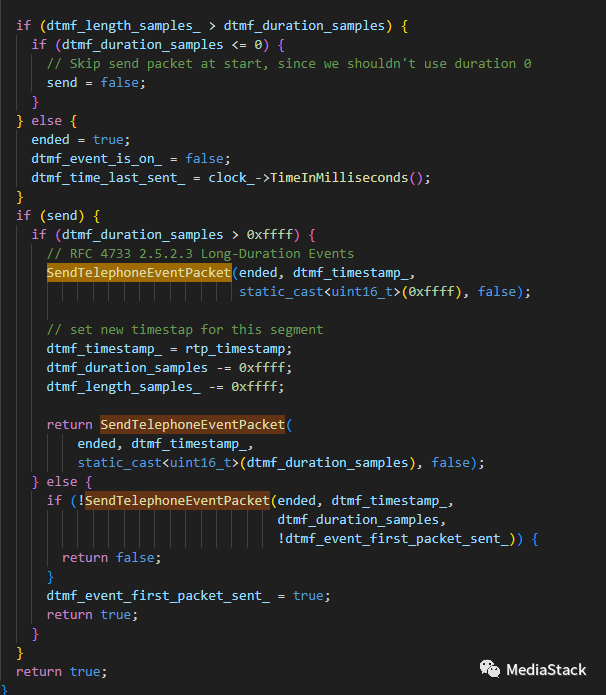
接下来检查是否应该发送 DTMF 数据包。如果应发送数据包,代码会检查 DTMF 音是否为长持续时间音。如果是,代码会将 DTMF 音调分成两个数据包,并一次发送一个数据包
SendTelephoneEventPacket()
RTPSenderAudio 类中 SendTelephoneEventPacket 方法的实现。该方法负责向网络发送 DTMF 数据包。
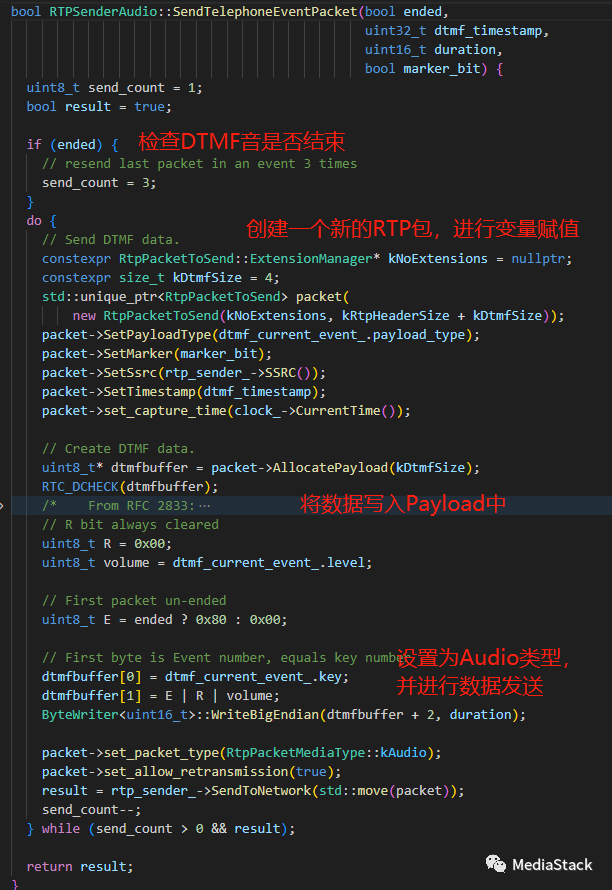
至于packet的发送,基本上没啥难点了,自行理解即可。
接收DTMF
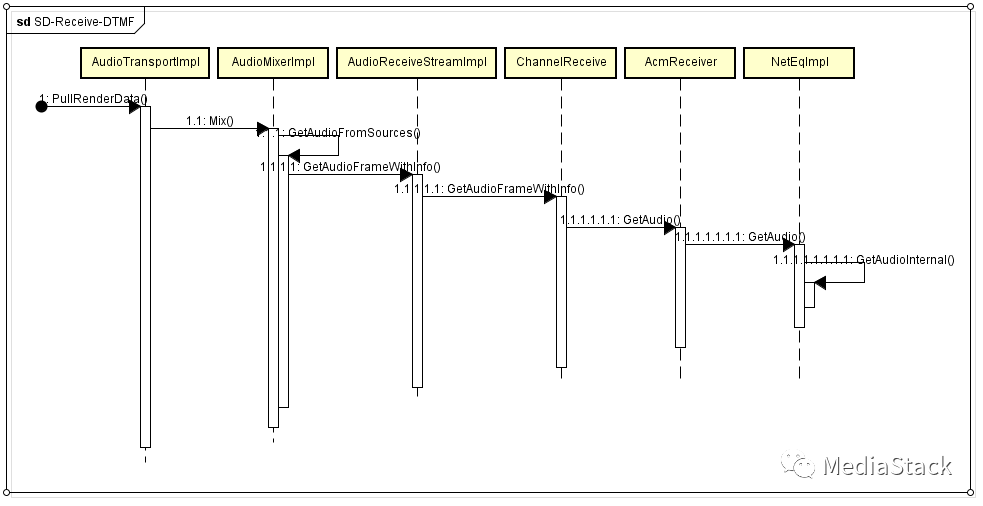
关于接收端DTMF的部分属于Webrtc的流程,本文不做详细展开,主要关注如何处理,以及如何产生,其他流程简单画一个序列图,有兴趣的可以自行查阅源码。
NetEqImpl 类的 GetAudioInternal() 函数。该函数负责从 NetEq 获取音频数据。
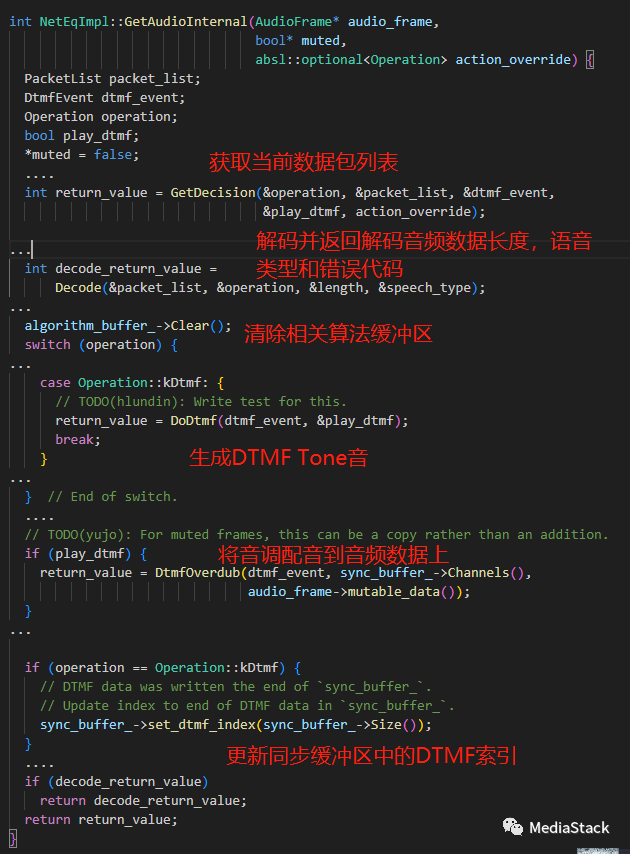
GetDecision()
GetDecision() 函数获取当前数据包列表,以及当前音频类型,是否是DTMF Event,以及是否播放等信息。

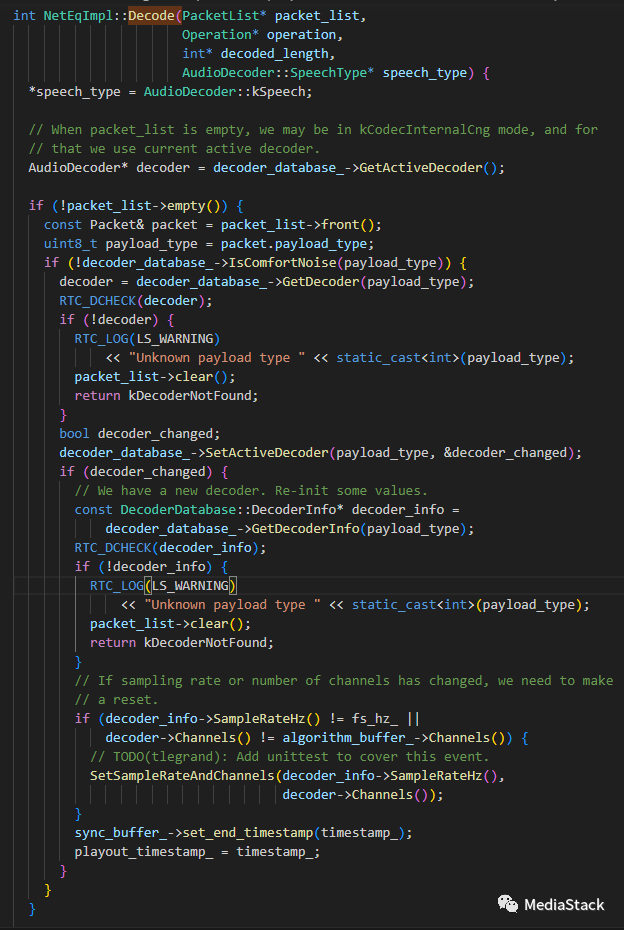
Decode()
NetEqImpl 类的 Decode() 函数。 该函数负责解码音频数据。
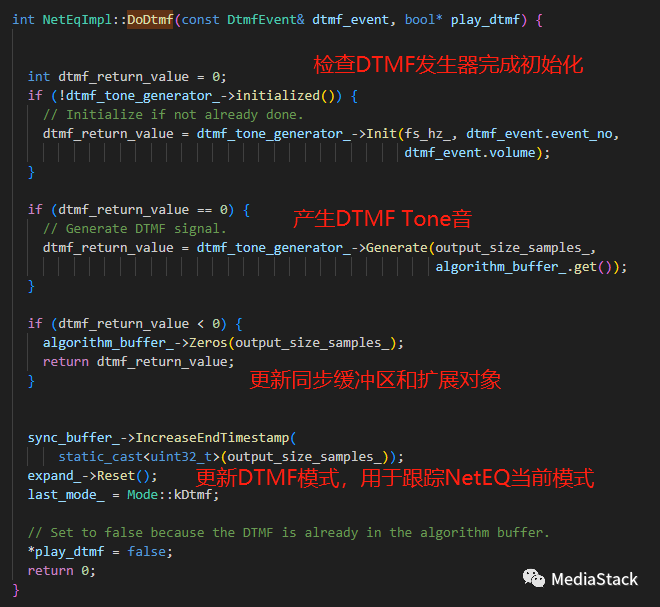
DoDtmf()
NetEqImpl 类的 DoDtmf() 函数。该函数处理 NetEq 中的 DTMF 音调。
到此从接收到音频文件的判断流程基本上走通,剩下就是如何生成和播放DTMF Tone音了。
变量和函数
介绍如何生成DTMF tone音之前,先说明一下相关参数和结构变量:
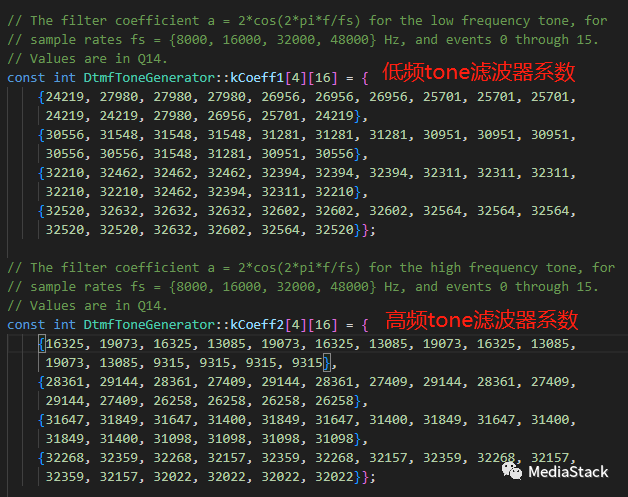
(1)低频和高频Tone滤波系数
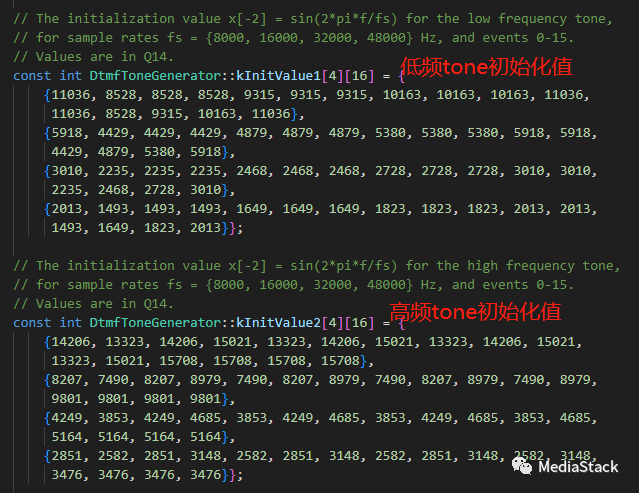
(2)低频和高频Tone初始化值
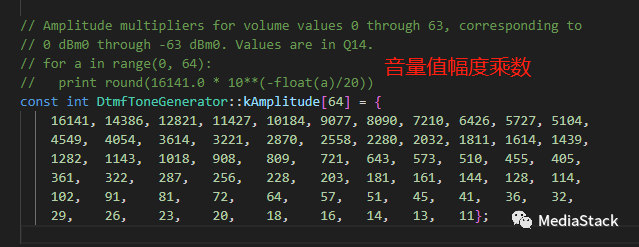
(3)音量值幅度乘数
(4)DTMFToneGenerator类
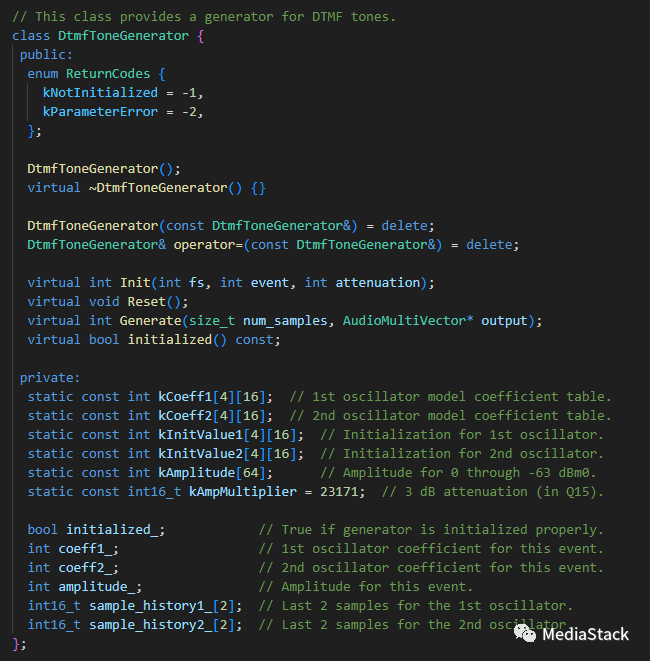
DTMFToneGenerator的变量含义如下:
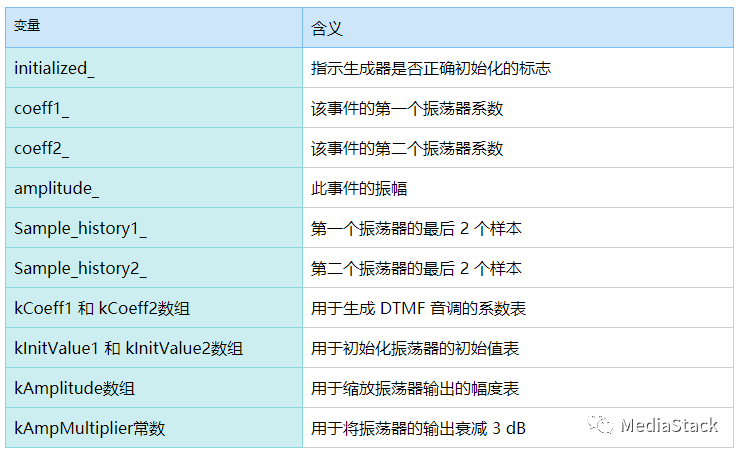
DoDtmf()
NetEqImpl 类的 DoDtmf() 函数。该函数处理 NetEq 中的 DTMF 音调。
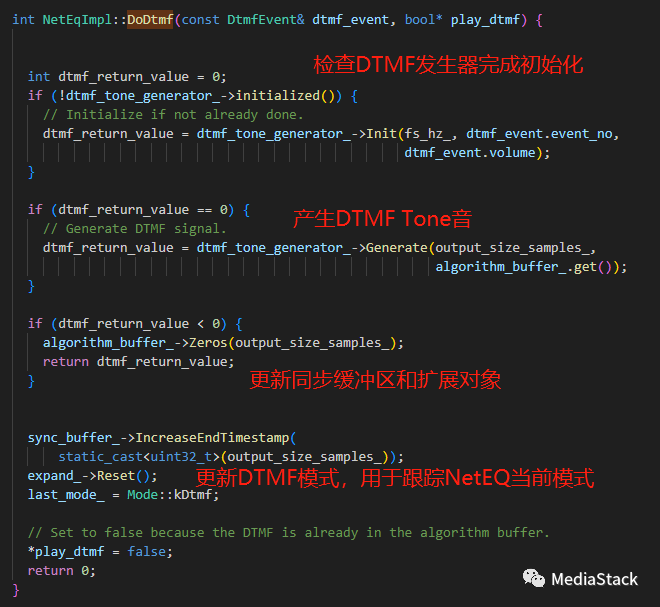
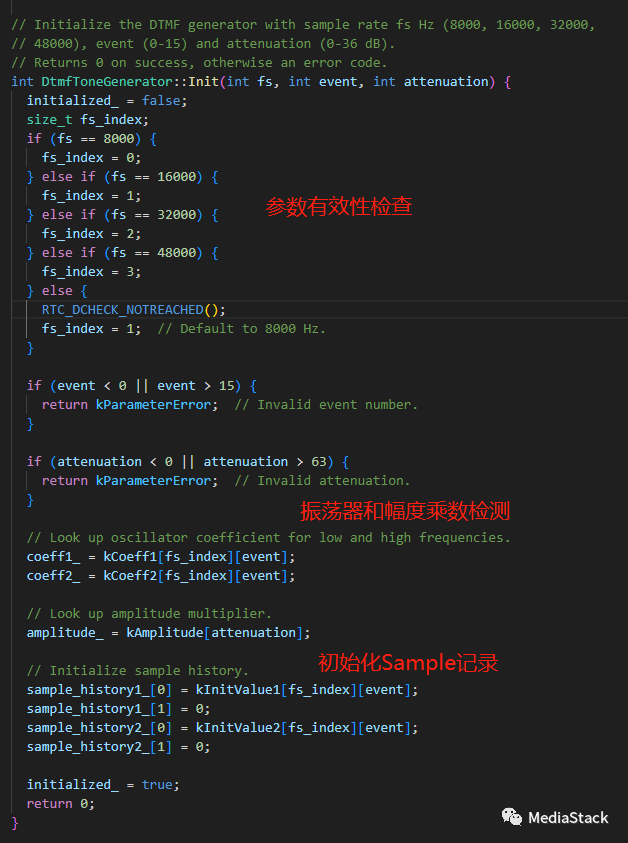
Init()
DtmfToneGenerator 类的 Init() 函数。此类用于生成 DTMF 音,即用于在电话上拨号的音。
Generate()
DtmfToneGenerator 类的Generate() 函数。该函数生成 DTMF 音并将其写入输出音频缓冲区。
生成 DTMF 音调是通过使用递归公式计算样本值来实现此目的。递归公式为Goertzel算法:
y[n] = a * y[n – 1] – y[n – 2]
其中 y[n] 是第 n 个样本的值,a 是递归系数,y[n – 1] 和 y[n – 2] 是前两个样本的值。
补充知识
Q14选择:为了更快的计算正弦波,采用定点小数表示,本例中使用16bit,也就是short型的整数来表示定点小数, Q14的定点小数能表示-2到2的取值范围,对于本例的正弦波计算正好合适,具体解释可以参考如下文章:
https://blog.csdn.net/junwua/article/details/83504584
其中关于定点小数的表示可以参考如下文章:
https://www.cnblogs.com/cdaniu/p/16388091.html
关于 Goertzel算法解释:
https://www.cnblogs.com/haibin-zhang/p/5515607.html
更详细的解释参考维基百科:
https://en.wikipedia.org/wiki/Goertzel_algorithm
我是一枚爱跑步的程序猿,维护公众号和知乎专栏《MediaStack》,有兴趣可以关注,一起学习音视频知识,时不时分享实战经验。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
