
亚马逊 Chime SDK 使开发者能够将通信功能添加到他们的应用程序中。该 SDK 的一个重要功能是能够应用机器学习来增强音频和视频会话。客户还利用机器学习从这些会话中获得智能洞察。我们将深入探讨客户如何在他们的通信服务中使用实时机器学习能力。
来源:RTC@Scale 2023
讲述人:Sid Rao
视频:https://atscaleconference.com/videos/using-machine-learning-to-enrich-and-analyze-real-time-communications/
内容整理:王怡闻
在丢包网络中利用机器学习来升级音频会话
传统方法
在当前的 WebRTC 中,我们有一种机制来对音频进行冗余编码。如果存在丢包,音频可以通过不同的终端进行重建。这个机制是通过 RTC2198 实现的,我们通过 BRTB 传递冗余的音频数据包,以恢复大约 20 秒的丢失音频间隙。我们根据会话中观察到的丢包情况来调整此过程。随着丢包增加,我们开始发送更多的冗余数据包,并且只在有语音活动时发送冗余数据。这种冗余机制是开发者解决最后一英里和丢包网络问题的传统方式。然而,其中的问题是,如果网络上存在丢包,通常原因是由于无线接入拥塞。如果开始发送冗余数据包,那只会加剧拥塞问题。虽然发送冗余数据包是解决问题最简单的方法,也是目前在 WebRTC 中解决问题的方式,但可能并不是最佳方式,尤其是当涉及到 WiFi 引起的丢包或在移动设备上在不同无线基站之间漫游导致的丢包问题。
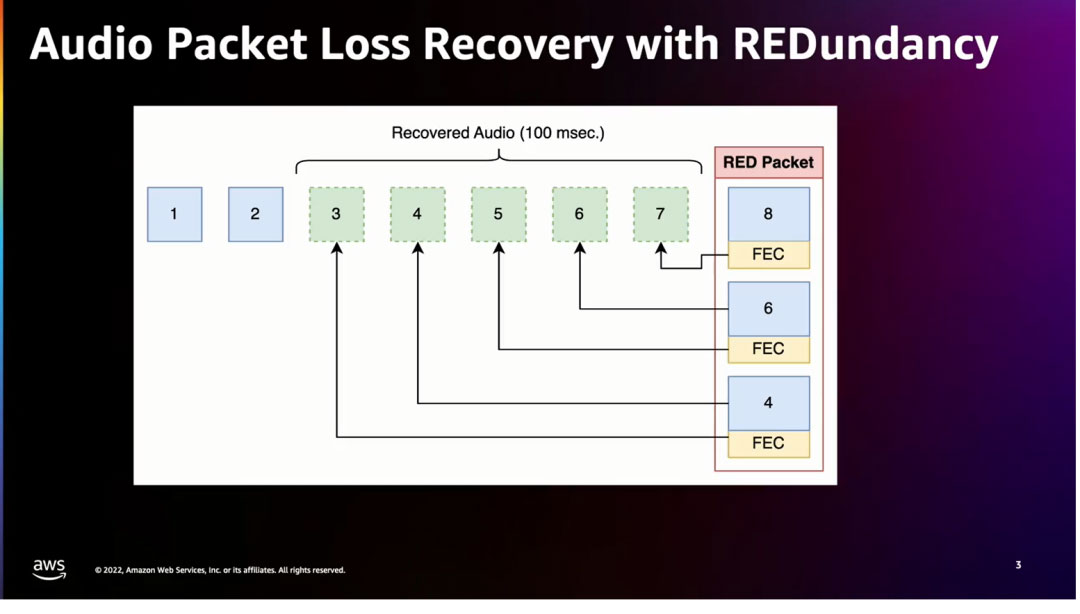
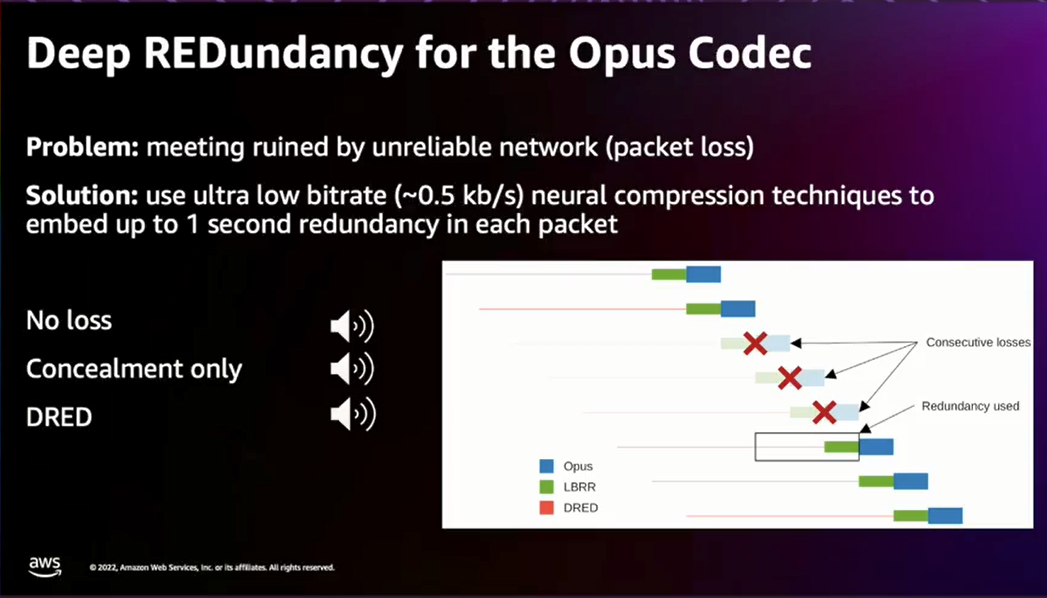
引入机器学习的改进方法
目前的 Opus Codec 支持丢包修复。它有一个机制,在一些音频数据上进行冗余编码,并在数据缺失时尝试重建这些数据。Opus Codec 数据包中还有一小段填充空间,该填充空间实际上可以用来编码底层音频的机器学习构造。然后,我们可以从这些构造中重建可能丢失的音频会话数据包。例如,如果丢失了 500 毫秒的音频数据,每个数据包包含了 1 秒的音频编码,可以用来替换那 500 毫秒的音频数据包。
帮助客户从他们的音频和视频会话中获得洞察力
T Mobile 拥有 6 万名客服代理,它利用 Amazon Chime SDK 从他们现有的基于 CISCO Call Manager 和 CISCO Context 的平台中提取音频。它使用 SDK 提取音频后,对音频进行了转录,并从中检测主题和情感,然后实时地向客服代理推送关于如何更好处理话题的信息。例如,当客户遗失手机时,他们可以提供一篇知识库文章,帮助客服代理解决问题;如果存在常见的账单问题,可以通过几个不同的步骤来解决,他们可以直接向客服代理推送相关信息。这使得客服代理更加高效和专业,减少了通话处理时间,并提高了客户在联系中心的满意度。
接下来要展示的 demo 是基于我们为 T-Mobile 所做的转录技术,但我们在其中添加了身份识别。说话人识别的工作原理是从音频中提取一小段样本,生成音频的嵌入,并在数据库中搜索相似的嵌入,从而推断出实际上是谁在说话。这在混合音频视频会议中非常有用,当您有一系列参与者从不同的终端加入会议时,但对于房间类型的环境,您不知道谁在说话。您可能会面对多个不同声音的人。我们能够确定在这些混合环境中用户的身份对于我们的客户非常有用。不过目前也存在一些问题,一个是发言人数量目前还没有测试过上限;另外,说话人识别模型目前不支持重叠发言人。
提升现有的电信系统
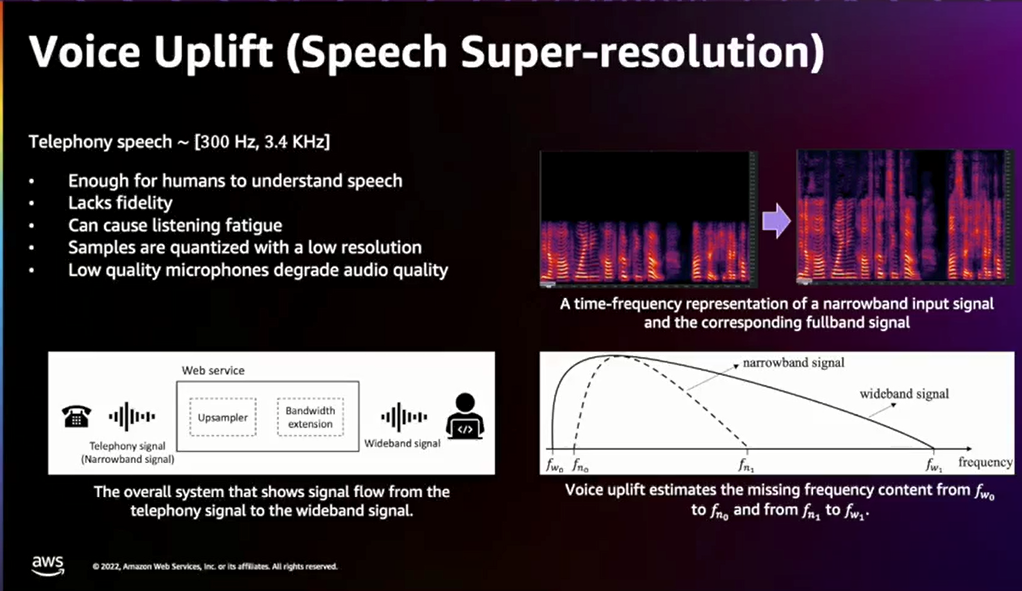
在 Amazon Chime SDK 中,有许多客户使用现有的电信系统,并希望与 SDK 进行集成,通常使用会话初始化协议。他们可能使用 CISCO 呼叫管理器和台式电话环境,并希望以与浏览器端点相同的效率参与音频和视频会话。然而,由于互操作性的需要,这些传统的遗留平台通常只支持 G.711 编解码器,有时可能支持 G.722。但是这些音频的分辨率明显较低,不如基于浏览器的终端所提供的高分辨率音频。为此,我们提供了一种升级机制,可以将源音频的分辨率从8kHz提高到24kHz或48kHz,从而使来自传统电信系统的客户能够以高质量的音频参与实时通信会话,享受高质量的宽带音频体验。
总结
首先,我们使用机器学习来处理丢包网络,并以 Opus Codec 的下一代形式提供丢包隐藏功能。其次,我们利用机器学习来获取对话洞察力,并利用一个 demo 演示了如何在多方音频会话中识别用户,可以使用这些身份数据来丰富其他机器学习应用,如情感检测或主题检测。第三,是从传统的电信平台中获取低窄带音频,并将其升级为更适用于现代 WebRTC 会话的宽带音频。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
