
用过音视频会议或在线教育等实时交互软件的人都知道,当摄像头(Camera)或麦克风(Micphone)开启时,首先要进行检测。检测内容包括:
- 电脑/手机上有哪些音视频设备?
- 我们选择的音视频设备是否可用?
以手机为例,一般包括前置摄像头和后置摄像头。我们可以根据自己的需要选择开启不同的摄像头。当然,手机上不仅有多个摄像头,还有更多种类的麦克风,比如:
- 系统内置麦克风
- 外接耳机
- 蓝牙耳机
- ……
以上所有设备均可手动或自动开启。
那么,WebRTC有没有提供相关的接口,方便我们查看自己机器上有哪些音视频设备呢?答案是肯定的。
下面我们就来看看如何在浏览器下使用WebRTC API来显示我们的音视频设备。
WebRTC处理
在正式讲解之前,我们先来回顾一下WebRTC的整体处理图,这样大家就可以清楚的知道我们这篇文章在整个处理过程中处于什么位置。
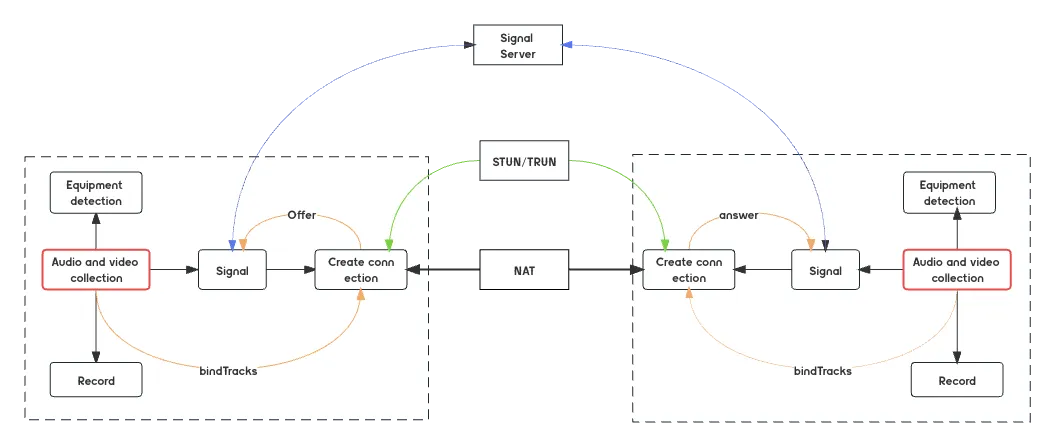
上图与第一篇文章从零开始搭建直播系统01——如何通过浏览器访问摄像头中的几乎相同。不同的是我把图中的两个音视频设备检测模块设置为红色。
这样一来,我们在本文中介绍的内容适合整个 WebRTC 流程的哪些部分一目了然!
音视频设备的基本原理
说完音视频设备,我们顺便介绍一下音视频设备的基本工作原理。了解这些设备的工作原理,对您后续学习音视频相关知识有很大的帮助。
音响设备
音频有采样率和采样大小的概念。其实这两个概念都离不开音响设备。
音频输入设备的主要工作是采集音频数据,而采集音频数据的本质是模数转换(A/D),将模拟信号转换为数字信号。
用于模数转换的采集定理称为奈奎斯特定理,如下:
在模拟/数字信号转换过程中,当采样率大于信号中最高频率的两倍时,采样后的数字信号完全保留了原始信号中的信息。
我们知道,人类听觉范围的频率在 20Hz 到 20kHz 之间。对于日常的语音通信(如电话),8kHz的采样率可以满足人们的需要。但是为了追求高品质和高保真,需要将音频输入设备的采样率设置在40kHz以上,这样才能完整的保留原始信号。比如我们平时听的数字音乐,通常都有44.1k、48k等采样率,以保证无损音质。
然后将收集到的数据进行量化和编码以形成数字信号,这就是音频设备应该做的事情。在量化和编码过程中,样本大小(每个样本中存储的二进制位数)决定了每个样本可以表示的最大范围。如果采样大小为8位,则表示的最大值为2 8 -1,即255;如果是16位,代表的最大值是65535。
视频设备
至于视频设备,它与音频输入设备非常相似。当物理光通过镜头到达相机时,会通过视频设备的模数转换(A/D)模块,即光学传感器,将光转换为数字信号,即RGB (红、绿、蓝)数据。
得到RGB数据后,需要通过DSP(Digital Signal Processor)进行优化,比如自动增强、白平衡、色彩饱和度等,都是这个阶段要做的。
经过DSP优化处理,得到24位真彩画面。因为每种颜色由8位组成,而一个像素是由RGB三种颜色组成的,所以一个像素需要用24位来表示,所以称为24位真彩色。
另外,此时得到的RGB图像只是临时数据。由于最终的图像数据需要经过压缩传输,而编码器一般使用的输入格式是YUV I420,所以相机内部也有专门的模块,用于将RGB图像转换成YUV格式图像。
那么什么是YUV?YUV也是一种颜色编码方式,主要用于电视系统和模拟视频领域。它将亮度信息 (Y) 与颜色信息 (UV) 分开。即使没有 UV 信息,它也可以显示完整的图像,但它只是黑白的。这种设计解决了彩色电视机和黑白电视机的兼容性问题。
YUV格式还是比较复杂的。它有几种存储方式,需要一整篇文章详细介绍。因此,我不会在这里一一描述。如果想进一步了解它的相关知识,可以在网上搜索相关资料,自行学习。
通过上面的讲解,现在你应该对音频设备和视频设备有了一个基本的了解。
WebRTC设备管理的基本概念
在讲解如何通过浏览器的WebRTC API获取音视频设备之前,我们先了解一下WebRTC关于设备的几个基本概念。如果不明确这些基本概念,就很难理解后面的知识。
MediaDevices,它提供访问(连接到计算机)媒体设备(例如相机、麦克风)和捕获屏幕的方法。事实上,它允许您访问任何硬件媒体设备。而我们想通过这个接口中的方法获取可用的音视频设备列表。
MediaDeviceInfo,表示每个输入/输出设备的信息。包含以下三个重要属性:
- deviceID,设备的唯一标识符;
- label,设备名称;
- kind ,设备的类型,可以用来识别是音频设备还是视频设备,是输入设备还是输出设备。
请注意,出于安全原因,label字段始终为空,除非已授予用户访问媒体设备的权限(这需要 HTTPS 请求)。
此外,label还可以作为指纹识别机制的一部分来识别合法用户。我们稍后会讨论这一点。
获取音视频设备列表
有了以上的基础知识,你就可以轻松的理解下面的内容了。首先我们看一下WebRTC在浏览器上获取音视频设备列表的界面。格式如下:
MediaDevices.enumerateDevices()可以调用MediaDevices的enumerateDevices()方法获取媒体输入输出设备列表,比如麦克风、摄像头、耳机等,是不是很简单?
该函数返回一个Promise对象。我们只需要给它的then部分传递一个函数,就可以通过这个函数得到所有的音视频设备信息。
传入的函数有一个参数,是一个MediaDeviceInfo类型的数组,用于存放WebRTC获取到的各个音视频设备的信息。
这可能有点抽象,让我们用下面的代码来看一个具体的例子。
"use client";
import { useEffect, useState } from "react";
const MediaDevicesPage = () => {
const [deviceInfos, setDeviceInfos] = useState<MediaDeviceInfo[]>([]);
const [errMsg, setErrMsg] = useState("");
const initialize = async () => {
// Determine if the browser supports these APIs
if (!navigator.mediaDevices || !navigator.mediaDevices.enumerateDevices) {
setErrMsg("enumerateDevices() not supported.");
return;
}
try {
// media device info list
const deviceInfos = await navigator.mediaDevices.enumerateDevices();
setDeviceInfos(deviceInfos);
} catch (e) {
setErrMsg((e as Error).message);
}
};
useEffect(() => {
initialize();
}, []);
return (
<div className="text-black ">
<h2 className="py-10 text-lg font-semibold text-center">
Media devices in your device
</h2>
<div className="px-10">
{errMsg ? (
<p className="py-4 text-center">{errMsg}</p>
) : (
<ul>
{deviceInfos.map((item) => (
<li className="mb-4" key={item.deviceId}>
<p className="mb-2">
kind: <span>{item.label}</span>
</p>
<p className="mb-2">
id: <span>{item.deviceId}</span>
</p>
</li>
))}
</ul>
)}
</div>
</div>
);
};
export default MediaDevicesPage;综上所述,上面的代码做了以下事情:
- 首先判断浏览器是否支持MediaDevice接口(旧浏览器可能不支持),如果不支持,说明原因。
- 如果支持,调用
navigator.mediaDevices.enumerateDevices()获取音视频设备列表的方法,该方法会返回一个Promise对象。 - 如果返回的Promise对象成功,则显示每个MediaDeviceInfo中的基本信息,也就是我们想要的每个音视频设备的基本信息。
- 但如果失败,则显示错误消息。
设备检测
获取电脑/手机上的所有设备信息后,我们就可以对设备的可用性进行实测。在我们的设备列表中,可以通过MediaDeviceInfo结构体中的kind字段将设备分类为音频设备或者视频设备。
对于区分音频设备和视频设备,每种不同的设备也设置了自己的默认设备。仍以耳机的音频设备为例。耳机插入电脑后,耳机成为默认音频设备;拔出耳机后,默认设备切换为系统音频设备。
因此,在获取到所有的设备列表后,如果我们直接调用《从零开始搭建直播系统01——如何通过浏览器访问摄像头》一文中介绍的getUserMedia接口来采集音视频数据,无需指定具体设备, 将从设备列表中的默认设备收集数据。当然,我们可以使用 MediaDeviceInfo 中的 deviceID 字段来指定从哪个特定设备收集数据,但那是另一回事了。
第一次调用getUserMedia接口只采集视频数据并展示。如果用户能看到自己的视频,则视频设备有效;否则,该设备无效,可以重新选择不同的视频设备进行重新检测。
第二次,如果用户视频检测通过,再次调用getUserMedia接口时,将只采集音频数据。由于无法直接显示音频数据,因此需要使用JavaScript中的AudioContext对象对采集到的音频进行计算,然后绘制到页面上。这样,当用户看到音频值发生变化时,就说明音频设备也有效了。
通过以上步骤,我们就完成了对指定音视频设备的检测。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/yinshipin/27560.html
