
随着视频会议、视频直播的流行以及未来AR/VR业务的发展,低延迟视频传输服务被广泛使用,但视频质量(QoE)还不能满足用户要求。那么近年来新兴的AI神经网络是否能为视频传输带来智能化的优化?今天LiveVideoStack大会北京站邀请了来自北京邮电大学的周安福教授,为我们分享关于使用强化学习方法进行低延迟视频传输的相关研究成果 。
文/周安福
编辑/LiveVideoStack
原文/https://mp.weixin.qq.com/s/JcZ9va4OhUUJ6c9IKOOpqQ
大家好,我是来自北邮的周安福,非常高兴有机会和大家分享我们的工作。由于我身在学术界,所以还请各位工业界同仁多提宝贵意见。我本次报告的标题为:强化学习驱动的低延迟视频传输研究。
在正式开始前想先简单提一句,自1986年至今,在四十多年的时间里,视频传输拥塞控制一直是从业者们面临的一个经典问题。随着近年来新兴AI产业的发展与升级,我们自然希望利用人工智能方法对视频传输工作进行优化,但要如何才能使它们结合得更好?我们的整个研究过程并不是一帆风顺的,遇到了很多问题困难,此次主要将针对这些问题和我们提出的解决方案和大家进行分享,力求使强化学习方法真正为视频传输带来帮助,对产业界应用带来助益。
-01-
背景与问题



此次报告将分三个部分,首先快速介绍背景与问题。我们知道,随着实时视频和实时交互视频业务的持续增长,视频通话、视频会议、VR和4K全息视频、机器人远程操作等应用场景可能占到了当今互联网流量的80%以上。虽然业务量越来越大,但视频质量却不能令人满意。可能大家都曾遇到视频电话卡顿、画面质量低等问题。在此背景下,我们希望了解在实际的商业网络中,低QoE问题究竟有多严重。
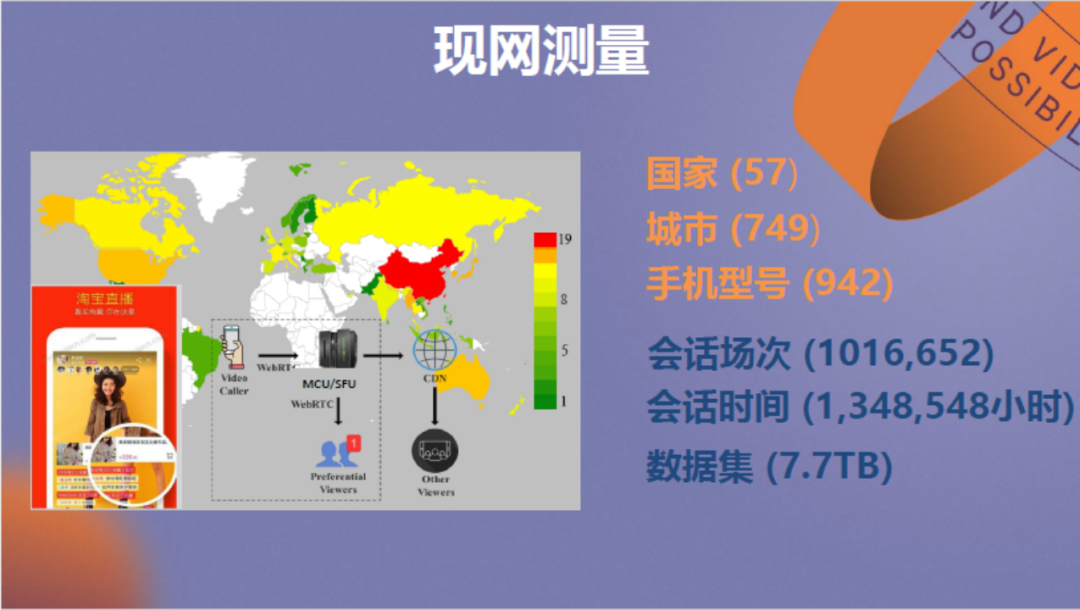
我们与淘宝直播合作开展了现网测量研究。测量包括57个国家共749个城市,测量的会话场次和会话时间数量级达到百万,大量的数据集被收集。
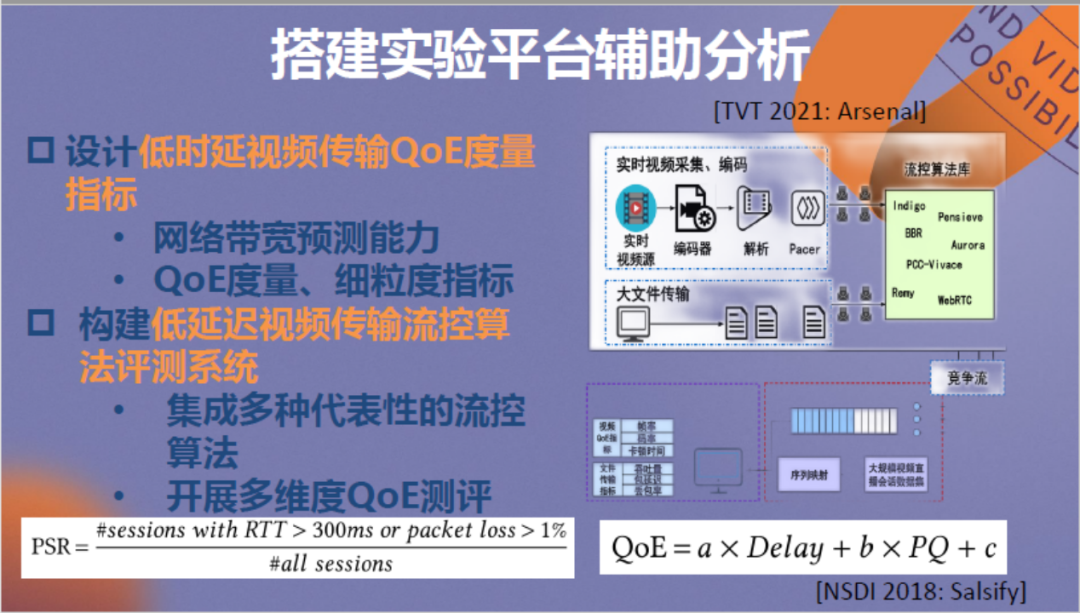
同时我们也搭建了一些实验平台和评测系统辅助进行分析,具体情况见上。
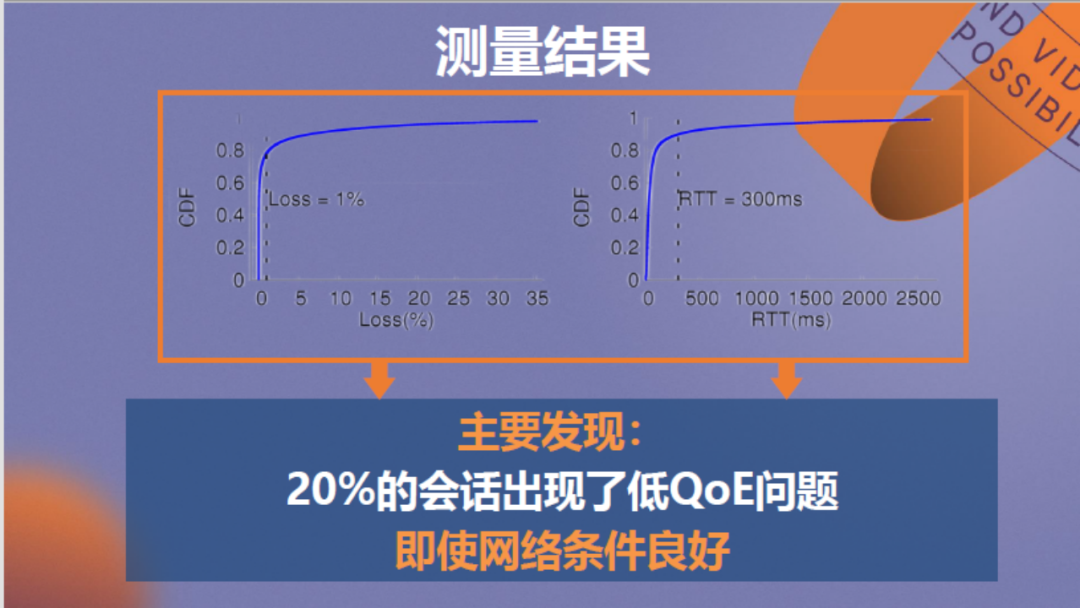
最终的分析结论为:如果将丢包1%或RTT300毫秒作为低QoE标准,那么测量数据中约20%的会话存在低QoE问题,即使基础的网络条件良好但视频质量仍然不佳,情况类似于道路修得宽但汽车跑得慢,想必只能是司机技术的问题。
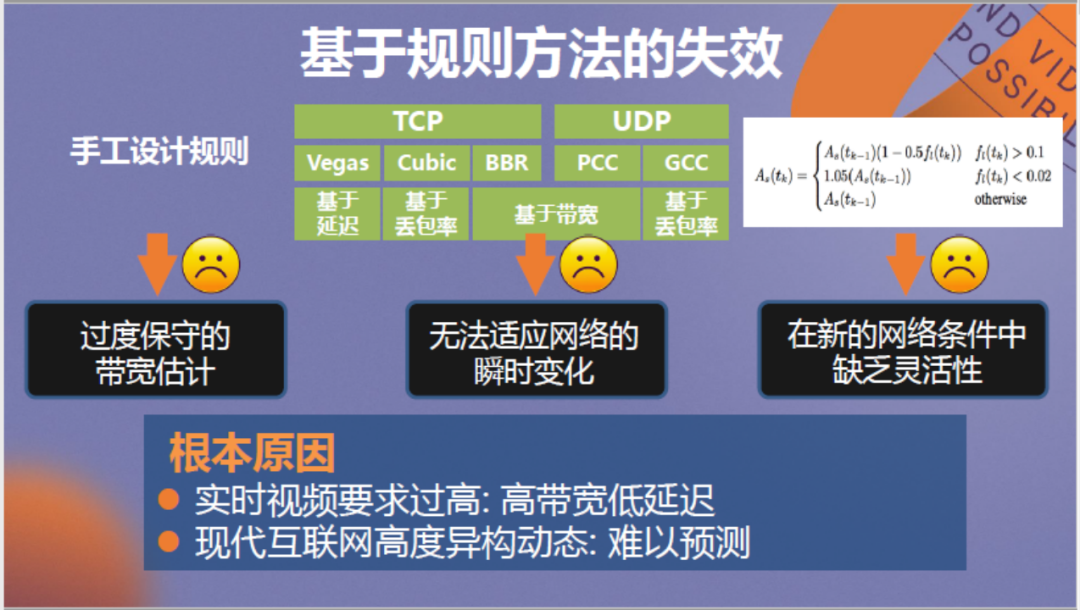
那么要如何解决该问题?解决的关键在于传输方法,我们发现TCP、UDP等传输协议一般均是基于经验手工设计,在现代网络中存在带宽估计过于保守、无法适应网络的瞬时变化、在新的网络条件中缺乏灵活性等问题。根本原因在于实时视频场景对网络的带宽要求越来越高,对延迟要求越来越低,同时现代互联网变得高度异构和动态,难以预测。
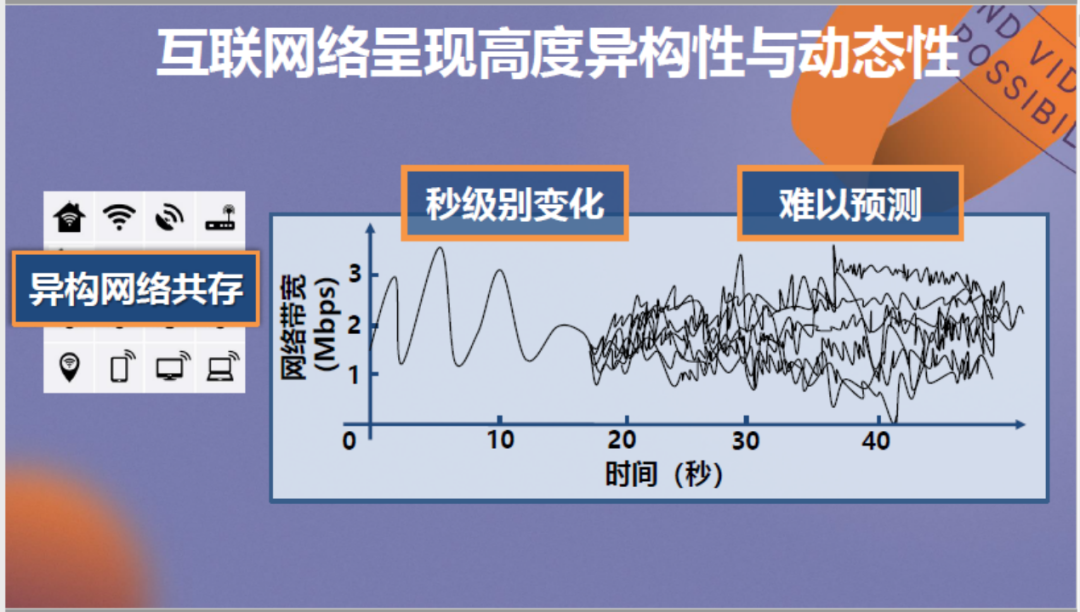
在此具体介绍互联网的高度动态性,目前网络带宽的变化可以说是呈毫秒级,它的状况类似于股市。大量用户传输数据带来的带宽变化相当难以预测,导致以固定规则约束难度相当大。

我们希望通过强化学习方法来解决这个问题。相信大家可能从AlphaGo开始了解了强化学习,它的本质为不局限于固定规则,以数据驱动,用试错法来间接学习。
这个思路可以被应用在视频传输业务上,通过使AI不断传输视频来学会应对网络变化。其次,在视频传输过程中,一个决定可能对当下和未来都会造成影响。例如传输过程中视频分辨率的切换对网络状况会持续造成影响。强化学习方法不同于监督学习,它通常规划远期结果,适用于以上情况。
-02-
强化学习+低延迟视频:从理论到实际
2.1 离线学习
刚才提到,在使用人工智能优化视频传输的实践过程中我们遇到了很多问题,接下来将向大家具体介绍这些问题和困难。在此之前先简单回顾视频会议/通话系统的哪些要素决定了传输质量。
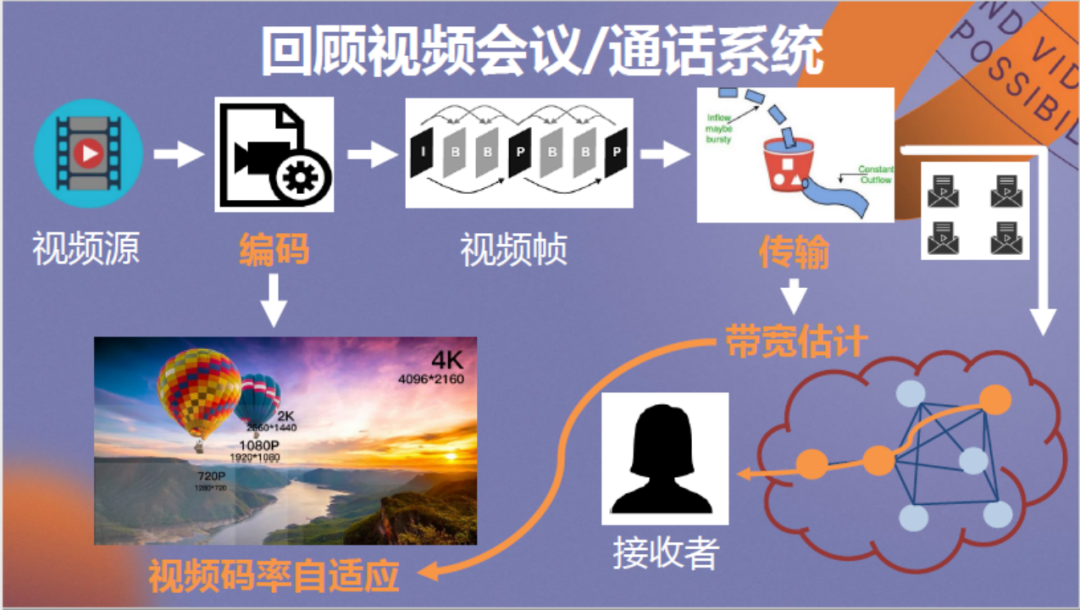
从上图可以看到,一个视频源被编码后分为各个视频帧,视频帧被分别打包进行传输,各个数据包通过网络到达接收端,最后经过解码、渲染,被还原为视频画面呈现在观众眼前。
其中有哪些环节决定了用户的体验质量呢?我理解有两点:首先为传输,它的本质为对链路可用带宽进行估计,并将结果发送至编码器,通过与编码器的协作达成视频码率的自适应调整。可想而知,如果协作较好,那么视频播放会比较流畅。
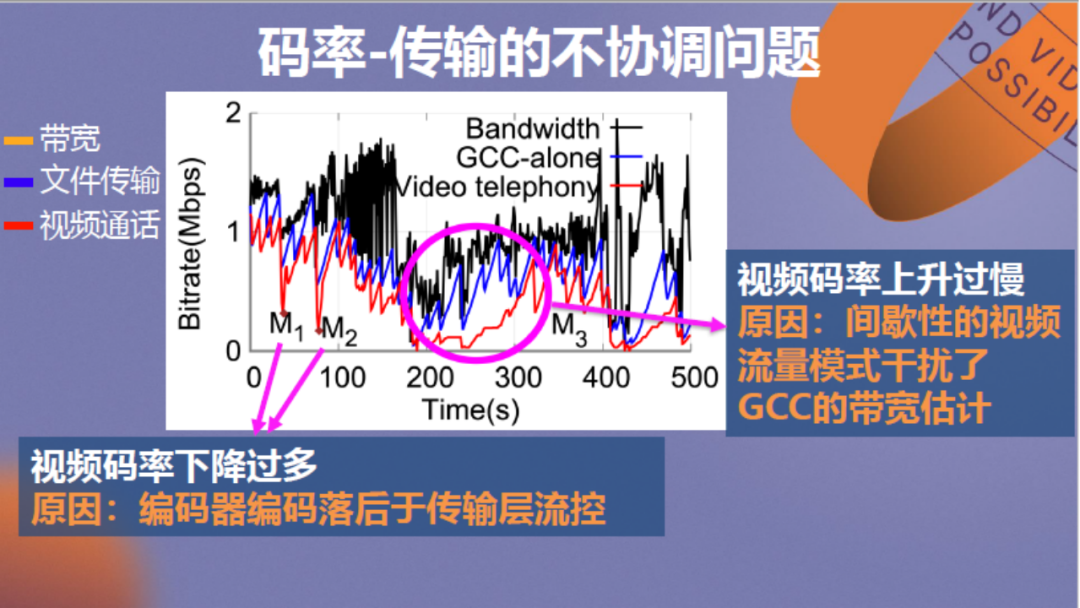
但实际上双方并不够协调。以上为传输实例,图中的黑色线条为真实网络带宽,GCC为Google的视频传输拥塞控制算法,蓝线代表使用它传输非视频文件的速率,过程中不涉及编解码,红线代表它传输视频画面的速率,过程中涉及使用编码器。
通过分析可以看出,在图中M1、M2点网络出现拥塞时,随着带宽下降,红线的视频传输速率发生不正常的大幅下降,原因在于编码器落后于传输层流控。在M3点网络带宽回升时,相较于蓝线,红线的视频传输速率上升过于缓慢,原因在于随着视频传输速率降低,它的帧率也发生降低,正在传输的数据包也变少,这干扰了GCC的带宽估计,使传输速率无法快速回升。
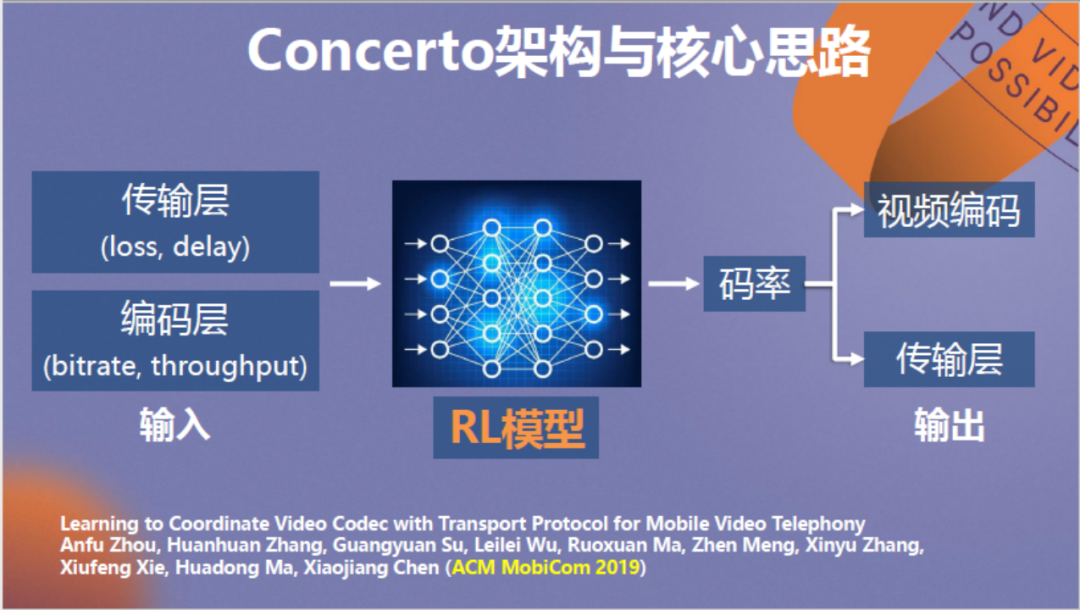
我们设计了一个强化学习模型来加强二者的协调性。该模型取消了传输层的主导作用,由神经网络负责收集传输层和编码层信息,计算编码器和传输层的最佳协同码率。
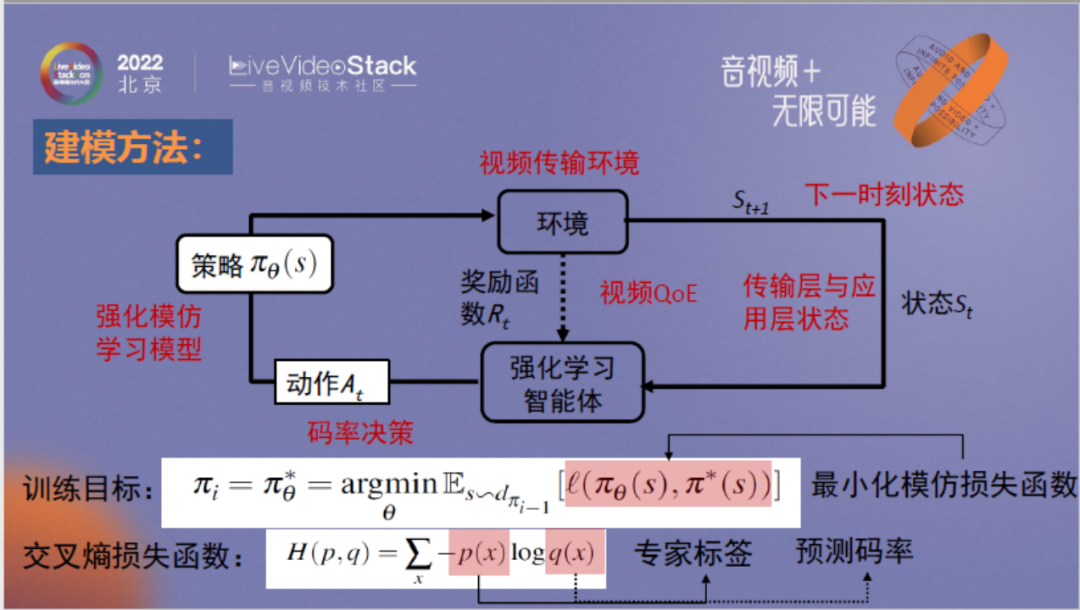
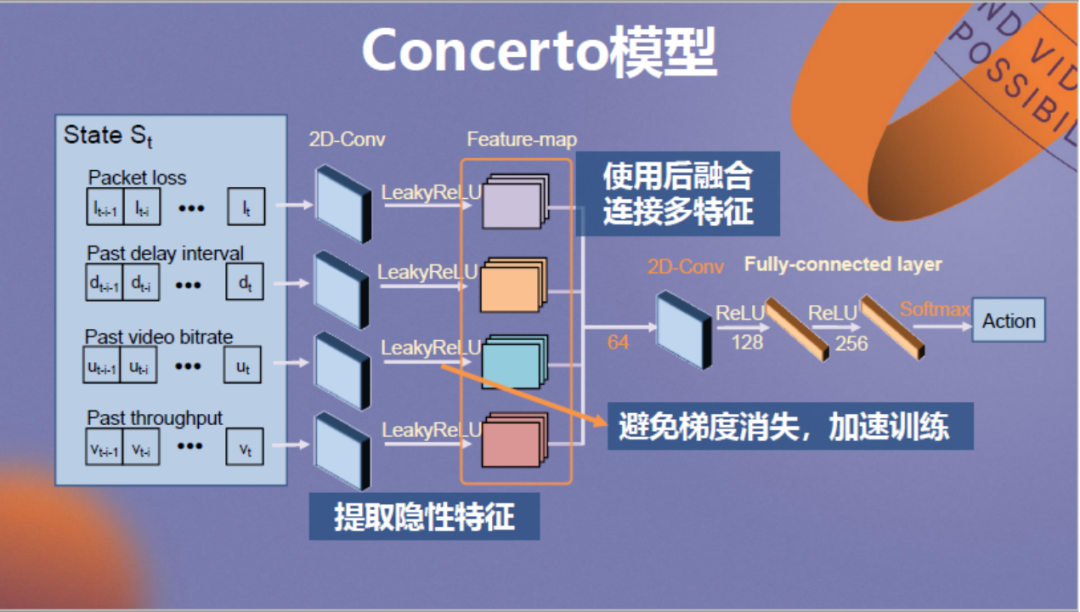
以上为神经网络的建模方法和模型结构,各位如果感兴趣可以查阅我们的论文。
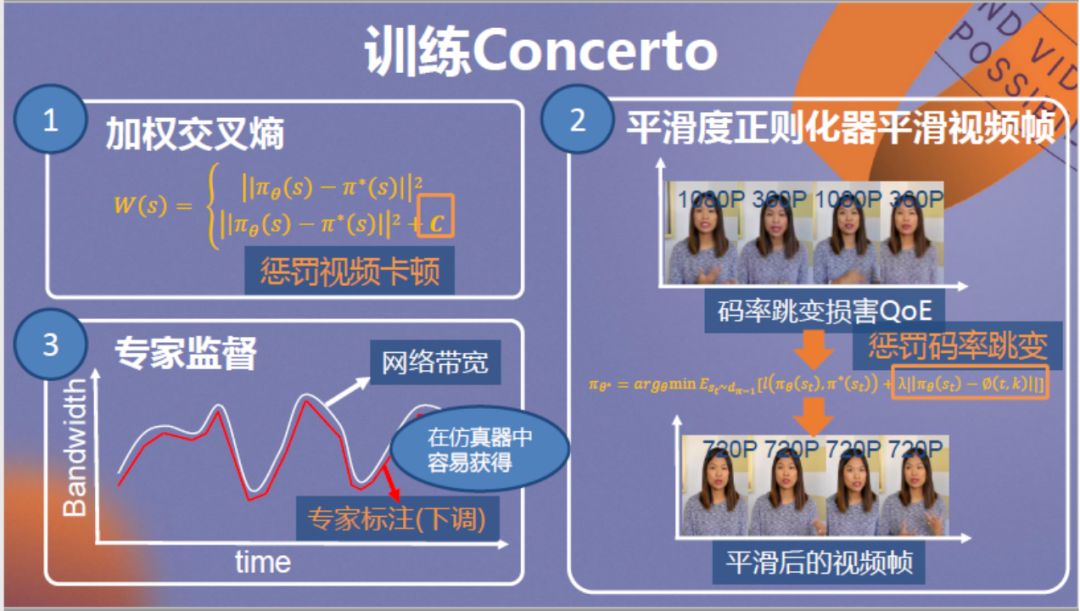
值得一提的是,针对视频传输我们对神经网络设计了新的训练方法,首先在惩罚函数的设计上注意额外惩罚视频卡顿,防止高估视频带宽造成视频卡顿。其次是倾向于惩罚码率跳变,保证用户观看体验流畅。第三是注意将监督学习过程中的专家标签调整到略低于网络实时带宽,保证优化结果理想。
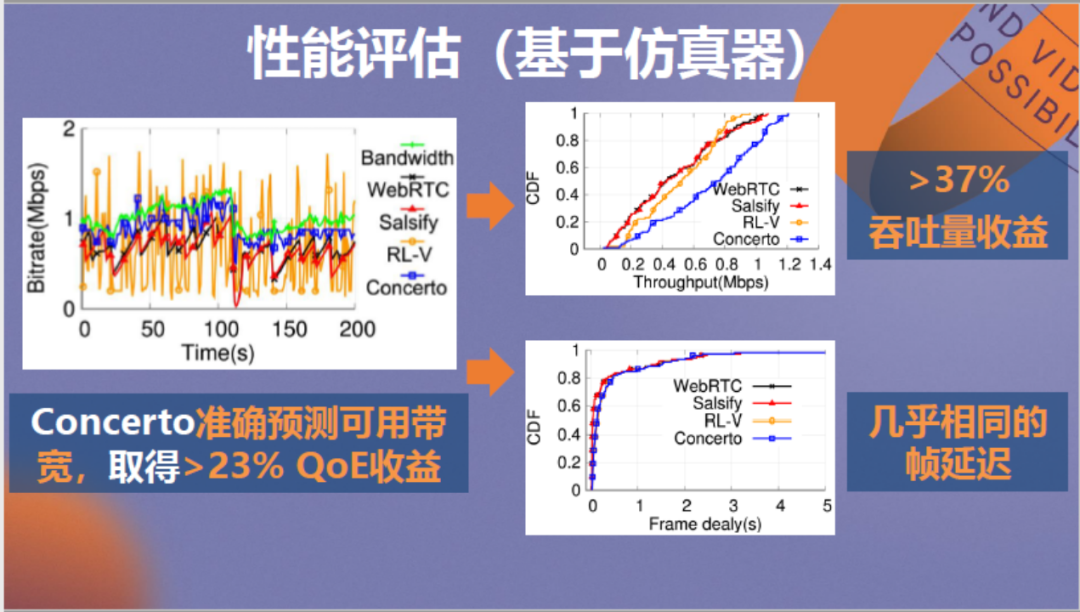
以上为神经网络方法(Concerto)的性能测试结果。左侧图中绿线为真实带宽,蓝线代表神经网络方法传输视频的速率。可以看到,蓝绿两条线贴合较紧密,Concerto可以较好的预测可用带宽,取得23%的QoE收益。它带来的吞吐量收益是37%,同时帧延迟和其他传输方法相比几乎没有差距。
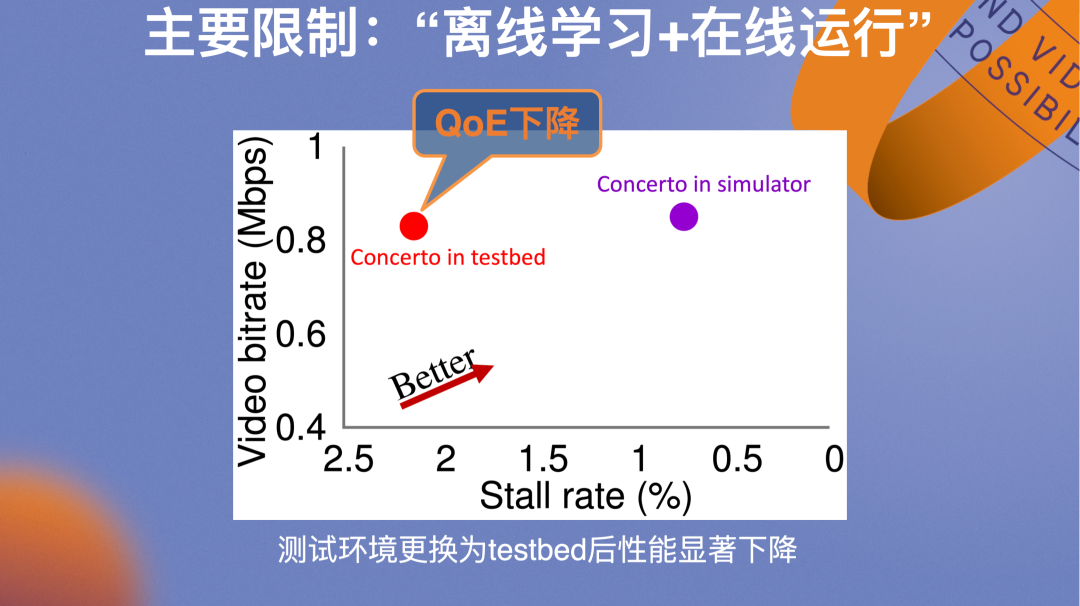
我们对研究成果感到十分兴奋,并且进行了实际试用。不过虽然Concerto在仿真器中训练后模拟的结果较好,而测试环境一旦更换为实际的testbed,优化效果就出现显著下降。在仿真器和真实环境下算法性能不一致,这是强化学习方法面临的经典“仿真-现实差异”问题。

实际在强化学习的训练过程中,由于真实的网络带宽状态瞬息万变,仿真器难以“全真”模拟网络的动态性,并且模拟环境存在时效性,随着网络环境的不断发展更新,模型在仿真器中学习的经验面对实际环境可能变得“过时”。
2.2 从离线到在线
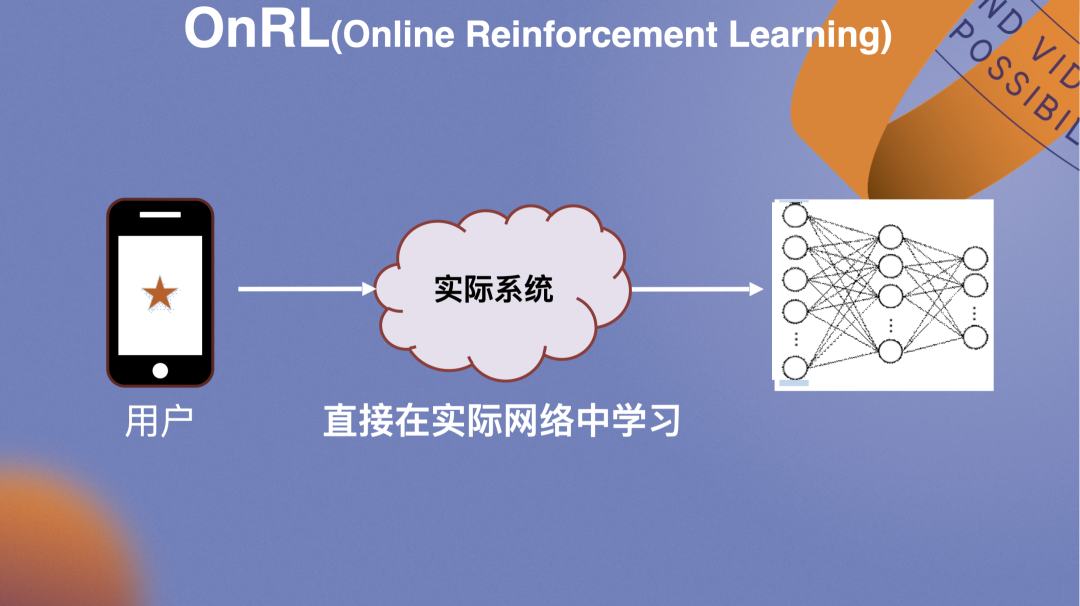
因此相较于原流程先收集用户trace,离线在仿真器中学习后再部署,我们思考让AI算法直接在实际网络中学习,面对真实的网络环境。
这也是第二部分从离线到在线的分享内容。该思路是简单并符合直觉的,不过在落地过程中面临很多挑战。
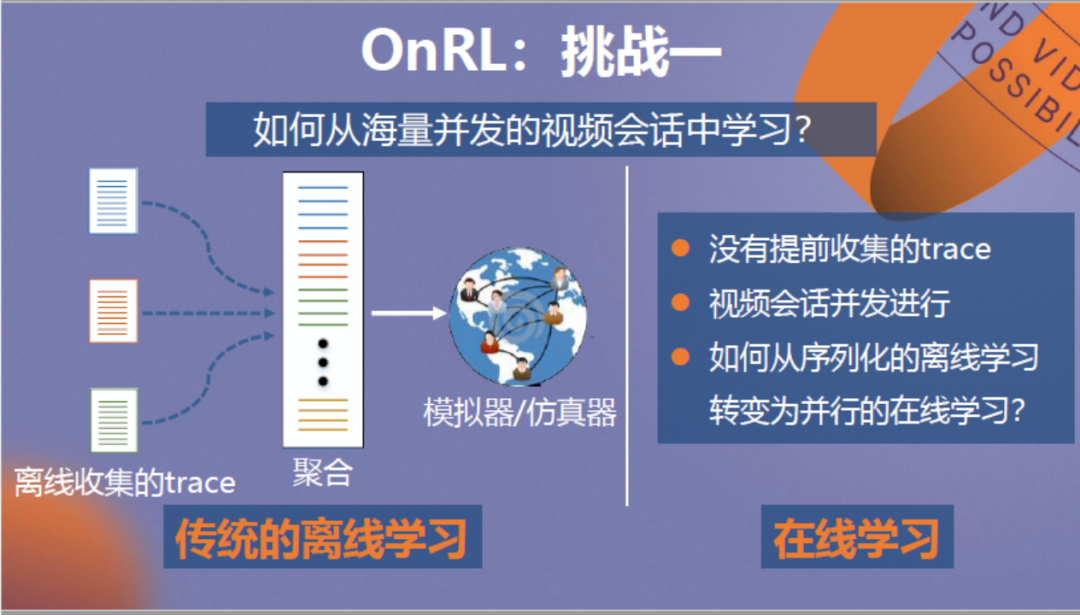
首先是如何从真实网络海量并发的视频会话中学习?传统的离线学习需要收集大量trace,例如视频会话的丢包、吞吐量,将其聚合后在仿真器中进行训练。而在线学习无法提前收集trace,并且视频会话是大量同时并发进行的,因此如何将序列化的离线学习转变为并行的在线学习是亟需解决的问题。
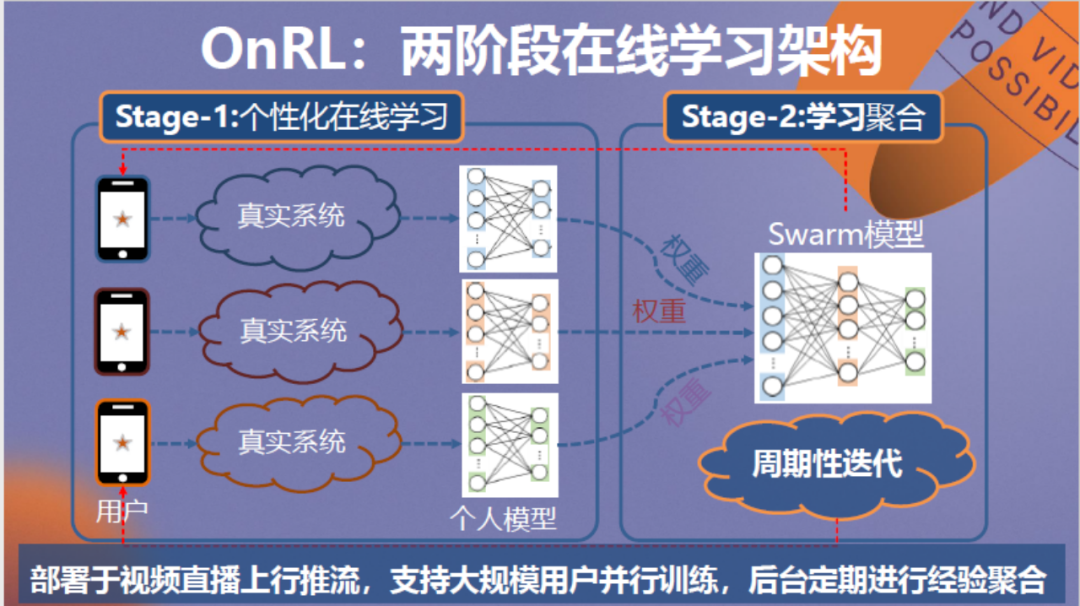
针对该问题我们提出了两阶段的在线学习架构,第一个阶段针对每个用户训练个人模型,第二阶段考虑不同的权重将各个个人模型进行聚合,最终得到总结全部经验的模型。聚合后的模型再被投放到各用户运行进行迭代,最终形成稳定版本。
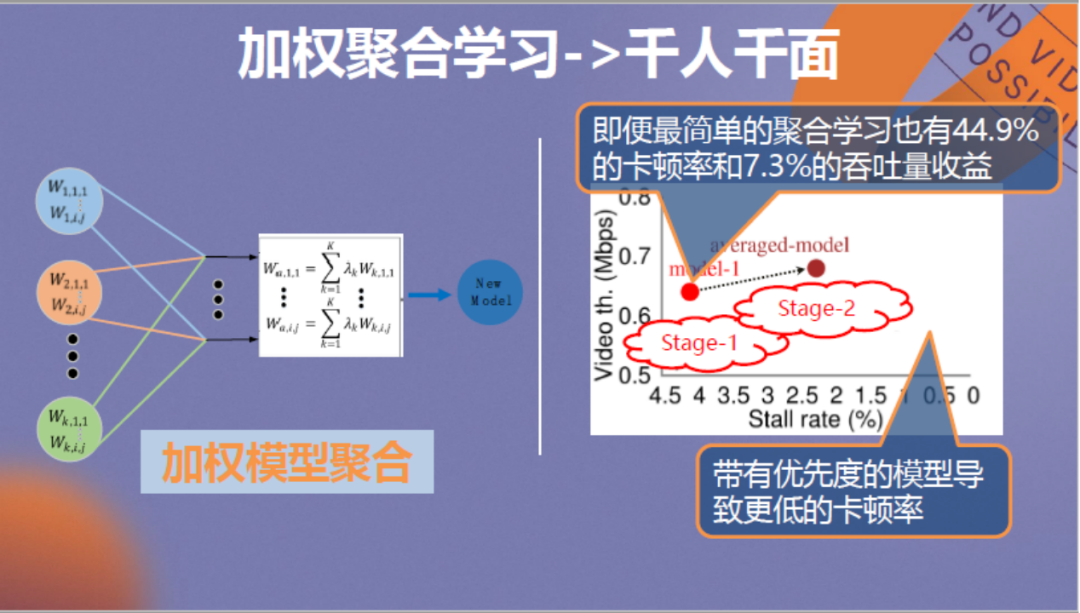
以上方法的优势是通过加权聚合学习可以做到千人千面的个性化优化,针对5G用户或家庭WIFI等不同的环境,可以利用提高特定环境模型权重的方法进行定制优化。
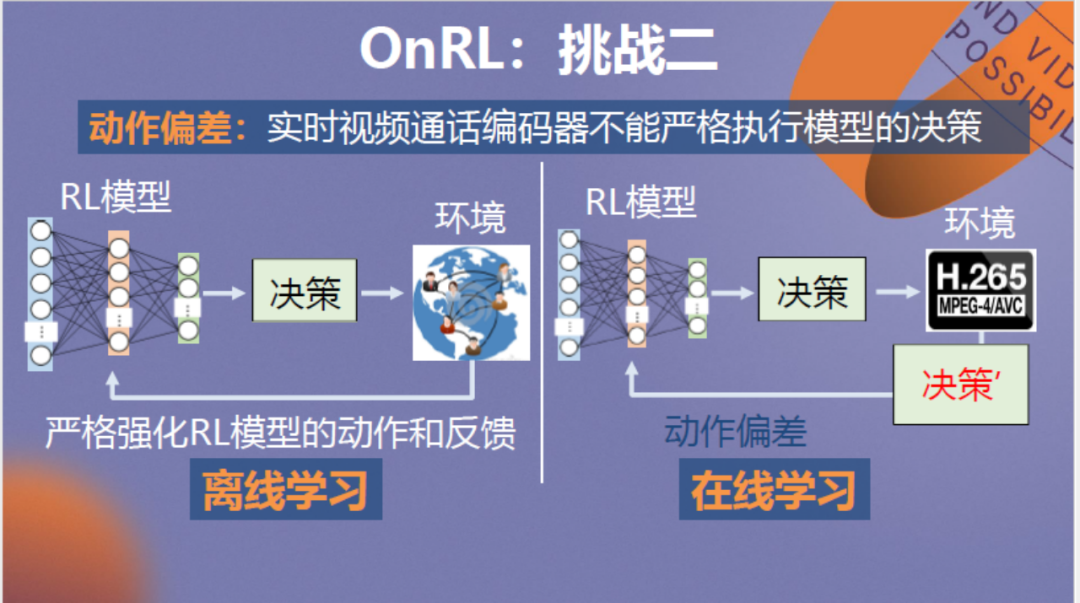
第二个挑战是,与在仿真器环境下神经网络可以完全控制传输层传输这一情况不同,真实系统中编码器的数据传输要依据实际的画面和网络情况变化,它无法忠实执行神经网络的策略,这为在线训练带来了不利影响。
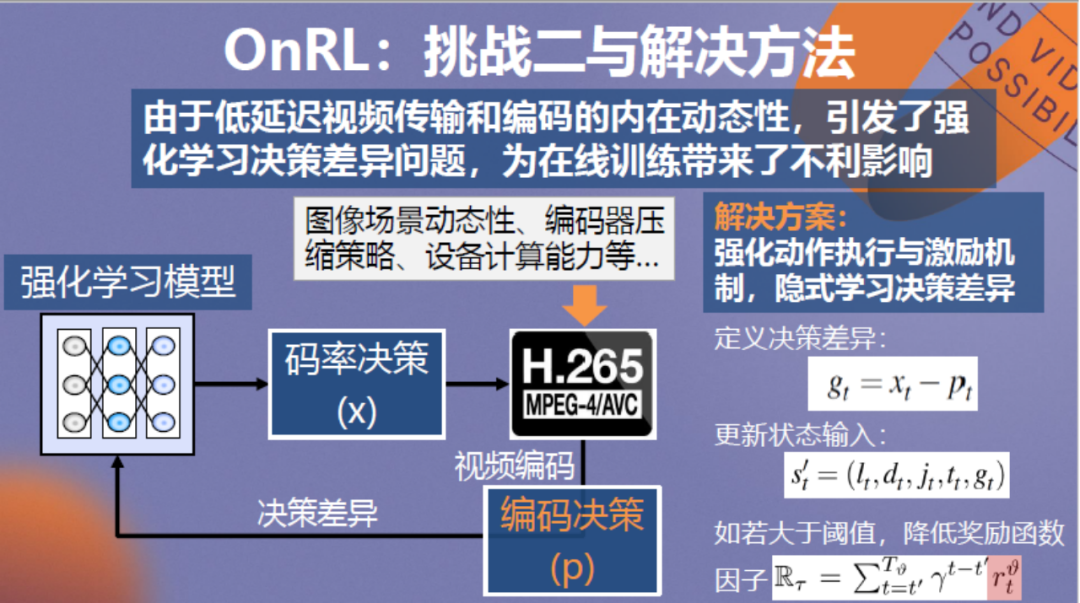
针对这个问题,我们考虑将实际环境中编码器执行神经网络决策的偏差再一次输入到神经网络中,使神经网络了解并学会容忍决策偏差。
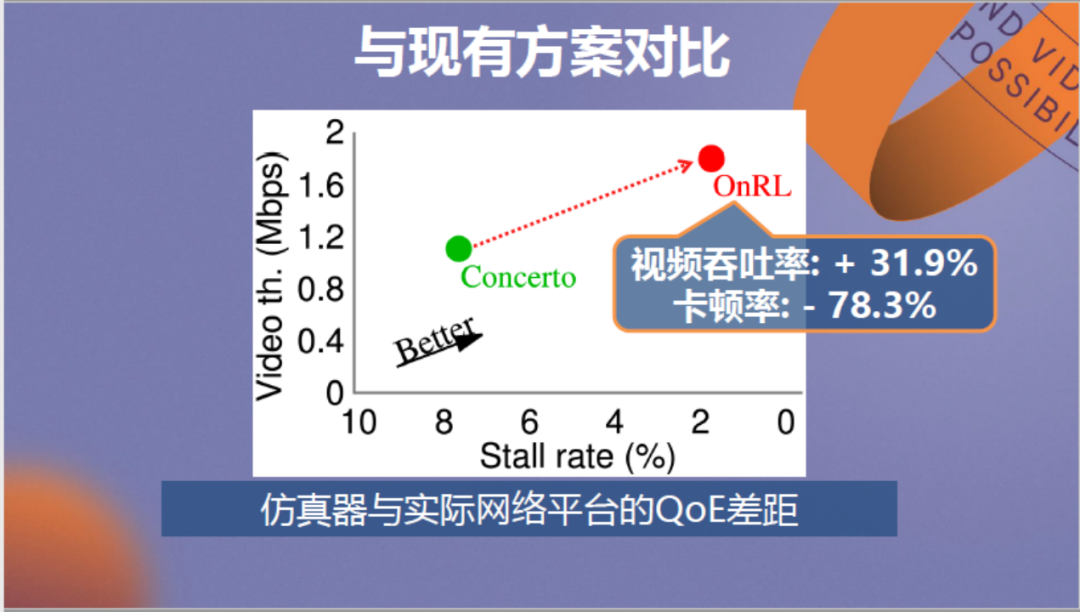
新的训练方法随之形成,与原方案的对比情况见上图,其中绿色点为离线方案,红色点为在线方案。可以看到,新方案的对视频的优化性能提升很大。
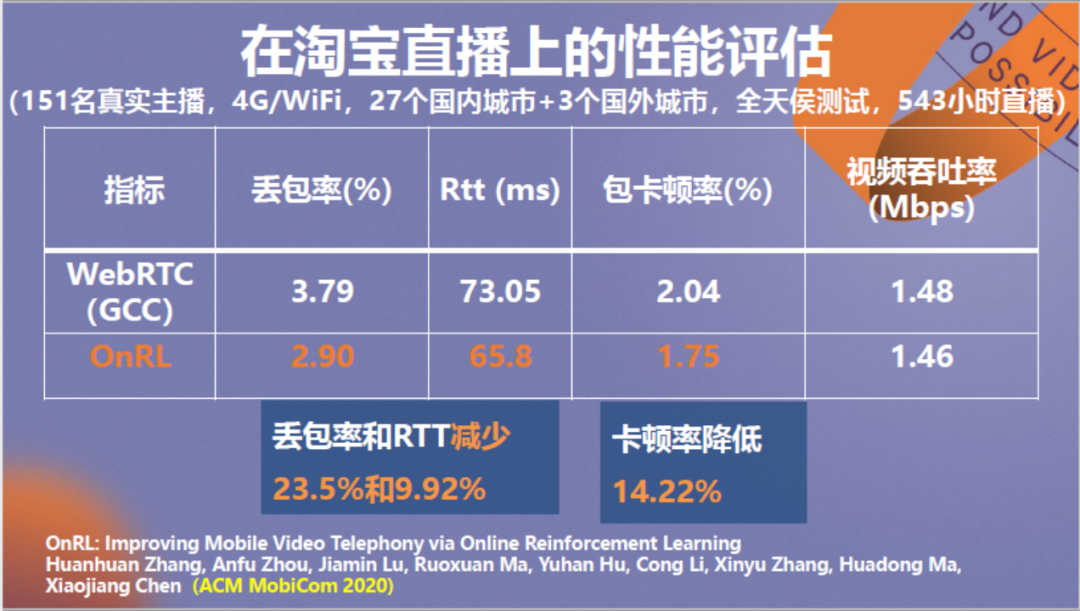
以上是利用训练后的神经网络在淘宝直播平台上的视频传输性能测试结果。可以看到丢包率、RTT和卡顿率都出现了减少。
2.3 从不可靠到可靠
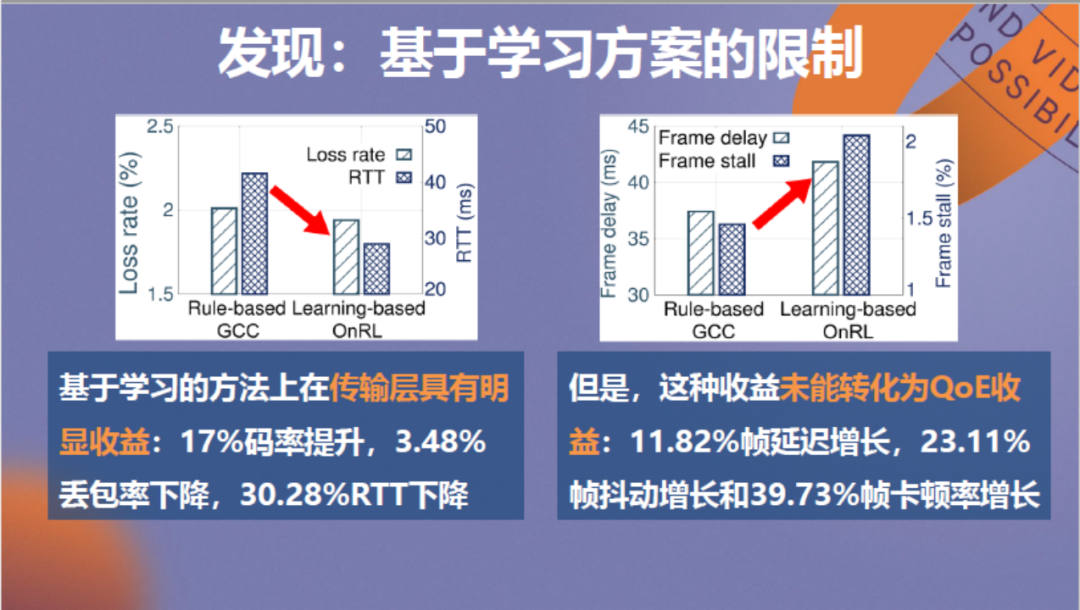
接下来看最后一个问题。由于强化学习方法本质上需要试错,那么它不总是可靠的,在某些场景下会”翻车“。在使用它优化视频传输时也出现了对部分视频会话场景优化效果不好的情况。
经过分析发现,在这类场景下,虽然基于强化学习的方法在传输层具有明显收益,但这种收益未能转化成应用层的视频QoE收益,反而出现了帧延迟、帧抖动和卡顿率增长。
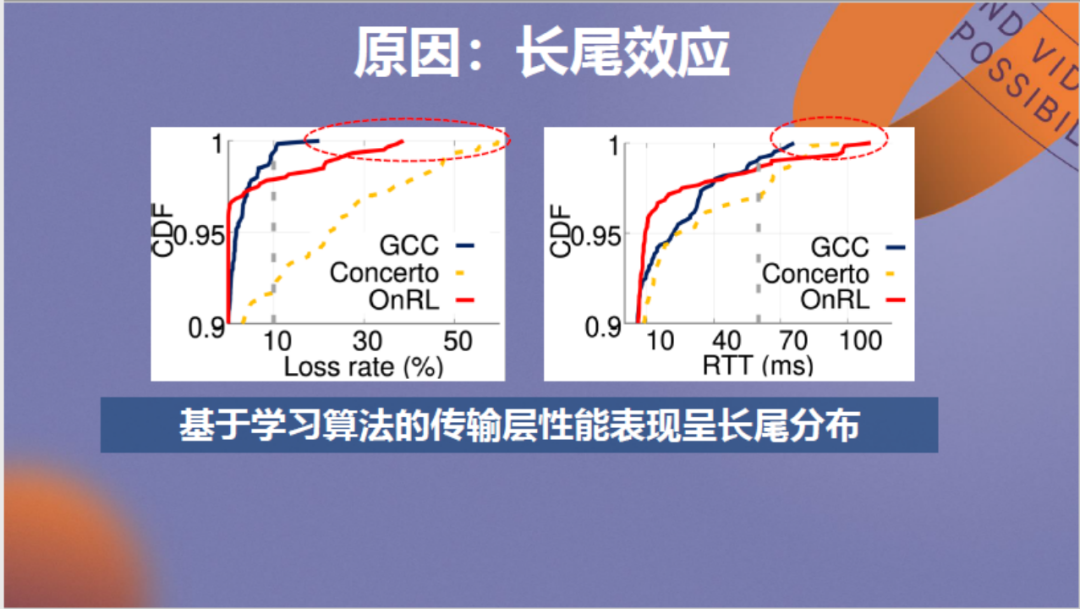
我们剖析了问题成因,发现强化学习方法带来了长尾效应,造成传输时可能发生少量数据包发送延迟大的问题。然而,这些少量数据包的大延迟导致整帧画面的过长等待。
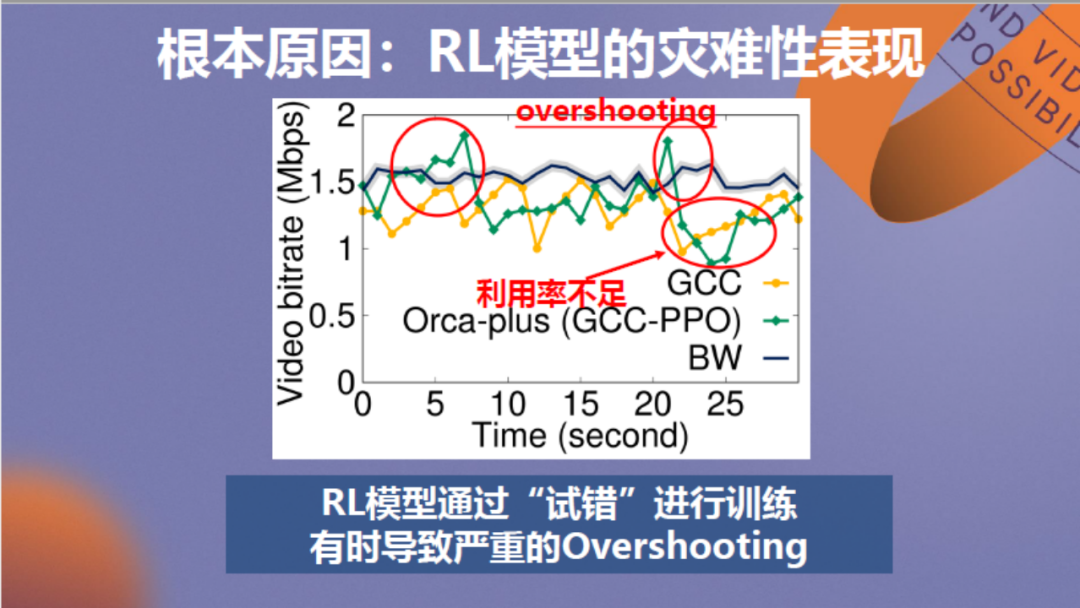
究其根本在于,强化学习模型通过“试错”的方法来进行训练。具体分析见上图,其中黑线代表网络带宽,黄线代表GCC算法的传输速率,可以看到它稳定处于可用带宽下方。绿线代表强化学习模型的传输速率,可以看到有时它的速率会严重超出或低于可用带宽,这实际是算法在进行“试错”,这种Overshooting造成了视频QoE的严重下降。
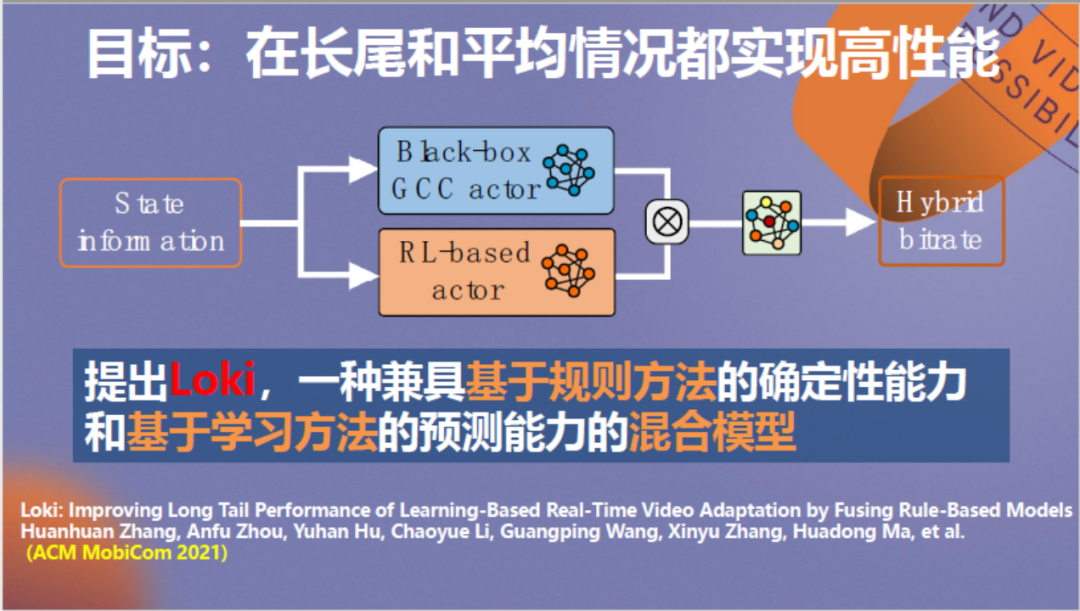
我们希望强化学习模型更加可靠,尽量避免长尾效应。因此,考虑到规则方案的确定性能力,我们利用这个特性为强化学习方法设置了一个传输速率的最低门槛,通过将网络信息同时输入到两种算法中,融合二者形成新的神经网络来进行决策。
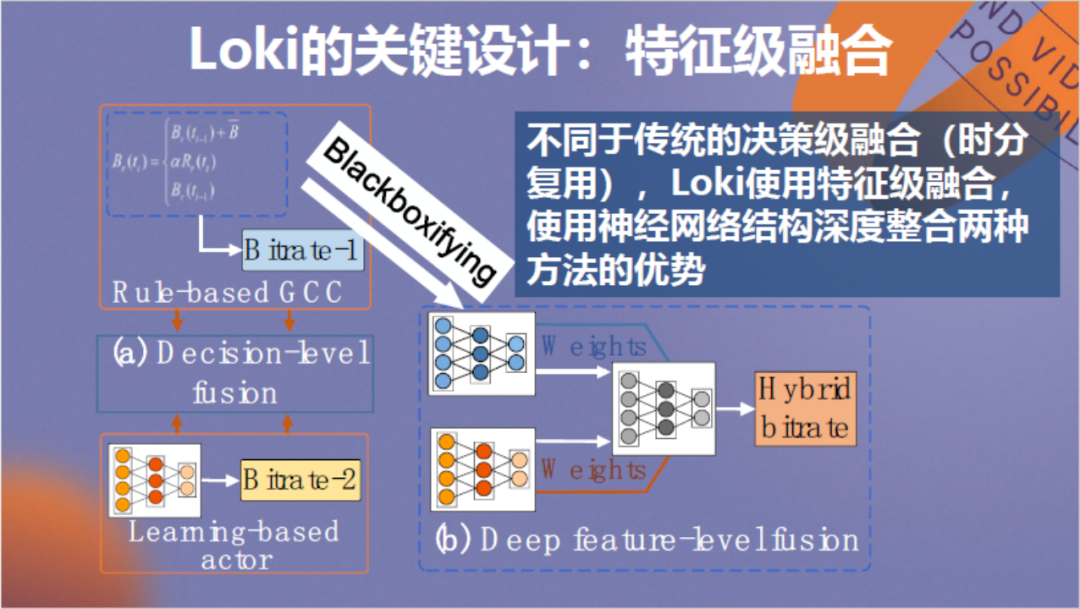
前人曾经做过类似工作,它被称作决策级融合,通过收集规则和强化学习算法分别的预测结果来做出最终决策,但整个过程显得生搬硬套,二者只能算作一种无机结合。为了使二者能深度融合,我们采用了一种特征级融合思路,通过将GCC规则算法黑盒化为神经网络,结合二者的神经元来进行训练。
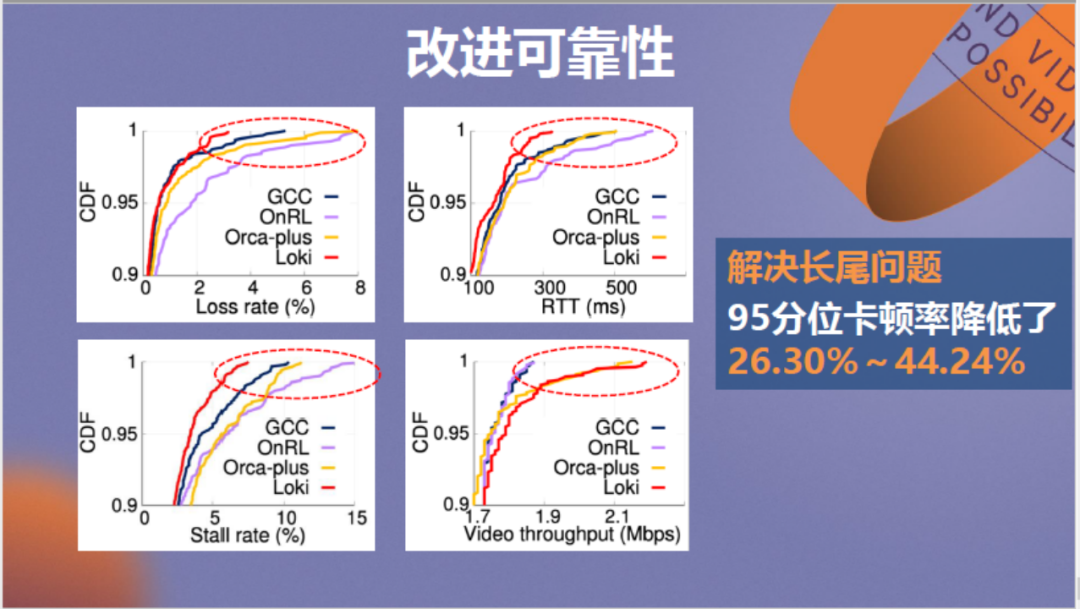
融合后的模型测试效果见上图,图中红线代表融合模型Loki,紫色线代表纯强化学习OnRL模型,可以看到长尾效应被彻底消除,Loki模型将95分位卡顿率降低了26.3%~44.24%,这是特征级融合的好处,它与决策级融合模型的具体比较情况可以在上述论文成果中查阅。
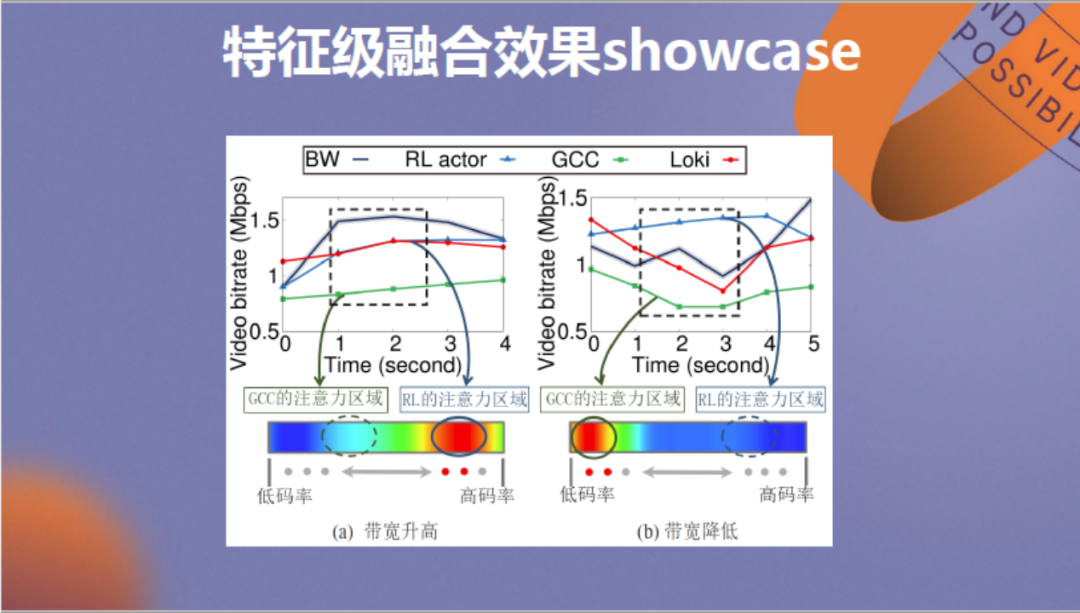
在此展示特征级融合效果的一个showcase,详细介绍也可以参考我们的论文成果。其中左侧第一个情景为带宽升高,在该情景下应该由强化学习模型起主导作用,因为它可以充分利用有效带宽,可以看到RL模型的注意力较强。在相反的带宽降低的情景下,应该由规则算法做主导,避免激进决策影响传输质量,右侧图中展示的实际情况也是如此。
-03-
现网验证

最终简单介绍现网验证情况,首先上图为实验情况,我们将GCC改为强化学习驱动的RTC controller,右侧为效应场景。
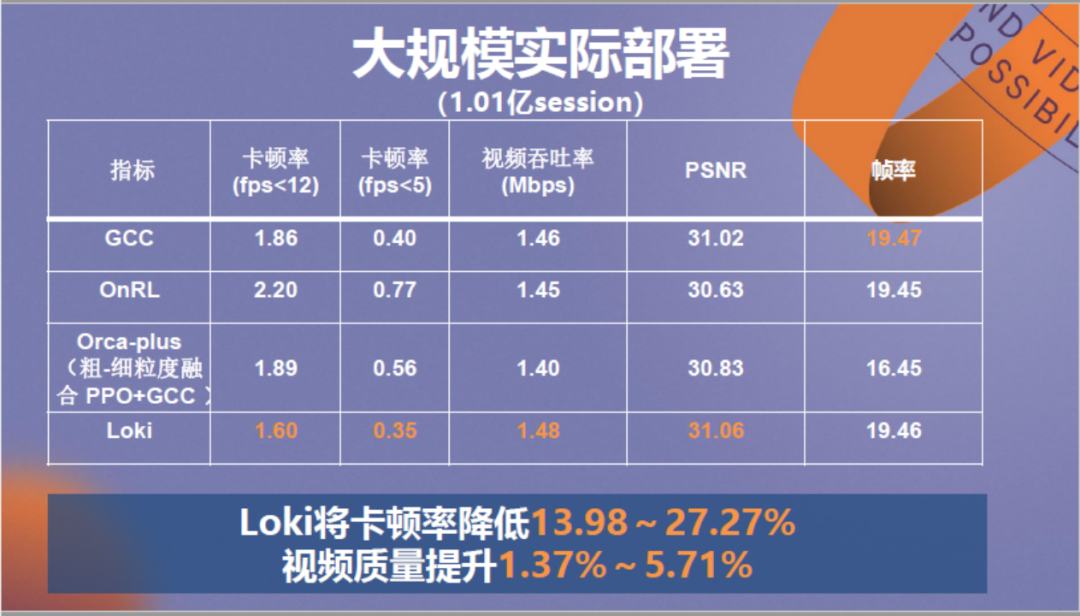
Loki模型在超过一亿的视频场景下进行了大规模实际部署,可以看到它在不同情况下将卡顿率降低了13.98%~27.27%,将视频质量提升了约1%~5%。

该优化服务收获了很多用户,也获得了阿里巴巴和中国电子学会的相关奖项。
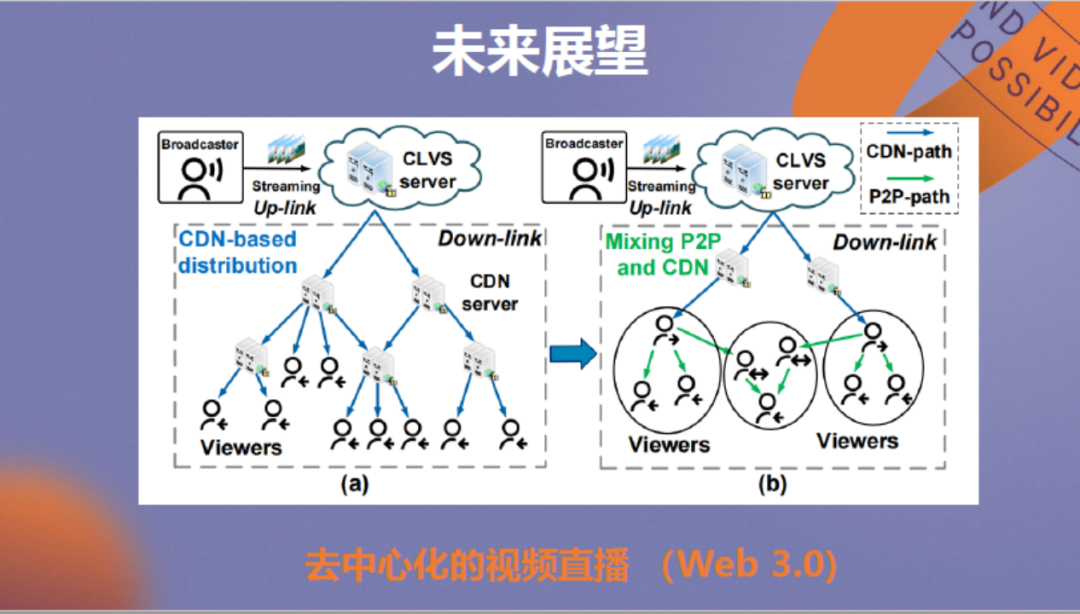
最后进行未来展望。除了视频质量提升外,各位从业者对成本控制可能也较为关注。当前网络大的发展趋势是向Web 3.0来演进,由于它是分布式的,用户也会拥有自己的数据。我们在思考是否可以让用户也参与视频的直播和分发。
这与传统p2p的思路一致,不过p2p在设计时并未考虑视频传输的延迟和苛刻的质量要求,如何使用p2p方法把视频传输做好是我们当前主要的探索方向。

第二个方向是如何做好远程控制,我们知道无论如何优化,网络总是存在延迟卡顿的,如何在上层消除延迟带来的不利影响,真正实现实时远程操控也是我们正在探索的问题。

刚才分享的内容均可以从以上论文中查阅,也欢迎大家就有关问题进行交流,今天我的分享到此结束,谢谢大家!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。