
视频赛道卷到下半场,一定会面临体验与成本的对抗,尤其是在行业大环境“过冬”的背景下,想要在有限带宽下获得最佳的画质观感变得异常具备挑战性。从视频云业务场景的视角来看,如何有效解决cross-domain问题、如何突破低业务延迟下的算力瓶颈、如何提升单位码字承载的有效信息量,成为我们在实践过程中的应用范式。LiveVideoStackCon 2022 北京站邀请了Bilibili云端多媒体平台的成超老师,为我们分享Bilibili在急速发展过程中基于视频业务上总结的一些先进的经验和想法 。
文/成超
编辑/LiveVideoStack
原文:https://mp.weixin.qq.com/s/Sw9IowO5eorP_a0bCMWnUA
大家好,我叫成超,来自Bilibili云端多媒体。我们云端多媒体主要负责Bilibili点直播技术业务,而我所在的算法组则是基于AI算法为Bilibili点直播降本增效相关工作赋能。
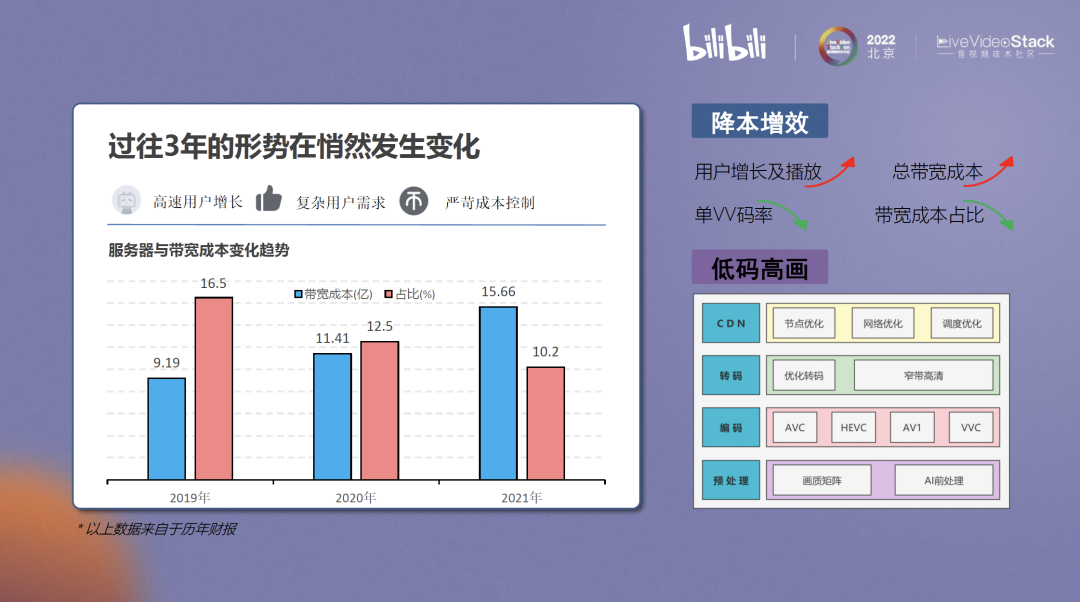
尽管过去行业在过冬,但是Bilibili仍然是一家保持着非常高增长的公司,我们的用户规模以及播放量一直在持续增长,相关的总带宽成本也在节节攀升。大家参加LiveVideoStackCon2022北京站可能最高频听到的一个词就是降本增效,它对成本增长提出了非常高的要求,我们需要把成本增长控制在一个非常合理并且高效的规模上。但与此同时,我认为B站的初心仍是没有变的,我们始终秉持着“用户是B站最核心的价值”这一信条,也始终期望着用户能够在B站得到最好的音画体验。
围绕着这个目标,我们做了非常多的工作,自下而上我们在预处理层面做了今天要讲的画质矩阵、AI前处理,并且我们有一个很强大的团队自研编码器,再上一层,研究使用编码器开展窄带高清工作,最底层也会设立一道CDN来进行网络、调度和节点优化等等工作。
如果说降本增效是目前行业对于所有公司提出来的命题作文,那么我们的答卷就是:低码高画。
今天我的分享主要分为四部分,第一部分讲视频云AI画质提升链路;第二部分将结合一个非常具体的实时游戏直播来分享我们所做的4K游戏实时超分;第三部分则转到低码部分,讲一下基于低秩重构所做的AI窄带高清前处理算法;第四部分是一个简单的总结及展望,介绍我们在做和未来可能会做的一些工作。
-01-
视频云AI画质提升链路

首先简单谈谈我们对于画质业务的思考和理解,即为什么要在成本受限的情况下仍然坚持做高画质服务,我认为原因可能出于以下四个方面:
第一方面是对于用户,我们认为高画质是科技发展的必然趋势,并不受行业的升降趋势所左右。我们在企业内部提出了一个“全时高清”的概念,即用户在任何时间、任何地点都无需受到任何约束来享受高品质的音画服务;
第二方面是希望对UP主进行赋能,我们希望UP主们能够将百分百的身心投入到idea创作和内容的生产中去,无需受到专业的拍摄器材设备和拍摄条件限制;
第三方面是针对产品和运营,我们希望画质能力能够成为他们执行一些策划或者活动的有效抓手,配合扩大B站的影响力;
第四方面则是针对商业合作伙伴,我们希望能以画质做为切入点,配合他们做好商业宣发和推广活动。
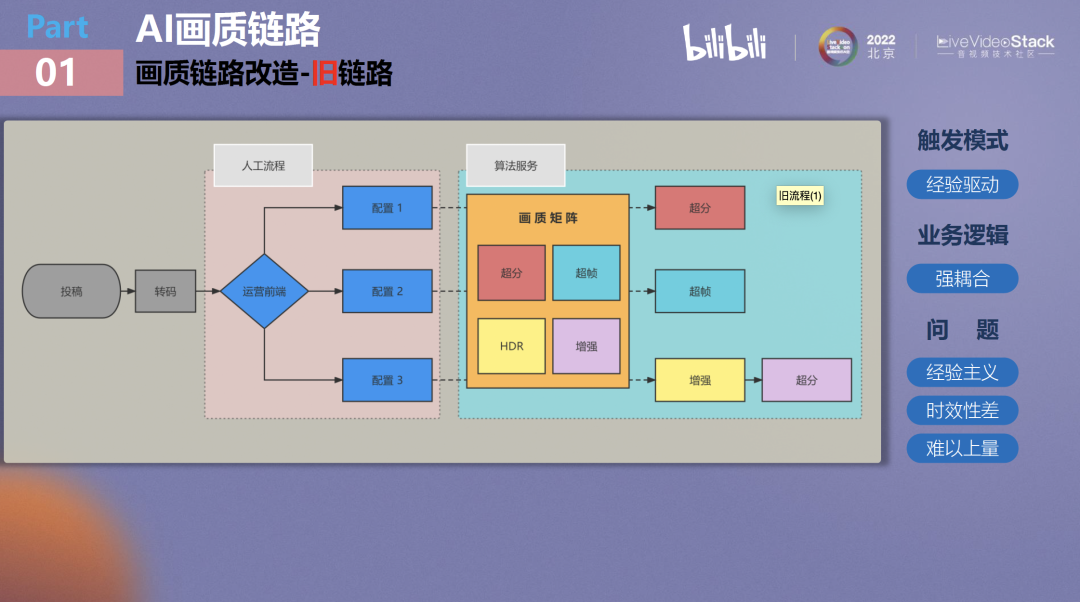
在这里谈谈B站以前旧的画质生产链路,在过往长期的业务需求里我们积累了大量的画质原子能力,形成了画质矩阵,但实际上应用模式并没有实时更新到原子能力的增长上。
举一个简单的例子:以前想要对视频做超分大概要按照这样一个流程,如果上传了一部动漫,在其转码完成后,运营首先要浏览视频内容并判断它适合进行什么样的画质增强处理,如果认为适合做超分,那就将它送到对应的超分服务里去。
这个流程存在的问题就是所有内容都是预先定义好的,如果一个视频需要同时进行多种画质增强处理(如先去噪、再增强、再超分)但目前没有对应服务,那便必须先上线相应的服务才能支持该视频所需的处理流程。这导致旧链路的时效性很差,在业务规模较小的时候尚可,一旦处理需求增长,它势必将受到运营人员的经验主义制约,并且无法实时去响应业务需求。
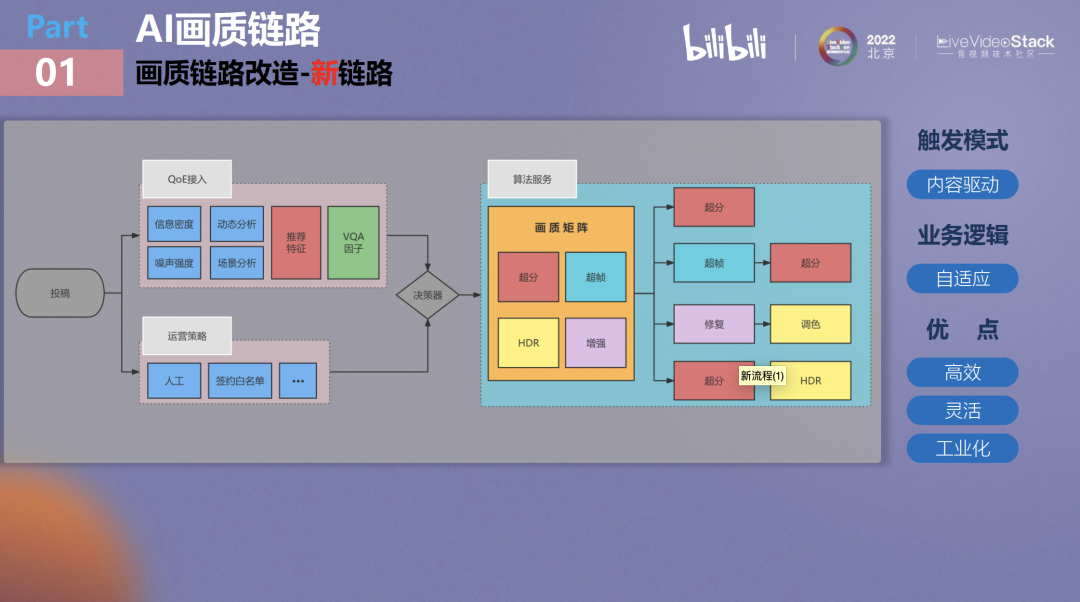
新链路与旧链路最大的区别在于两点:一个是QoE的接入,我们把QoE接入到画质决策体系中,形成了一个以QoE为主,人工运营策略为辅的决策模式。QoE将会提取视频的约40多个特征,包括视频的信息密度、噪声强度,动态分析结果,一些业务上的指标(如上传的视频是否会成为一个高热度视频),另外还涉及一个内部的无参画质评价。
总之QoE策略加上运营策略最后得到的特征向量,将被送至一个决策器来决策当前投稿究竟适合什么样的画质处理,如果信息密度不够则需要做超分,如果时域性不够强并且有提升空间的话则可以做超帧,如果要进行完美的画质修复,则可能需要进行超分加超帧,甚至还需要进行修复,后续的处理流程可能是非常多样并复杂的。基于此,为了满足视频复杂的画质处理需要,我们要完成可用于自定义画质处理链路的工程支持。
最终我们对画质矩阵重新设计了一套底层的AI处理框架,这也是新旧链路的第二个主要区别。它的思想是把所有的画质原子能力尽量节点化,然后我们将处理流程搭成计算图,以计算图的形式来支持任意的画质处理流程,可以说它在使用上就像搭积木一样。
在这个处理流程上线之后生产力得到了极大的增强。我举一个简单的例子:去年大家都知道,在全网范围内发生了一个非常重大的宣发事件,就是周杰伦新专辑《最伟大的作品》的发布,B站也全程跟进了这张新专辑所有曲目的宣发工作。这次工作可以说是最具代表性的一个CASE,主要有两点:
第一是1080P的问题,可能大家不是很清楚,类似杰威尔这样的头部音画文化传媒公司其实还是在生产1080P清晰度的视频,并没有更新4K、60FPS这样的新技术。但实际上4k对于用户来说又是一个非常刚需的需求,我们当时就反映了这一问题并询问能否提供4K介质,实际当然是没有生产的。
而用户有需求怎么办?
我们提出了建议方案:即借助AI对原视频进行4K高清化。他们听后表示非常高兴,并且很乐意我们对他们的介质进行AI增强。同时还提出,如果用户希望得到最好的音画体验,要做干脆就将画质拉满。所以除了超分外,本CASE还一并进行了60fps增强,大家上B站是可以看到的。
第二点就是时效性。如去年7月6日,新专辑第一张单曲最伟大的作品发布时,杰威尔公司要求歌曲在当天中午十二点准时全网上线,但只提前两到三小时提供歌曲原始介质。如果以旧链路对介质进行4K化处理,至正式上线可能需要三到四小时。使用新的生产链路,整个流程可以缩短到约一小时。使用新链路可以更好地响应业务的实时性,B站也是去年全网唯一在第一时间支持4K模式的宣发平台。

大家可以从图中看到三次元的超分效果,发现衣服的纹理、人脸和背景的木质材质得到了极大的增强。
除超分外,我们也支持很多low level的能力,比如超帧。不知道大家对B站舞蹈区是否有了解,舞蹈区可谓是所有分区中的“卷王”,这主要体现在拍摄手段上,舞蹈区UP主们的拍摄手段甚至会比一些摄像、器材区的UP主还要专业,舞蹈区视频普遍已经达到了4K清晰度,有些甚至到了8K。流畅度方面,如果大家观看宅舞较多,应该知道高帧率下人体的舞蹈是非常丝滑的,众宅男对60fps也有相当高的需求。如果观察B站舞蹈区排行榜就会发现,榜单头部视频都至少支持60fps,有的甚至支持120fps。
这随之带来的问题是拍摄高清晰度高帧率视频所需的器材成本非常高。对于中长尾UP主,我们不希望器材设备条件限制他们的内容创作,所以在云端通过插帧的方式来对他们进行赋能。
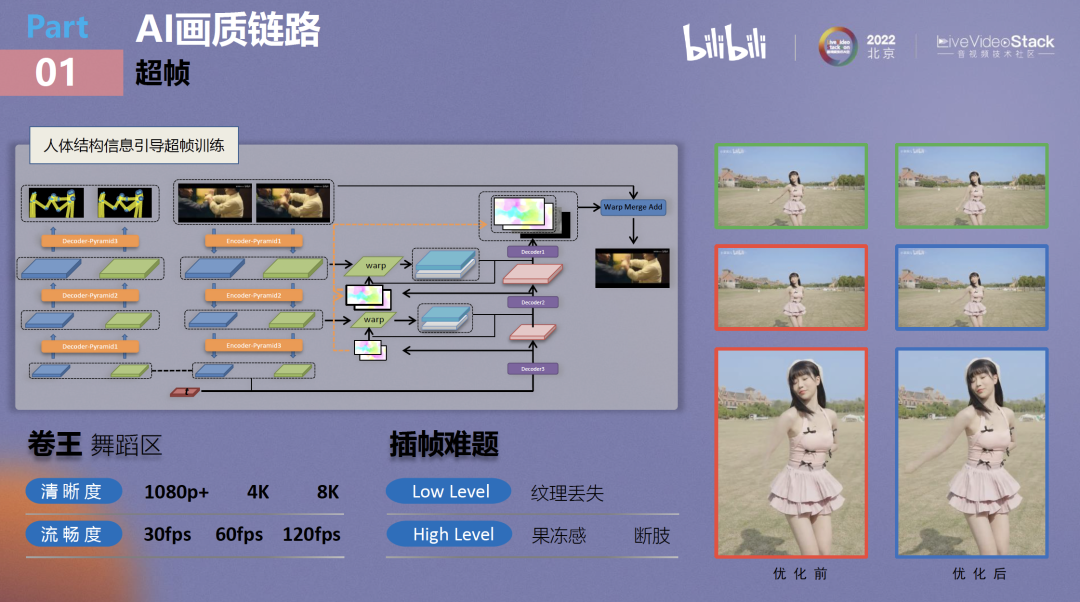
插帧现在已经比较成熟,但在落地过程中存在比较多的问题。可以发现,插帧对于大规模运动的特征捕捉得不够好,反映到舞蹈中则会造成图中红框所示的断肢问题,或者在一些高动态场景(如赛车场景)中,可能会出现纹理丢失问题,如路面的柏油、沥青路面纹理丢失,路面变得平滑。这都是插帧算法目前面临的比较典型的问题。
我们针对这些问题进行了定点优化,比如在插帧网络中头部的特征提取部分拉出一个额外的分支去预测人体关键点,希望网络在特征提取部分就能够去关注到一些人体姿态的变化,更好地去捕捉人体姿态特征。
经过优化,可以看到断肢问题得到了极大的缓解,动作已经能十分流畅了。现在上线的插帧算法已经支持30帧超60帧,30帧超120帧,并且线上已经有低帧率视频通过该算法实现了高流畅度。欢迎大家去抓抓虫,看能否识别哪些CASE是原生高帧率,哪些是经过算法处理,我认为现在已经很难看出区别了。
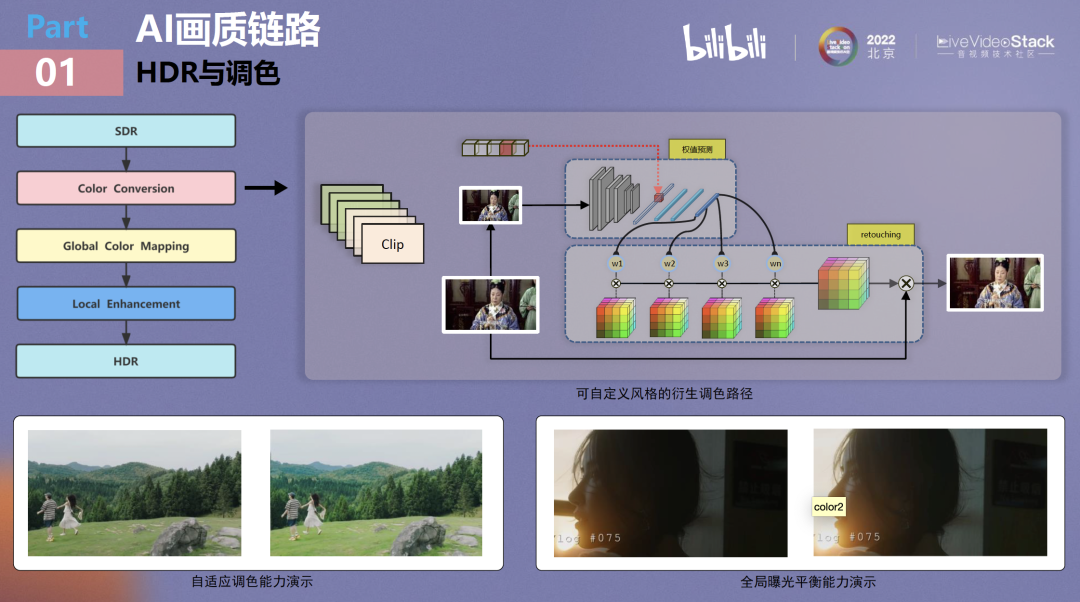
本页讲一下我们所做的HDR工作。HDR也是一项非常重要的工作,因为人眼对色彩是非常敏感的。将SDR转为HDR大概需要三个步骤,第一步是Color Conversion,它是在8bit上对全局的曝光和色彩进行调整,调整后能够得到很好的色彩增强效果。第二步是Global Color Mapping,在这个阶段主要将8bit由bt709色域映射至bt2020色域的10bit HDR。第三步是Local Enhancement,主要是进行一些局部微调,至此HDR的AI生产链路就完成了。
由于HDR需要专业设备渲染,所以此次现场不再演示HDR demo,而是主要介绍其中一项非常有趣的工作。我们将Color Conversion特化成了一个调色方案,具体是如何做到的呢?
最开始是采用了大量的3D LUT去学习一些非常specific的调色风格,然后将一个视频切成不同的clip,每个clip要求AI按照视频中的场景来学习应该如何使用3D LUT调色单元,通过网络预测权重得到最终的建议调色方案。
其中的有趣点是,我们在权值特征的embedding阶段手工引入一个策略对它的latent code进行约束,例如在训练阶段可以约束一些不同的latent code指向不同的调色风格。
这种自定义调色风格可以应用在一些场景。打个比方:很多美食区UP主做菜和教程讲解做得都不错,但在菜品拍摄上有欠缺,拍出的成品饱和度偏低,让人没有食欲。该怎么办呢?实际可以通过以上方式将调色方案下放到UP主手中,通过指定菜单和latent code调整可以对UP主特化出一个具体的调色风格来支持他们的工作。
可以看到,现阶段的调色效果已经相当好了,两个演示demo中第一个是还原人眼所见色彩的调色风格;第二个有暗场增强能力,图中右侧暗处本来有块广告牌,经过调色增强后是清晰可见的。
-02-
4K实时超分
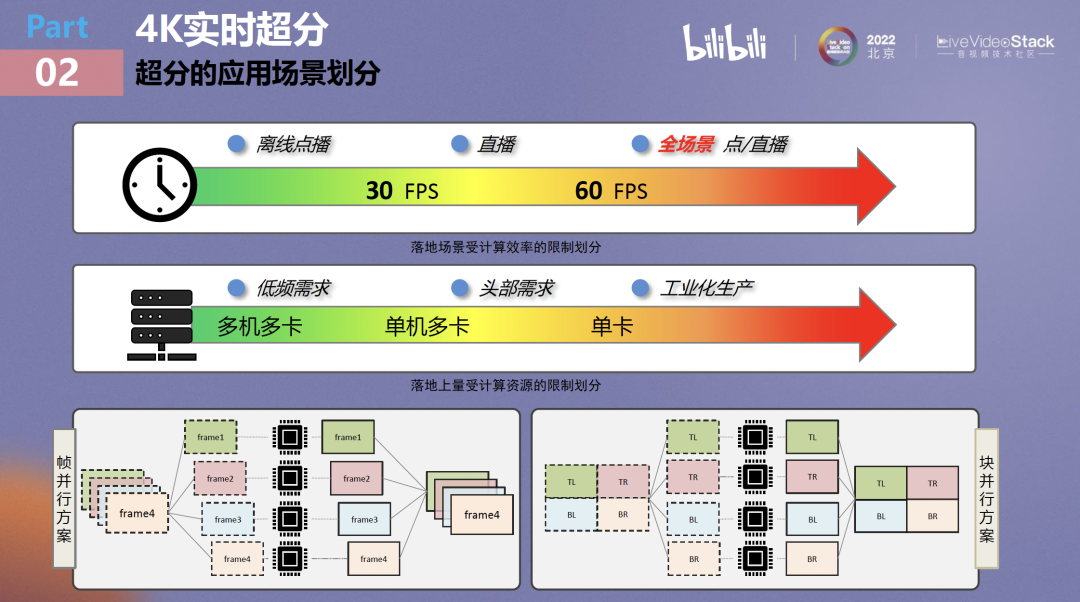
接下来主要围绕直播场景来介绍4K实时超分。我们对超分是这么理解的:超分业务被它的一些性能指标划分为不同的应用场景。
首先以超分的计算效率为例,它被两个指标划为三个应用场景。如果超分算法只能跑到30帧以下,那么就只能做点播业务;如果能跑到30帧以上,那么可以做直播;如果可以进一步跑到60帧以上,那便支持几乎所有的场景,因为一般情况下视频直播不会超过60帧。
第二,受超分算法的资源限制影响,使用场景又可被分为三个。如果跑一路超分必须多机多卡,那么势必只能去做低频需求,毕竟显卡价格太高;如果能做到单机多卡,那么可以去做一些头部需求;如果可以只用单卡支持单路甚至是多路超分,那便具备工业化生产能力。
在从前超分算法性能不够的情况下,如果还是想去做实时超分那该怎么办呢?一般会有两种思路,一种是帧并行方案,一种是块并行方案。无论哪种方案本质都是用空间交换时间,并且都有各自的问题。帧并行方案会引入同步buffer,造成额外延迟。块并行方案如果模型能力不够强,模型拼接处大部分时间会出现明显拼接缝,视觉感受非常不好。
我们去年也参与了英雄联盟S12的全程直播,实际上S12这种头部赛事也是不支持4K清晰度的,主办方为了保证所有下游直播方的服务稳定性,主推的流为1080P 60帧。但大多数用户对4K是有天然需求的,我们希望能够一步到位,单卡下支持4K 60帧的超分。这项工作非常难,不仅在于要将1080P实时超帧到4K清晰度,而且还要保持60帧的高帧率。
接下来分析一下游戏场景。游戏超分实际比普通超分要简单,因为游戏视频信号以高频重复纹理居多,如果单个地方纹理发生缺失,可以在另一个地方找回来。第二就是游戏的特征空间以及模型在学习时的参数搜索空间都非常小,与普通超分相比训练难度小。
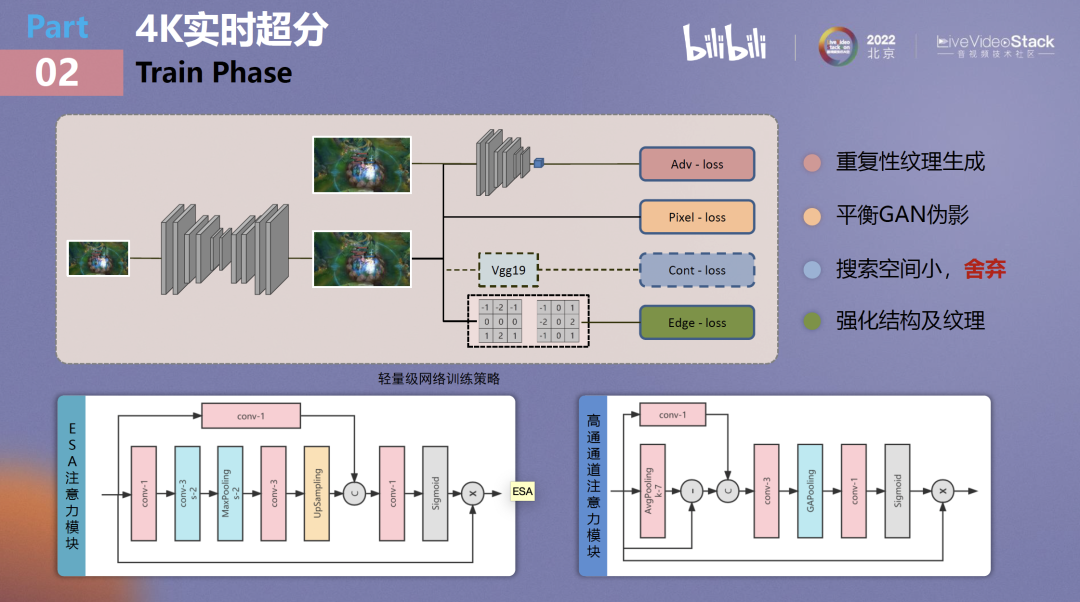
直播游戏场景还有另外一个特点,就是接到的原始流其实都经过了编码,这个问题会贯穿点直播业务始终,为了应对源流编码造成的细节损失,我们采用GAN引入对抗loss以达到重复纹理生成的目的,并且配合Pixel-loss初步约束GAN可能产生的伪影。
一般情况下,使用GAN可能还会配合使用感知loss,感知loss一般会在imagenet这种大数据量级上进行训练,但游戏画面的特征空间较小,并不需要这些非常general的特征,如果引入感知loss反而会造成训练速度降低,所以最终Cont-loss被放弃。并且为了进一步约束游戏中产生的结构化纹理,引入了基于sobel算子的Edge-loss对纹理进行强化。
在网络的具体结构上,谈一谈细微计算单元的设计思想,我们并没有使用ESA这种非常流行的空间注意力,而是设计了一个更加高效的高通通道注意力机制,可以看到该模块在开始时就通过运算简单提取到了patch的高频部分,并在最后对其进行加权得到了最后的attention权重。本方案配合接下来提到的重参数可以达到非常强的高频学习目标。
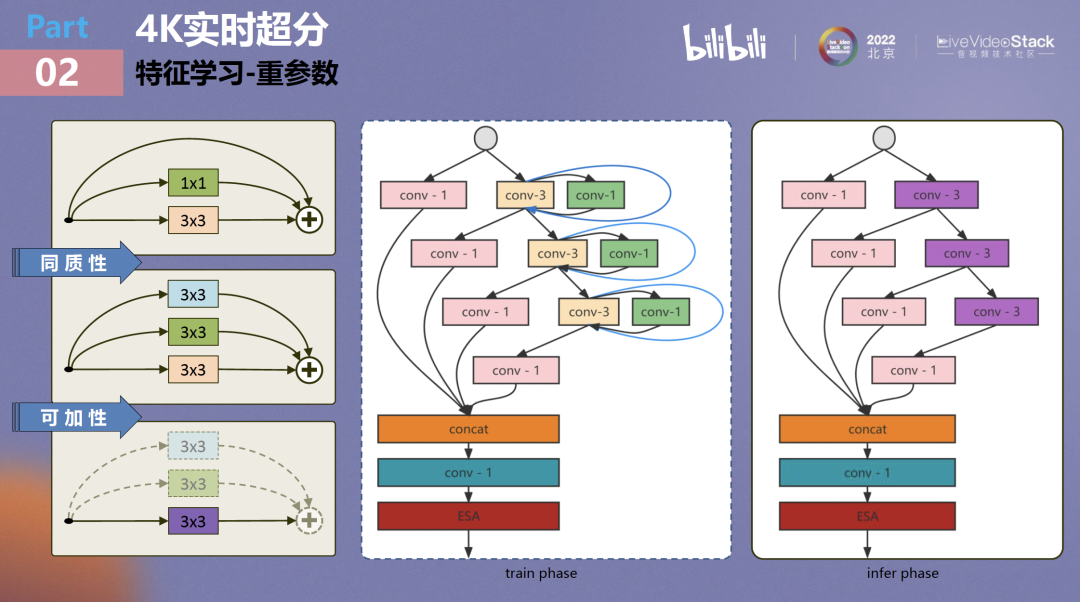
重参数的原理可以归结为,利用卷积的同质性和可加性把不同的卷积进行融合。从上图中可以看到,开始的计算结构有三个链接:一个跳跃链接、一个1×1卷积和一个3×3卷积,通过卷积的两个特性可将它们最终归并成一个3×3卷积。大家可能有疑问,为什么不可以直接使用3×3卷积呢,这是因为三个链接的学习力度是不一样的,跳跃链接、1×1和3×3对特征抽取的力度不同,所以可以使用一个很简单的策略,不增加额外计算量即可提升卷积模块的学习性能。在训练阶段采用重参数,在infer阶段则是把它归并成单个卷积。
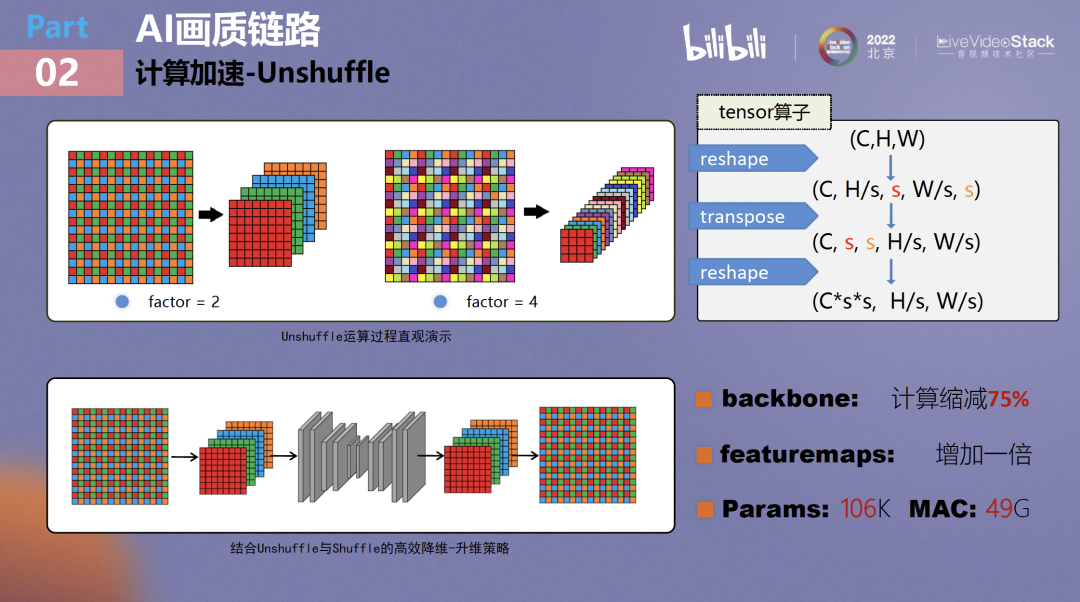
接下来介绍一个性价比最高的加速方法,叫做Unshuffle。大家可以将Unshuffle理解成Pixelshuffle的对偶。如果对超分算法了解得足够透彻,可以发现实际上目前主流的超分网络的主要计算量并不在中间的bottleneck和backbone部分,而是在featuremap相对较大的head和tail。以前如果不使用Unshuffle要如何实现降维?大概只能通过pooling或带stride的卷积两种方式。带strike的卷积会将很大计算量放在网络头部,所以效率很低;pooling可能会使特征出现人为丢失。
所谓的“Unshuffle是Pixelshuffle的对偶”这一想法貌似简单,但实际上诸如pytorch或tensorflow支持Unshuffle也就是最近这一年的事情,在没有这些工具的时候要如何去使用Unshuffle?
这其实是一个纯粹的矩阵变换问题,我们可以将它拆成三个简单的算子,使用reshape、 transpose和第二个reshape对它不同的维度进行调整,得到最后的结果。
我们还可以看到Unshuffle有个很好的特性就是它在降维时是信息无损的,它原始是哪些像素,新来还是哪些像素,在其中只要配合少量的卷积就可以达到与前述两种方式相当或者更好的画质能力。经过全局优化,backbone的计算量相对于原生网络可缩减75%,并由此可将bottleneck的宽度适当进行增加(例如增加一倍),以便让其储存到更多的特征。最后上线的游戏超分算法只用到了106K个参数,不到1M,它的计算量只有49G。
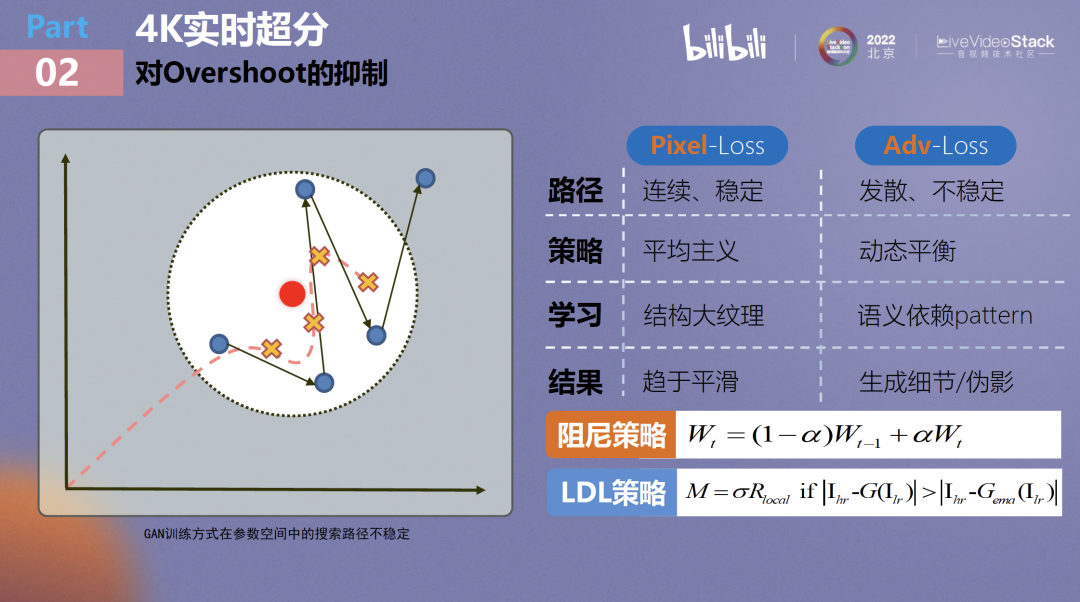
最后一个悬而未决的问题是,我们在训练策略中引入了对抗生成网络的方式,大家也提到这将大概率造成伪影的问题,怎么理解这个问题呢?把特征搜索路径以上图来进行示意,可以看到,如果不对GAN训练增加约束,它的参数搜索将极不稳定。
图中最外侧的圆代表人眼最佳的感知点,越趋近于圆心纹理应该越平滑,相反则代表出现了不必要的伪影。我们通过使用一个巧妙的阻尼策略来对每一步学习到的参数进行step by step的加权,可以将其视作对网络学习参数的滤波机制。
通过这个方法最后可以将参数搜索路径尽量平滑化,极大抑制其超出圆外的概率。并且我们也参考了CVPR2022的一篇关于Locally Discriminative Learning论文的策略。它的思想是:如果当前这个step网络所预测出的某一个特定像素与EMA网络所预测出的像素差距甚远,那就将它定义为伪影并加以惩罚。
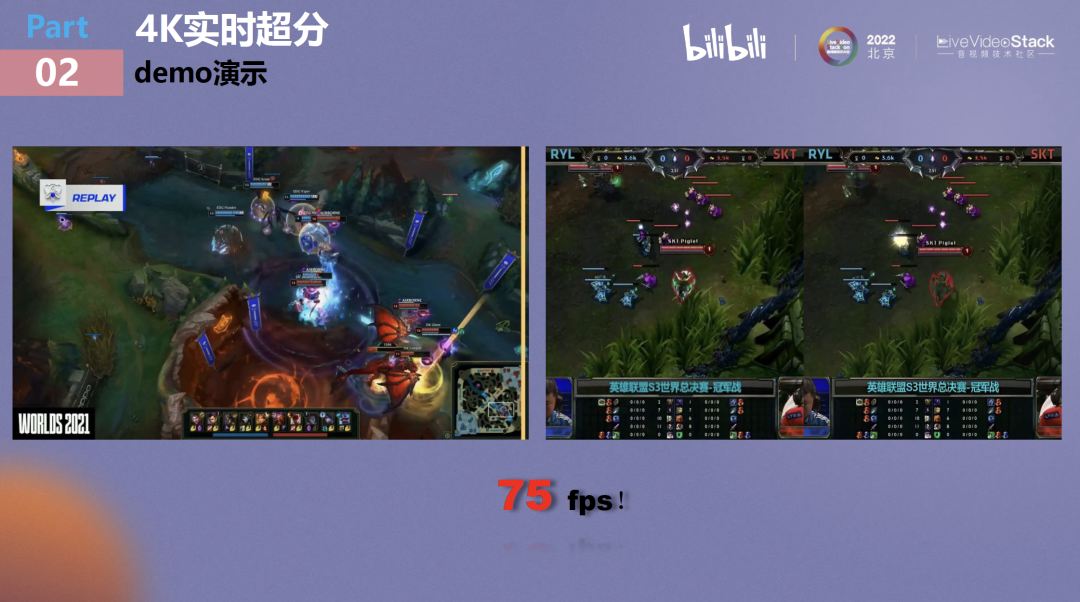
这套策略极大抑制了伪影问题。大家可以看两个demo,由于B站并没有对S12比赛做转录,作为替代方案我们在UAT环境里用S11和S3世界总决算来进行演示,这就是线上的实时效果。
可以看到,在对结构性纹理的保护和重复纹理的生成上,超分算法使原视频效果产生了极大提升。视频在V100单显卡下可以跑出75fps的帧率。B站也是在参与S12直播的平台中,唯一有4K模式的。
-03-
基于低秩重构窄带高清前处理
高画部分到此讲解结束,接下来引入到低码部分。我们本次想要介绍基于低秩重构所做的AI窄带高清前处理算法。
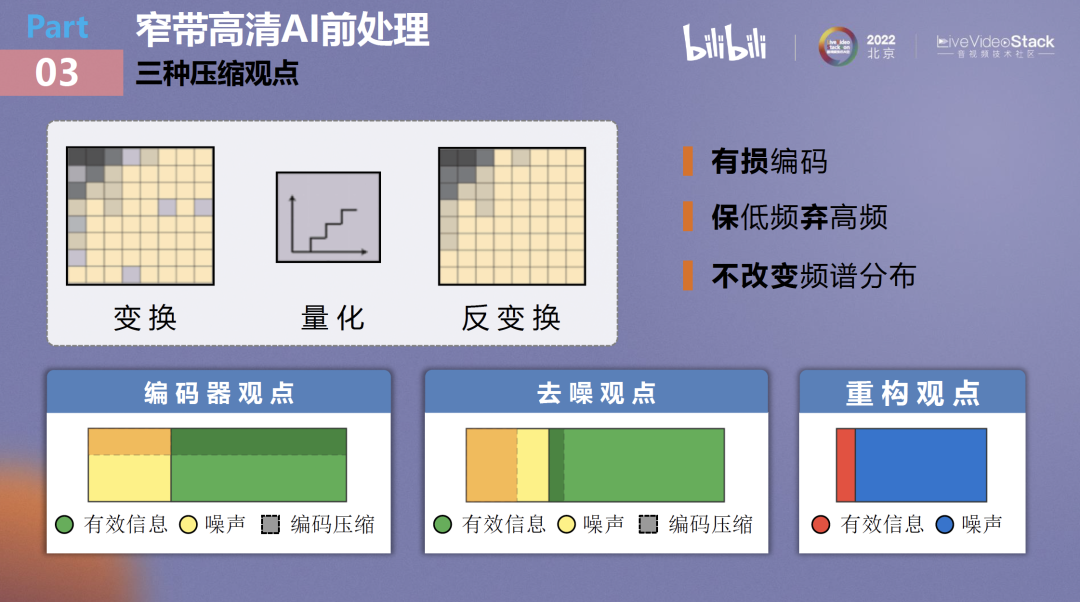
首先谈谈传统的编码观点,编码实际上是在DCT频域人为制造精度缺损以达到码率节省的目的。但可以看到,如果以高观点来看待这个问题,编码器是不关注编码单元中的内容的,它一视同仁地做有损编码,从高频到低频去相对应地去抹掉特定的频率分量。它对编码内容的频谱不做任何改变,并不知道自己压缩了什么,在压缩有效信息的同时也去压缩噪声,反之亦然。
第二个观点就是去噪观点,这也是目前做窄带高清会用到的传统方案,即通过去噪增强的方式来进行窄带高清。因为源流里已经包含了大量的编码噪声或者其他类型的噪声,可以通过增强编码流的信噪比来折中得到二次编码的效率提升。但这种方式非常依赖去噪网络的去噪能力,去噪能力要足够强,一般和工业化生产需求无法匹配。那么它在抹除噪声的同时势必也会抹除一些有效信息,最终造成画质缺损。
今天主要想要谈论的是基于一个重构观点来完成这项工作。低秩重构有两个核心出发点:第一是重构之后的图像变化对人眼来说是几乎无法认知的,第二是使用尽量少的频率分量达到与原生频率分布一样的效果,对图像进行重建。

以一个空域频谱重建的demo来做实例,上下图分别是重构前和重构后的效果,图中的细节变化是人眼不太可能感知到的。但实际上再看右边的频谱,可以发现它的频谱构造尤其是中高频部分已经和之前完全不同。它并不像编码一样造成了频谱的缺损,而是排列本身发生了变化,频率分量发生了更替,最终达到了一定的稀疏性。这是非常有利于编码器进行编码的。
低秩重构是一个非常经典的数学问题,具体描述如下:一个原始信号为D,我希望用一个重建后的信号A来表示D。E是D与A的残差。低秩重构的目标是两点,第一点是A的秩要足够低,用另外一个方式来解释就是矩阵的冗余信息要尽量少。第二点则是残差要足够小,即从某种角度上衡量,重建信号与原始信号差距不要太大。
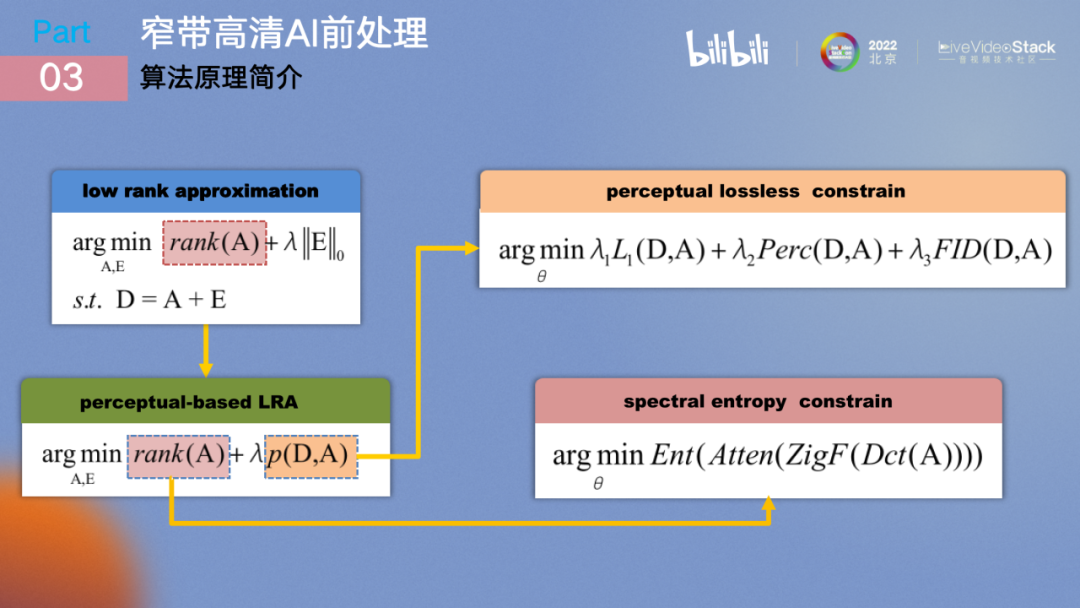
那么在算法中,以上问题被特化为两点:第一点是使用感知约束对E进行约束,使重建后的信号在感知层面与原信号没有太大差异;第二点对于A的约束则是非常难的,因为传统的低秩约束实际上是把一个非凸优化问题转换为凸优化问题,由于矩阵的秩是不可导的,所以使用神经网络来进行低秩约束是几乎是不可能的。
我们采用了一个频谱熵约束的方法来逼近它,当最终优化目标逼近频谱熵约束时,它自然就逼近了低秩约束。最终在感知约束部分我们采用三个loss来联合表征感知优化目标,第一是pixel-loss,第二是感知loss,第三是FID,在感知loss上采用的是LPIPS。
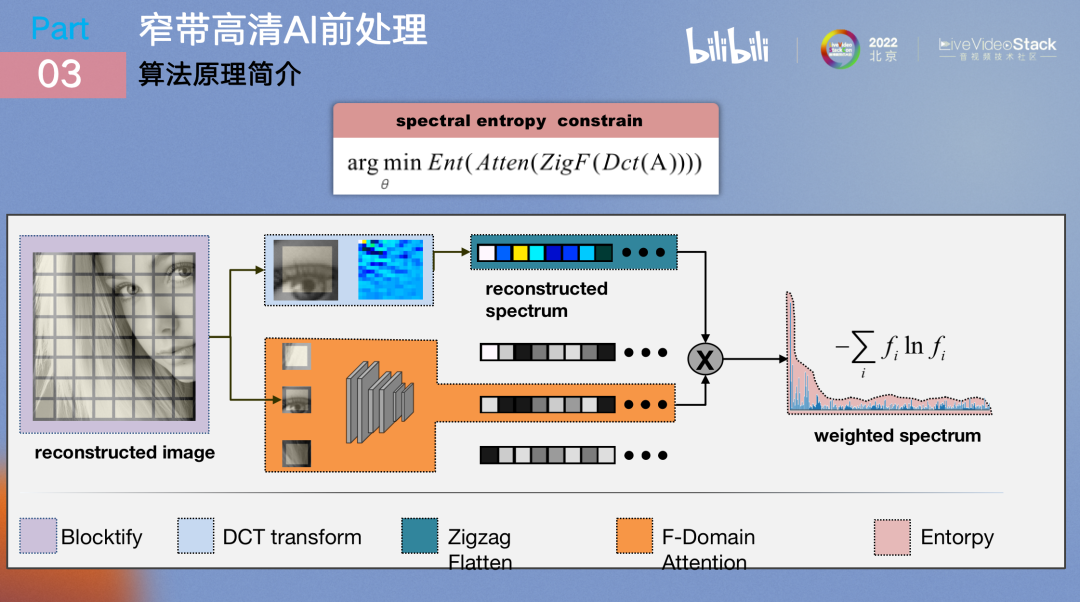
频谱熵约束在训练阶段是一个two stage的结构,图中的重建图像是已经通过stage1网络重新生成的结果,重建图像经过unfold切片以及dct变换后得到其所对应的频谱,所有块得到的频谱共同构成了频谱簇。我们在stage2中引入了可学习网络用来学习各块对应的频谱每一个频率分量的重要性,可以理解为是在频率中设立一个attention机制,经过加权叠加得到最后频谱簇的熵,使熵最小化即达到了频谱熵约束。
在网络的训练阶段则要考虑到工程中的一些常见问题和非常多的落地问题,如果大家基于上述原理去进行训练,基本上一定能达到编码收益。但想将收益最大化则需考虑非常多的trick。
在这里介绍之前也提到过的一点,怎么去处理视频编码中含编码噪声的问题。因为B站面向的直播场景都是点直播,视频源都经过了一次转码,无论如何都会携带编码噪声。在做窄带高清时需要让网络学习基本的噪声模式,为构造学习所需的典型低清高清图像对,可能大家大概率会采用的方案是将一个高清视频不断做编码,得到低清视频。
但此方法在实操上有两个问题:第一,高清视频非常难获取;第二,高清视频并没有大家想象得那么高清,本身可能也包含噪声。真正优质的数据一定是图片,但在图片内施加编码噪声难度非常大,针对图片可以考虑使用jpeg压缩,不过相对编码器来说它只考虑到了空域特性,并没有考虑时域特性。通过一个巧妙的方法,可以将时域编码引入到图片中以产生时域编码噪声。
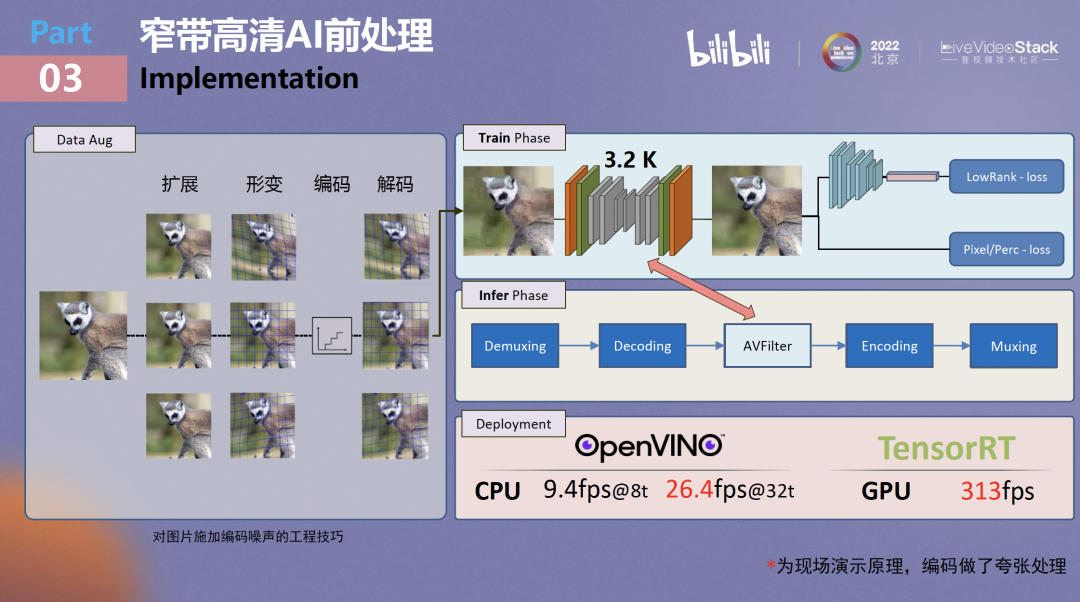
我们可以将原始图片复制成多份,在其中引入连续形变来得到一个浅显的单图生动画效果,通过人为引入形变和时域变化再对图片进行编码,最后进行特定解帧,其中有一帧是不会做任何形变的,也就是我们需要加的一帧,最终形成构造的LR/HR对。
使用这种方法可以在图像上施加编码噪声。
以上述训练策略和方法来训练网络,在实际部署阶段非常简单,它是一个frame by frame的处理,不涉及时域工作,可以无缝插入到所有基本的转码流程中来达到收益。本算法最终只用了三千个参数就达到了低秩学习分解的能力,即使在CPU上也能够得到很好的推理性能,目前基于TensorRT做T4卡的部署可以跑到300fps以上,可以满足大规模生产的需求。

以上算法虽然设计上只针对空域,未对时域做特定优化,包括在推理过程中也是frame by frame地进行时域推理。但本算法是有时域亲和力的,在时域上一个连续的patch经过低秩重构后所得的频谱会相似于原始频谱,以一个典型的室内演播厅场景为例,当码率相对比较充足时,背景看似不变,但其中包含了很多人眼难以感知的扰动,这些扰动可能是因拍摄期间的热噪声或受拍摄条件影响所致。编码器也会将码率分配到这些对于人眼来说不变化的地方。经过本算法处理后,可以看到大部分的块都被skip掉,对有一部分块则采用帧间编码方式,对真正差异较大的地方才会使用帧内编码。这样可以使编码器做到高效率码率分配,无形地提高了时域压缩性能。
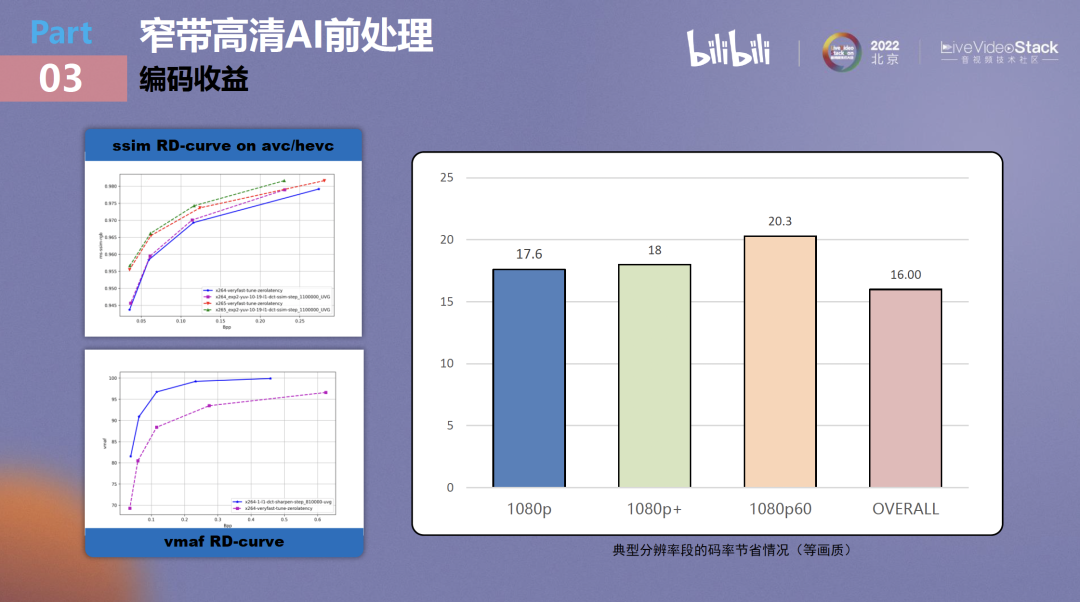
这里介绍一下编码收益,主要分三部分,第一部分是基于ssim的RD-curve,使用ssim做编码的同学都知道,ssim是比较难优化的,我们在264、265甚至在AV1上都达到了一个全局的ssim的编码收益。
如果将评价指标改为vmaf,那么收益会更大。
本算法已经灰度上线,在实际生产数据中,我们基于典型码率段做了分析,在1080P及以上分辨率可以达到18%以上的码率节省,全局也有16%的码率节省。
-04-
总结与展望
至此今天主要的分享内容结束,接下来想和大家介绍我们将持续跟进的一项工作:高糊修复。在这次LiveVideoStackCon上我们遇到了很多同行,经过交流,这也是同行们做视频云业务都会遇到的问题。高糊修复在一些特定场景有重要用途,如老片修复或一些拍摄质量极低的视频修复。
我认为目前虽然大家对高糊修复都研究了很久,但仍然没有很好的解决方案。去噪、增强、划痕修复和调色并不能解决根本的问题,高糊视频缺失了对人眼来说最基本的材质、纹理等细节。在古早片中可以发现,人物在高清处理后虽然很清晰,但衣物还有纹理缺失的现象。
为了解决这个问题,我们做了很多尝试,甚至是对早期的历史拍摄器材进行专门研究。例如老西游记电视剧使用了显像管摄像机进行拍摄,我们便研究了这种摄像机的成像原理,从镜头组到感光元器件再到最后的曝光成像介质,了解成像流程对原始画面造成了怎样的降质。
了解这个原理是非常重要的,可能和大家平时做超分或者修复预想的不同,一般超分或修复会使用一些典型的降质算子,如高斯模糊、中值模糊和各种各样的压缩,但高糊修复和前述的这些算子关系相去甚远。
近期AIGC以及大模型的兴起对高糊修复是很好的信号,可以看到LDM已经具备非常不错的图像细节修复能力,但它还不能很好地适应生产应用场景。
目前针对图像大模型调优已经出现了一些低成本调优方案,例如lora,基于lora可以对LDM像类似于condition-GAN一样的方式训练,把低清和高清pair当做condition/target,采用这样的图像对来微调大模型。
通过研究各类古早片原始画质的降质过程可以对画质改善起到很大的积极作用,我认为如果持续跟进大模型调优,它将是非常好的解决方案,可以解决很多应用上的痛点。
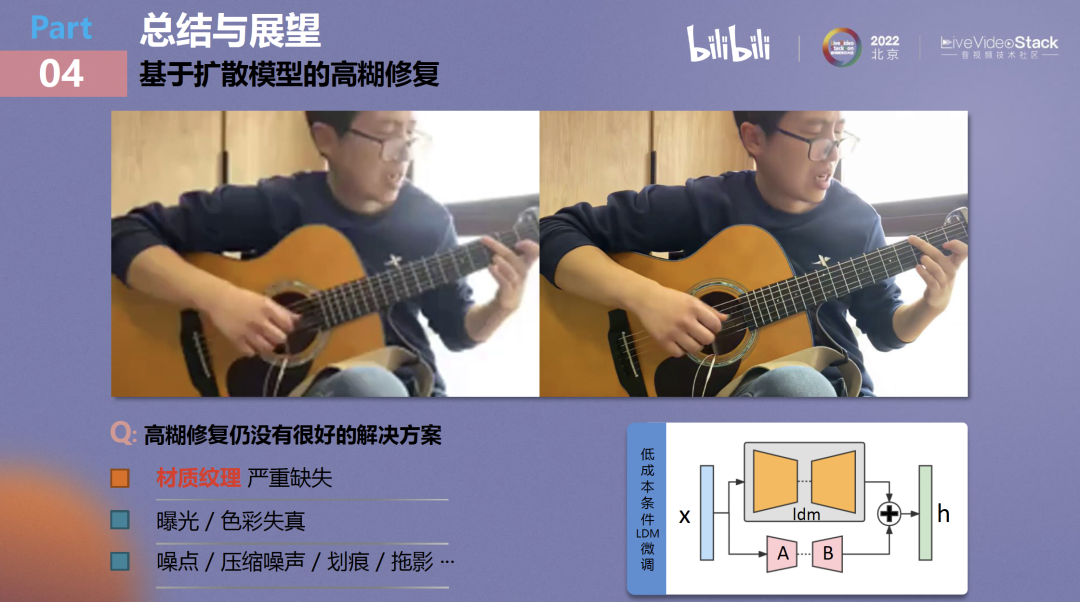
大家可以看展示的CASE,原图相当模糊。
经过大模型处理后,吉他上的木纹、衣服上的材质和柜子上的木纹等在原视频中几乎没有的材质都被进行了丰富与补充。
为了达到这个效果,还需要做很多工作去约束扩散模型产生的时域不连续问题,如果不采用一些trick进行抑制,不连续情况可能会很严重。
我相信通过后续不断的研究和应用,这些问题都会或早或晚的解决。
我认为低码高画工作非常有意思,虽然当下的环境艰难,但期间也促成了行业全体同仁优化工作的明显进步,对于技术人员也是挑战与机遇并存,相信接下来的工作仍然任重道远,谢谢大家!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
