
新兴的高质量实时通信(RTC)应用传输超高清晰度(UHD)高帧速(HFR)视频流。在传输过程中使用边缘计算传输高带宽和低延迟流。我们从一个最大的游戏公司的云游戏平台进行测量,结果表明,在这种情况下,在客户端解码器的队列往往是导致高延迟的原因,损害用户的体验。 因此,我们提出了一种自适应帧速率(AFR)控制器,通过自适应地协调帧速率与波动的网络条件和解码器容量,帮助实现超低延迟。AFR 的设计解决了两个关键问题: (1)队列测量不能为控制回路提供及时的反馈; (2)多种因素控制解码器队列,根据队列积累的原因必须采取不同的行动。跟踪驱动的仿真和大规模的部署都表明,AFR 可以减少高达 7.4 倍的尾部排队延迟,端到端延迟测量的卡顿事件平均减少 34% 。AFR 已经在我们的云游戏服务中部署了一年多。
来源:NDSI 2023
论文链接:https://www.usenix.org/system/files/nsdi23-meng.pdf
原文标题:Enabling High Quality Real-Time Communications with Adaptive Frame-Rate
内容整理:尹文沛
1. 介绍
像 5G 这样的新兴网络技术已经使学术界和工业界对高质量的实时通信(RTC)应用感到兴奋,这些应用具有超高清晰度(UHD)、超高帧率(HFR)和很小的延迟。例如云游戏 ,虚拟现实和4K 视频会议。一些高质量的 RTC 服务已经部署在生产环境中(例如 Google、 Microsoft、 Nvidia的云游戏)。例如,云游戏的市场份额在2020年达到10亿美元,预计增长率为30%。
为了获得满意的用户体验,这些应用程序需要具有高分辨率、高帧率和低延迟的流($2)。例如,云游戏服务提供分辨率≥1080p 和帧率为 60fps 的内容,同时需要尾端到端延迟小于100ms。像这样的流显著地改善了用户的体验,并支持新的应用。
本文认为,除了调整比特率以匹配网络容量外,一个高质量的 RTC 系统还必须调整解码器队列中的队列。对于传统的标准质量 RTC,解码帧所需的时间比帧之间的到达时间短得多。因此,解码器队列不是一个瓶颈,传统的 RTC 服务只需要调整比特率来匹配网络带宽。 然而,在高质量的 RTC 中,高帧率减少了帧到达客户端之间的时间,而高分辨率增加了每帧的解码延迟。在解码器队列中,帧到达率经常超过离开率,导致队列很长,如图 1 所示。 视频传输不仅需要使比特率适应网络带宽,而且需要与解码器队列容量相协调。通过测量我们的云游戏服务,Tecent Start ,我们发现视频传输不协调队列容量可能会在客户端解码器队列中引入不可忽视的队列延迟。此外,这种排队延迟占了延迟帧的很大一部分,以满足高质量 RTC 更严格的延迟要求,特别是当网络延迟随着最近的基础设施发展而减少时(例如,边缘计算)。
根据我们的测量,在所有总往返延迟 > 100ms 的帧中,57% 的帧在解码器队列中延迟 > 50ms (3.1)。我们的调查发现,UHD 和 HFR 视频的未来需求将进一步加剧这一问题,即使随着解码硬件的发展(3.1)。因此,对于高质量的 RTC 来说,要减少端到端时延,就必须减少译码器的排队时延。
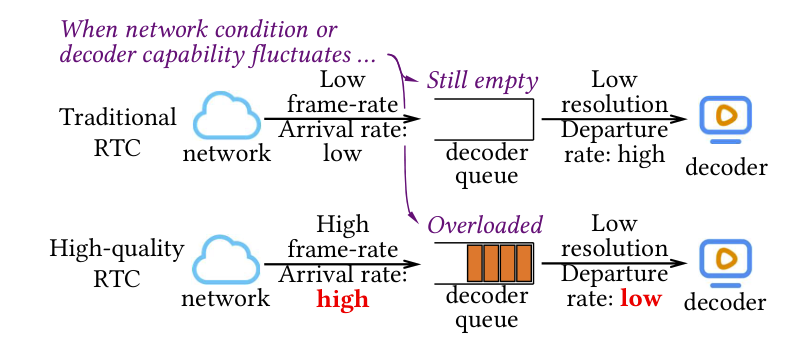

并非所有的干预措施都能有效地调节解码器队列中的队列(3.2)。例如,译码延迟不会受到比特率的很大影响。它受分辨率的影响,但调整分辨率需要客户端请求一个新的关键帧。这会消耗带宽并产生几个额外的帧间隔延迟。在客户端丢弃一个帧也需要一个新的密钥帧,这会带来相同的成本。因此,我们引入一个自适应帧速率(AFR)控制器,控制编码器的帧速率。降低帧速率使译码器有更多的时间处理帧。因此,它在减少队列长度方面是有效的。此外,边缘流服务提供了较短的 RTT,这意味着用于调整编码器帧率的控制回路较短。
注意,以前已经有过调整帧率的努力 (CU-SeeMe 数十年前)。然而,近十年来解码硬件的发展使得解码器变得多余,而传统的实时传输控制在近十年来大多受到网络瓶颈的制约。在本文中,我们展示了高质量的 RTC,具有 UHD 分辨率、 HFR 和严格的延迟要求,如何改变了这种情况。我们从两个方面进一步改进这些建议。首先,现有的控制机制是基于延迟或队列长度的,这些机制反应较慢,因为它们需要等待队列建立起来。相反,AFR 依赖于到达和服务进程以及队列长度来调整帧率。其次,并非所有增加的译码排队延迟都需要降低帧率。例如,当队列延迟由于到达数据包的瞬时爆发而增加时。因此,AFR 使用两个控制回路,在不同的时间尺度上调整帧率。
我们在模拟器和从腾讯的云游戏服务生产上都实现了 AFR 控制器。跟踪驱动仿真和实际部署表明,AFR 可以有效地减少尾部排队延迟高达7.4 × ,从而减少总延迟测量的帧卡顿率高达2.2 × (6.1和6.5) ,开销可以忽略不计。自2021年2月以来,AFR 已经在腾讯开始部署,为数百万会议提供服务。我们会释出收集到的网络轨迹和模拟代码。
我们做出了以下贡献:
- 我们进行了为期一个月的测量活动来评估控制解码器队列中队列延迟的重要性,并找出了具有严格延迟要求的高质量 RTC 所带来的独特挑战。
- 我们设计了一个分层的帧率控制器,AFR,来控制解码器队列在不同场景下的超短时延,以获得高质量的 RTC。
- 我们通过网络轨迹模拟和实际生产中的大规模部署来评估 AFR。我们的评估表明,无论是排队延迟和总端到端延迟可以显着改善。AFR 已经在部署中使用了一年多。
2. 背景:高质量 RTC
高质量的 RTC 应用正在引起业界和学术界的关注。最近发布了一系列高质量的 RTC 产品,包括云游戏,虚拟现实(VR)和4k 视频会议。例如,通过生成高质量的内容并通过互联网流向用户,用户可以通过低成本的设备享受更好的视频质量。具体来说,高质量的 RTC 在传统的 RTC 应用程序中有以下突出的特点:
- 高帧率:传统 RTC 一般只传输 24 fps 的低帧率内容。然而,高质量 RTC 要求帧率达到 60 fps,一些甚至要求 240 fps。
- 高分辨率。更多现有的 RTC 应用默认以 SD 分辨率进行传输(360p for Google Meet)。相反的,高质量 RTC 应用要求 1080p 到 4K 的分辨率,甚至会更高。
- 严格的时延要求。更进一步,高质量 RTC 应用也有严格的延迟要求。比如说,视频会议要求 150ms 的往返互动延迟和以及 100ms 内的游戏延迟。
现有的传输系统。为了进一步理解高质量 RTC 的瓶颈,我们在图 2 中展示了现有 RTC 传输系统的关键组成部分。首先,视频编码器抓取从视频源生成的内容(游戏应用),并将起编码为视频帧。然后,编码帧通过网络从流服务器被发送到客户端。然后,在客户端,一旦从网络中收到新帧,解码器就会解码这些帧。最后,解码后的视频帧会被渲染到用户的显示器上。
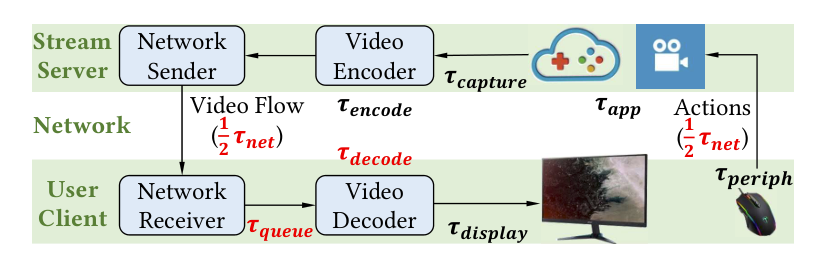
优化目标:低的尾部延迟。在最近的研究工作中,对每个组件的延迟都进行了深入的优化。 为了减少网络延迟,现有的提供商要么在边缘部署流服务器,引入低延迟拥塞控制器,或建议用户使用有线连接。例如,最近的测量显示,云游戏服务可以提供平均来回网络延迟 20 毫秒的 RTC 流。类似地,流式编码器针对低延迟进行了优化,以满足高质量 RTC 服务中严格的延迟要求。
同时,优化尾部性能对于高质量 RTC 的用户体验也是至关重要的。尾部延迟的增加将导致帧卡顿或冻结,降低用户的体验。视频流中的体验评估框架的质量通常单独计算卡顿时间作为对用户体验的惩罚。考虑到高质量 RTC 的高帧率,需要进一步关注第 99 或第 99.9 百分位的尾部。例如,在帧速率为 60fps 的情况下,即使是第 99.9 个百分点的延迟也可能每 16 秒发生一次。特别是对于像云游戏这样的应用程序,这样的延迟可能会导致游戏的失败(例如,当玩家在射击游戏中被对手发现时停止)。因此,对于高质量的实时跟踪控制来说,控制跟踪延迟和减少帧卡顿是非常必要的。
3. 动机和挑战
在这一部分中,我们首先解释了高质量 RTC 中极端排队延迟的表达式(。然后,我们提出了我们选择调整帧速率的设计思想3.2)。我们最后分析了有效实现一个超短队列的独特挑战($3.3)。
3.1 动机:极端的排队延迟
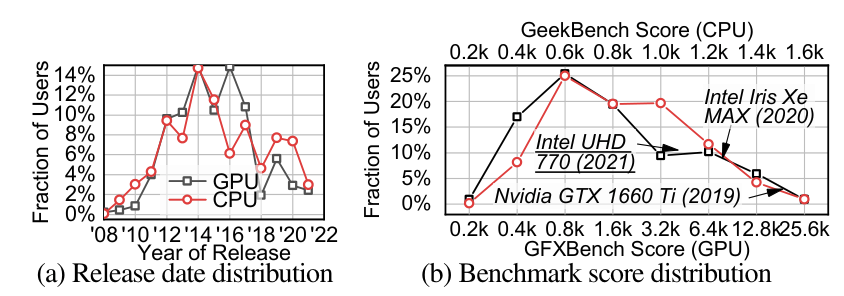
观察:解码队列延迟是总延迟在尾部的重要组成部分。在图 2 中,我们描述了交付管道中每个阶段的每个帧的延迟。在2021年,我们在 Tecent Star 中进行了一个月的测试。其中包括成千上万的用户以及成千上万个不同的 CPU 和 GPU 模型。我们在图 3 中展示了 CPU 和 GPU 的发布日期和基准评分,并在附录 B.1 中列出了顶级型号。除非另有说明,本文中的所有测量都是从这个数据集中进行分析的。

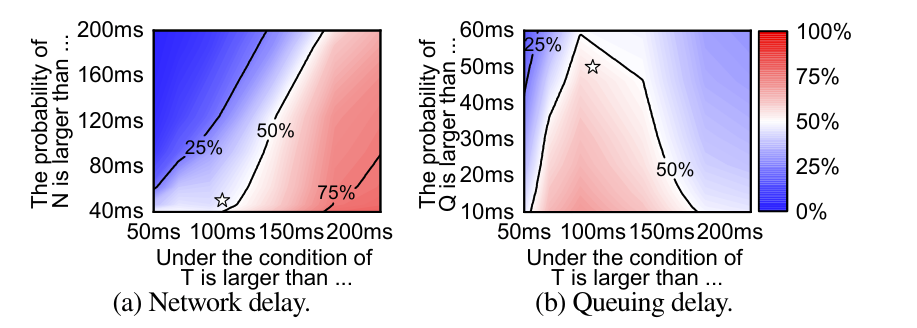
正如我们所看到的,当分析传统 RTC 服务中 T>200ms 帧的根本原因时,网络延迟有很高的概率(红色阴影,表明造成 200ms 总延迟的主要原因是网络延迟)。然而,当分析 T 大于100ms 的帧时,排队延迟主导了总延迟的增加。我们的测量结果显示,在所有端到端总延迟超过100ms 的帧中,排队延迟的增加比所有其他组件延迟发生得更频繁: 其中 57% 的帧的排队延迟超过50ms (图4中的星)。考虑到对高质量 RTC 的严格延迟要求(100ms左右),排队延迟的增加起着主导作用。
根本原因:UHD 分辨率和 HFR 联合导致了排队延迟的增加。与 LFR 流相比,HFR 通过减少帧间的到达时间来提高解码器队列的到达率。此外,UHD 通过增加每帧的解码延迟来降低离开率。
具体来说,我们通过图5中显示的 99%ile 队列利用率来说明帧率和分辨率如何影响解码器队列的负载。我们从测量到其他帧速率和分辨率的转换时间和解码延迟的分布进行缩放。正如我们所看到的,对于传统的 RTC 服务(左下角) ,由于他们的低帧速率和分辨率,解码器队列仍然有一个 ρ 在尾部的利用率。然而,对于高质量的 RTC 应用程序(右上角) ,解码器队列将被大量加载,导致严重的队列延迟。
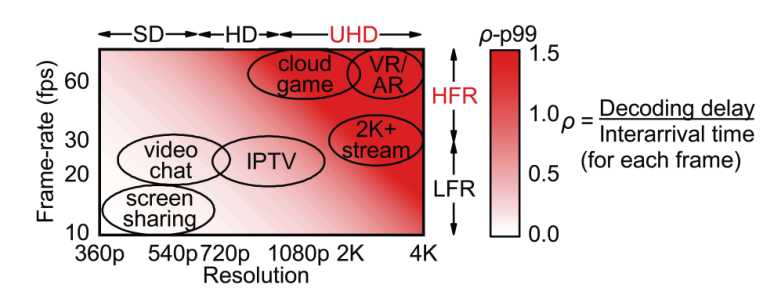
问题在于解码器的平均性能和尾部性能不一致。事实上,我们测量的许多硬件解码器声称支持 UHD 和 HFR 视频(例如,表4中的 Nvidia GTX 系列)。然而,根据我们的测量,支持 UHD 和 HFR 并不意味着持续支持。例如,由于客户端过热,CPU 调度(5.1)和预测错误等许多原因,解码延迟可能会波动,所有这些都是应用程序难以控制的。根据我们对正在生产的设备的测量,即使有硬件加速,解码延迟在第99百分位也是18ms (附录 B.2)。请注意,在帧速率为 60 fps 时,帧之间的到达时间为 16.7 ms,导致尾部的解码器队列负载过重。
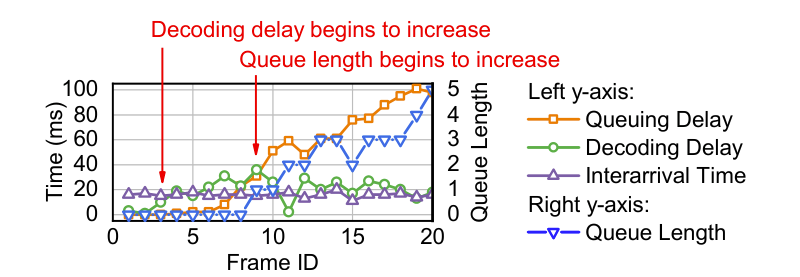
我们进一步分析了附录(B.3)中其他组件增加与总延迟之间的充分必要条件,发现解码延迟的微小波动导致了排队延迟的增加。根据排队论,当队列负载很重时,队列延迟将急剧增加。这是因为当译码延迟不断波动时,排队延迟积累了先前帧的所有波动。特别是在流量大的情况下,译码延迟的微小波动会导致排队延迟的大幅度增加。我们请读者参阅以获得更多的理论分析。举例来说,我们在图 6 中展示了来自生产服务的跟踪。在跟踪中,到达间隔时间为 16ms,解码延迟为18ms,排队平均延迟为54ms。译码延迟的不断增加,虽然幅度不大(18ms) ,持续时间不长(20帧,大约0.3 s) ,导致了剧烈的排队延迟。如果这样的跟踪以 1% 的概率发生,那么我们将有 18ms 的 99% 解码延迟和 55ms 的 99% 排队延迟。在这种情况下,尾部排队延迟比译码延迟高得多,这也导致了一半以上在 3.1 中分析的端到端卡顿。
趋势: 硬件解码器无法跟上 UHD 和 HFR 视频日益增长的需求。用户对视频的需求急剧增加,如图7(a)所示。例如,YouTube 支持的最高分辨率和帧速率已经从2005年的360p@30fps (7Mpx/s)增加到2015年的8K@60fps (2Gpx/s) ,平均每14个月翻一番。16K或240fps的新兴服务进一步表明了 UHD 和 HFR 流的未来需求。
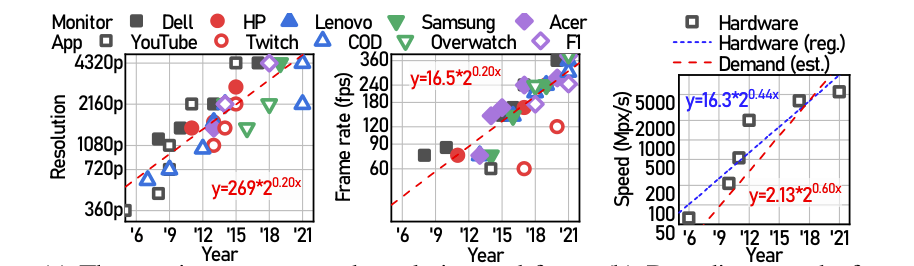
然而,硬件的解码速度却没有这么快。我们从最近的学术论文中总结了最先进的视频解码器的解码速度。如图7(b)所示,最先进的解码硬件的解码速度大约每27个月翻一番(蓝色虚线)。与此同时,我们还通过将图7(a)中的估计分辨率和帧速率乘以现有视频需求来计算所需的解码速度,并在图7(b)中用红色表示估计值。需求所需的解码速度,每20个月翻一番(红色虚线)比解码硬件(蓝色虚线)的发展快得多,表明 UHD 和 HFR 视频的解码硬件解码能力不足。
除了最先进的硬件之外,我们的用户中还有相当数量的低端和中端设备。用户设备,即使在同一代,也可能是非常异构的。例如,在图 3 中,请注意 Intel Iris Xe 的性能比 Intel UHD 770 好 2 倍,尽管后者更新。因此,即使在同一代中,用户设备也存在异构性。 此外,新的视频编解码器(例如 H. 265)虽然压缩比较高,但甚至可以将解码速度降低 60%。在这种情况下,解码器与 UHD 和 HFR 视频之间的不匹配将进一步加剧,使尾部的排队延迟成为一个持久的问题。
3.2 选择:控制合适的参数
我们需要调整帧率。对于编码器,有三个可以独立设置的参数,包括帧率、比特率和分辨率。该编码器将根据当前内容自动优化其他参数(如量化参数) ,以实现目标帧率、比特率和分辨率。有关视频编解码器的更多细节,请参阅。
我们首先分析了这些参数如何影响不同组件的延迟。当比特率增加,网络延迟(network delay)会因为拥塞而增加。当分辨率增加,因为解码器需要解码更多像素的帧,它需要更长时间去解码。排队延迟取决于入队率(帧率),和出队率(解码延迟)。相反,比如说,如果比特率降低,分辨率保持不变,由于编解码器的硬件设计,每帧的解码延迟几乎不会减少,我们在附录 B.4中进一步测量。因此,依赖总延误(例如 Salsify)会导致在采取有效行动以减少延误方面含糊不清。
因此,我们需要单独控制各个参数去减少不同的延迟。相应地,我们调整帧率去控制高质量 RTC 的排队延迟。当解码器和网络的波动导致排队延迟增加时,必须调整编码参数以减少排队延迟。在这种情况下,当收集好来自客户端和网络的测量后,在服务器端的编码器将会相应地调整未来发送帧的帧率。我们可以动态地指定新帧编码的时间戳。
在附录 A 中,我们进一步讨论了几个可能的解决方案和关注的问题。总之,由于带宽的巨大开销,调整分辨率或丢弃帧是不切实际的。由于运行时解码延迟的波动,基于客户端模型静态选择帧率也是不够的。此外,由于应用程序对用户系统的控制有限,因此为大规模生产级服务控制用户系统(例如,将应用程序固定在 CPU 核上)也是不切实际的。在帧速率自适应方面,请注意以前在帧速率自适应方面的努力(例如,几十年前的 CU-SeeMe)。然而,正如我们在 3.1 中所讨论的,随着分辨率和帧率的提高,以及严格的时延要求,我们需要再次强调适应帧率的重要性。我们还表明,在网络上控制帧率是足够及时的。
3.3 挑战
实现一个超短队列。为了实现解码器队列的超短队列延迟,在需要采取行动时,挑选合适的指示器来通知控制器是一个挑战。现有信号(队列长度或队列延迟)无法实现超短的队列延迟。由于解码器队列的积累是到达或离开过程波动的结果,因此队列长度和队列延迟只有在队列已经建立时才能观察到。对于图 6 中的示例,当解码延迟在第3帧开始增加时,非零队列长度只能在第 9 帧中观察到。我们还在 5.2 中根据队列长度和队列延迟来评估基线。
作为响应,我们希望捕获最早的信号(earliest signal)来感知潜在的排队延迟。因此,我们不需要测量排队延迟,而是需要预测排队延迟的潜在增加量。然而,就尾部而言,到达过程也是波动的,这也可能导致排队延迟的增加。例如,在第 99 百分位时,网络延迟可能比中位数增加 10 倍。针对这一问题,我们基于排队论原理,全面测量到达和离开过程,控制排队延迟。我们在 4.2 中介绍了设计,并在 5.2 中评估了测量到达过程的必要性。
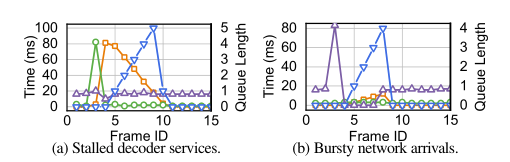
处理各种事件。更进一步,高质量 RTC 中解码器队列形成的原因是复杂的。正如我们在 3.1 中介绍的,解码容量的平稳降低可能导致解码器队列的积累,例如图 6 中展示的结果。此外,解码器队列也可能由于暂态偶然事件而累积。例如,根据我们的生产经验,解码器可能偶然地经历 100 毫秒的解码延迟(例如,图8(a)中的第 3 帧)。无线信道中的突然干扰也可能导致多个帧的突然到达(例如,图8(b)中的第4至第8帧)。在这两种情况下,解码器队列将被累积。由于这些暂态波动发生得很突然,控制器很难通过测量排队和出队速率来作出反应。
因此,AFR 区分了队列积累的原因,并分别对不同时间尺度上的波动作出反应。 我们设计了一个平稳控制器来避免繁忙交通(4.2)中的队列积累,以及一个暂态控制器来减少偶然事件(4.3)中的队列延迟。
4. 设计-自适应帧率
我们首先分析了 AFR 总的工作流程,然后展示了 AFR 的两个控制器设计。
4.1 工作流程
AFR 的工作流如算法 1 所示。具体地说,所述平稳控制器(4.2)是基于动态排队和出队过程,来维持一个超短延迟目标的队列。通过测量两个过程的统计量,AFR 基于排队论计算排队延迟的期望值。因此,帧率可以针对给定的排队延迟目标(第1行)进行优化。暂态控制器观察队列状态 Q (队列长度和队列延迟)并计算折扣因子 α (行2) ,以进一步降低队列形成时的帧率。最终的帧速率是由 α (第3行)调控的平稳帧率 f0。在这种情况下,AFR 可以对不同的队列积累场景做出反应。

4.2 平稳控制器
(在 G-G-1模型中,G-G-1的含义如下:
- 第一个 G: 到达过程(到达过程)。这里的 G 表示“一般”或者“任意”,意味着到达过程可以是任何分布,不仅限于常见的泊松过程(泊松过程)。在泊松过程中,顾客之间的到达时间服从指数分布。在 G-G-1模型中,到达时间可以服从任意分布。
- 第二个 G: 服务过程(服务过程)。同样,这里的 G 表示“一般”或者“任意”。在 G-G-1模型中,服务时间可以是任意分布,不仅限于指数分布。服务过程描述了顾客需要的服务时间以及系统中资源完成服务的能力。
- 1: 服务设施的数量。在 G-G-1模型中,只有一个服务设施,这意味着在任何给定的时间,系统中只能处理一个顾客。 G-G-1模型比较一般化,因为它不对到达和服务过程做特定的假设。然而,这种一般性也导致了 G-G-1模型的解析解很难获得。为了计算 G-G-1模型中的排队指标,通常需要借助于数值方法、模拟或近似方法。)




然而,由于突然到达或停滞的服务(4.1) ,到达和服务过程都可能有显着偏差的值。例如,图8(a)中的第3帧的解码时间为82ms,而其他帧的解码时间低于4ms。这种异常值将在很长一段时间内严重偏离对平稳统计数据的估计。事实上,正如我们在4.1中所讨论的,这些或有事件被设计为由瞬态控制器来处理。因此,我们需要滤除这些异常值,以精确估计到达和服务过程的平稳状态。由于解码延迟的高度偏态分布,现有的基于标准差的异常点去除机制(例如,three-σ 规则)难以区分异常点的定态转换。
为了捕捉解码器状态的转换,同时消除偶然异常值的影响,我们引入了一种基于生产测量中先验知识的异常值去除机制。关键的直觉是解码延迟差异(Sn-Sn-1)与成为异常值的概率有关。例如,解码延迟增加 20ms 可能是平稳状态之间的转换(图6)。然而,在解码延迟上突然增加 80ms 可能表明解码延迟是一个异常值,这通常是图8(a)中偶然停止的情况。这是因为商业解码器通常能够以平均每秒24帧的帧率解码帧。根据我们的测量,当解码延迟差异大于50毫秒时,该帧成为异常值的可能性为95% 。因此,我们去除了平稳控制器中解码延迟差大于50ms 的帧,并将这些帧的控制留给瞬态控制器。
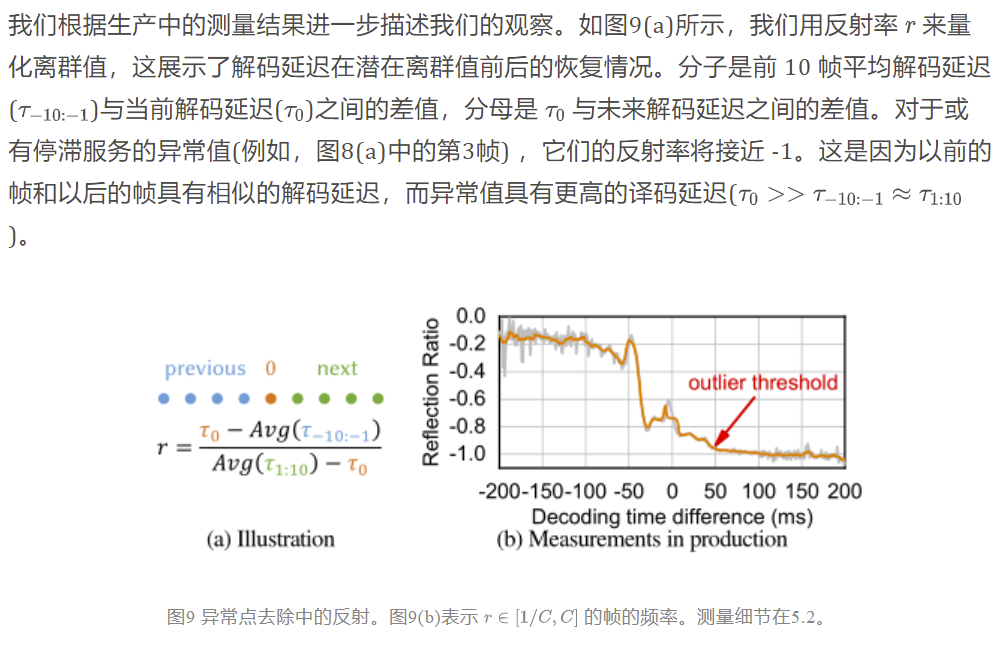

4.3 瞬态控制器
暂态控制器设计用于处理偶然性的队列累积(4.1)。因此,我们首先需要了解应该如何应对这些队列偶然事件。
理解队列偶然事件。如图8(a)和8(b)所示,解码器服务停滞和网络突发到达都会导致队列长度突然增加。我们在图 10 中演示了两个偶然事件的进队和出队事件。在图10(b)中,5 帧在 4ms 内一起到达客户端,当第 5 帧到达并观察时,队列长度为4,如 LQ (蓝色箭头)所示。在图 10(c)中,当排队的帧不能出队到解码器时,解码器需要 80ms 来解码第 0 帧。因此,当第5帧到达时,它也观察到一个4的队列长度。
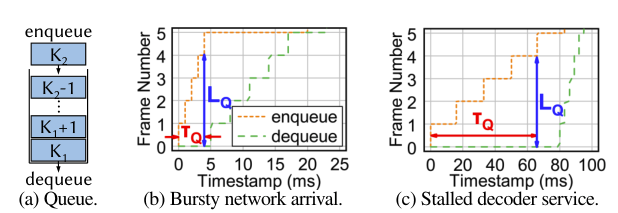
然而,突发的网络到达和停滞的解码服务应该分开处理。在突发网络到达的情况下,由于网络时延较长,总时延的瓶颈仍然存在于网络中。只要解码器正常工作,即使多个帧同时到达队列,也可以有效地处理它们(图8(b))。在这种情况下,队列将在短时间内耗尽,我们不需要降低帧速率。相比之下,停滞的解码器服务将大大增加后续帧的排队延迟,并需要适应(图8(a))。因此我们需要区分这两种场景。

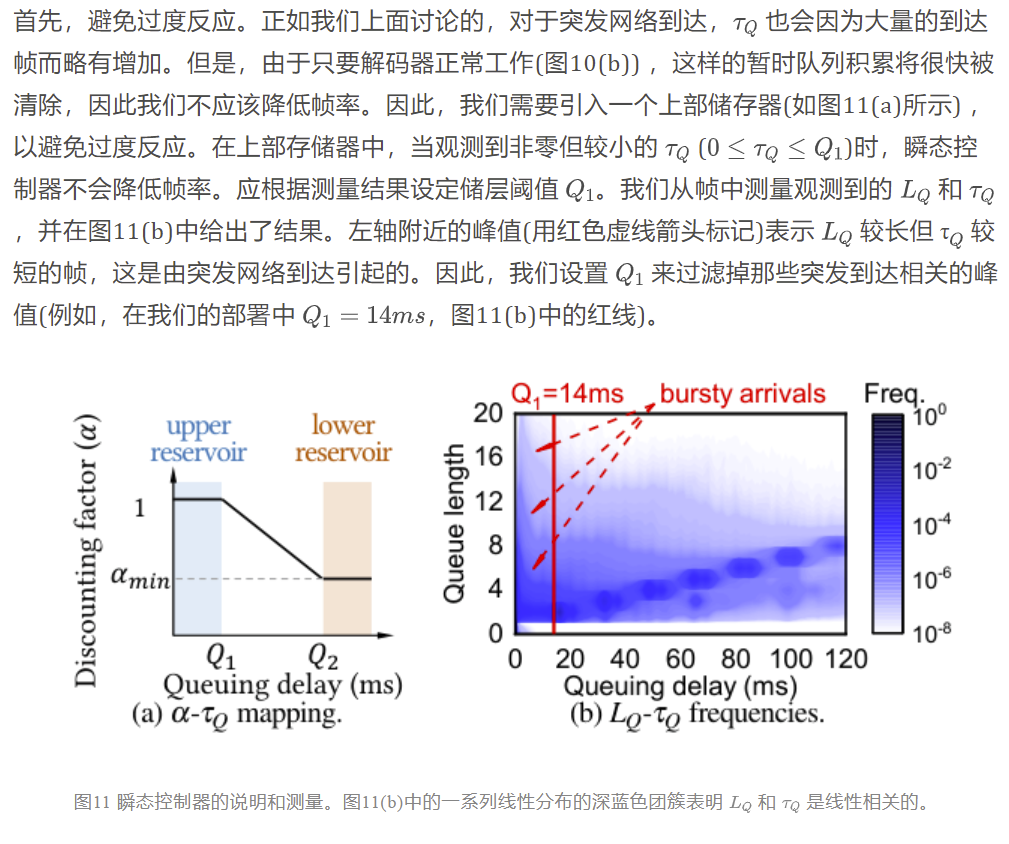

5.实现
我们使用帧级跟踪驱动模拟器实现 AFR,并将 AFR 部署到实际生产的高质量 RTC 服务上。在本节中,我们将介绍我们的模拟器(5.1)的设计,介绍模拟设置(5.2)和部署设置(5.3)。
5.1 模拟器设计
为了忠实地比较和重现不同队列控制算法的跟踪,我们设计了一个简单的仿真环境,对 RTC 进行动态建模。模拟器维护解码器队列,并重现从在线服务收集到的跟踪信息,其中 trace 信息包括解码延迟、网络延迟、原始队列延迟以及每帧的到达时间戳。具体地说,帧根据 trace 中的时间戳到达解码器队列,在解码器队列中等待出队,并根据 trace 中的解码延迟进行解码。为了避免频繁地向服务器发送帧率调整请求,帧速率被量化为 5 fps 的水平,这也是我们的在线部署所遵循的。我们实现了来自 CPU 时间片的潜在干扰: 由于帧获取到解码器取决于 CPU,所以有可能的情况下,从队列获取帧到解码器需要等待 CPU 调度多达几毫秒。因此,我们进一步在 trace 中分析了这种延迟和并在我们的模拟器中引入了调度等待时间。我们还实现了编码器的响应时间,即新帧率动作(到达编码器的时间)和以新帧率生成新帧的时间之差,测量实现在 6.4 节。
5.2 模拟设置
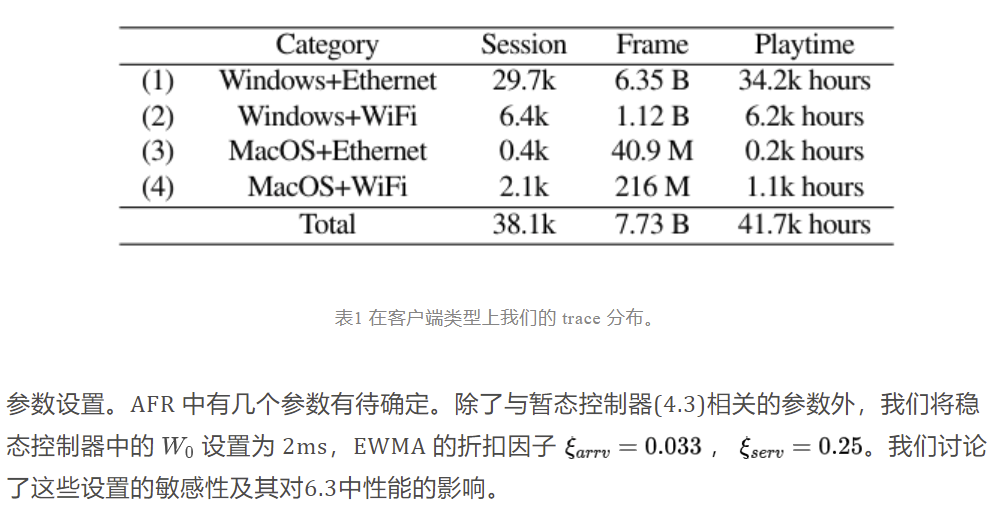
Traces。我们在两种类型的客户端(Windows 和 MacOS)和接入网络(以太网和 WiFi)上测量我们的云游戏服务(3.1中引入)的帧级统计数据。在2020年12月的24天里,我们在一个生产集群中分析每一个接收帧的步骤。这导致了一个包含77.3亿帧和41.7 k 小时游戏时间的数据集(表1) ,据我们所知,这是交互式流媒体最大的帧级数据集。
Metrics。在评估中,我们主要测量延迟(包括排队延迟和端到端总延迟)。正如我们在第 2 节中所讨论的,交互式流媒体的延迟与其他视频质量指标(例如,PSNR 或 SSIM)是正交的。延迟是本文的主要优化目标,它代表了交互性。我们证明在 6.4 中,AFR 对视频质量的影响可以忽略不计。
基准。为了评估 AFR 的性能,我们实施了以下现有的帧控制机制:
- DropTail 是 WebRTC 中的帧控制机制。当帧溢出队列时,客户端将首先清除队列,然后请求一个新的关键帧,最后删除所有帧,直到下一个关键帧到达。我们将队列容量设置为16帧。
- QLen-S 观察当前队列长度,如果队列长度大于等于 1,则在编码器之前跳过内容生成器中的帧,如果队列长度 < 1,则继续执行。
- QWait-S。我们从模拟器中现有的学术成果中移植了帧控制机制,并将信号从总延迟替换为排队延迟,以更好地减少排队延迟。由于这些基线不是为100毫秒的严格延迟要求而设计的,因此我们根据我们的 trace 来微调它们的参数。如果排队延迟大于等于 32ms,则 Qwait-S 在编码器之前跳过帧,如果排队延迟小于4ms,则继续。
此外,为了评估不同成分在 AFR 中的有效性,我们还对 AFR 的不同变体进行了分析:

我们提出了如何调整参数,并在 6.3 节中评估帧率和排队延迟之间的权衡。
5.3 部署设置
我们最终将 AFR 部署到我们的云游戏服务上。游戏服务 X 使用 H.264 编解码器来增加硬件解码和适应异构客户的覆盖面,并定制编解码器性能以优化游戏。腾讯目前支持 13个 生产级别的游戏,包括动作冒险、第一人称射击游戏和实时战略游戏。为了优化网络延迟,使用多接入边缘计算来加速服务: 用户被划分为数十个地理直径数百公里的操作区域。云游戏服务器部署在每个操作区域的集群上,平均往返网络延迟为 15 毫秒(附录 B.2)。
在客户端实现了帧率自适应算法。AFR 控制器连续测量解码器队列的统计信息,并根据需要向边缘服务器发送请求以调整帧率。然后,边缘服务器将帧率调整请求转发给视频编码器和游戏应用程序。新帧将在 新帧间隔(inter-frame) 后生成。我们在6.4 中评估了视频编码器和游戏应用程序的响应及时性和开销。
6.评估
我们从以下几个方面对 AFR 控制器进行评估:
- 延迟提升。我们提出了性能改进: 与现有的基线(6.1)相比,具有长排队时延和 AFR 总时延的帧比分别提高了 2.1x-26x 和 13%-2.2x。
- 帧率。然后我们证明 AFR 对帧率相关指标(6.2)的影响可以忽略不计。
- 参数敏感度。我们的评估表明,AFR 中的参数具有广泛的设置范围,以获得相对于微调基线(6.3)的性能改进。
- 微观基准测试。我们进一步证明了帧率调整的及时性、开销和图像质量对于在线部署是令人满意的(6.4)。
- 在实际系统中部署。最后,我们报告了在线云游戏服务的 A/B 测试结果和 AFR 部署进度(6.5)。
6.1 延迟提升
我们比较了排队延迟和总延迟的每一帧与 AFR 和基线算法在四个 trace 集(表1)。我们在两个维度上测量排队延迟: 我们在图 12 中给出了第 99 个百分点的排队延迟和排队延迟 > 50ms 的帧之比。我们首先分析了 AFR 针对三种现有机制(DropTail,Qlen-S 和 Qwait-S)的结果。在三个基线上,AFR 可以将 99% 的排队延迟减少 1.9 × 到 7.4 × ,在不同的 traces 上严重排队帧的比例减少2.1 × 到26 ×。在这种情况下,99% 的队列延迟可以被压缩到 6.9 ms。这表明 AFR 可以有效地实现超短排队延迟。AFR 在总体端到端延迟方面也表现出令人满意的性能改善,这与用户的体验直接相关。AFR 使 99% 的总延迟性能提高了 27% 到 36% ,严重延迟帧(总延迟 > 100ms)的比率指标提高了1.6 × 到2.2 × 。我们还测量每个会话的卡顿率,即一个会话中总延迟大于 100ms 的帧的比率。然后,我们测量会话卡顿率 > 5% 和 > 10% 的会话比率,这表明有多少用户遭受不满意的体验,并在图14中显示结果。
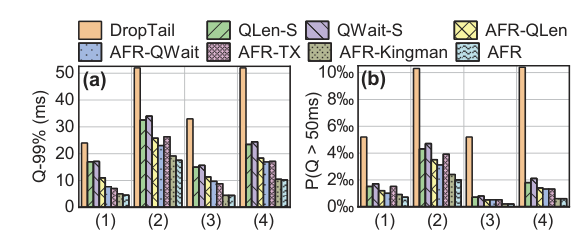
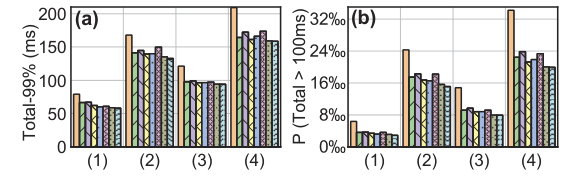
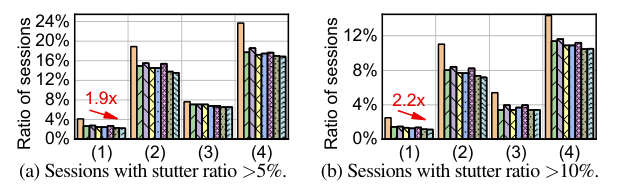
在我们服务的主要人群中(表1) ,相比最好的三个基线结果,AFR 减少了 17% 和 21% 的会话卡顿率。对比其他方法,会话卡顿率也减少了 5% 到 37%。AFR 可以显著提高高质量 RTC 的用户体验。
通过比较 AFR 的不同变体,我们进一步了解了性能改进。与 DropTail 相比,基于队列状态的基线(AFR-QLen,AFR-Qwait)能够有效地降低队列延迟,说明了主动控制队列延迟的必要性(3.1)。与 QLen-S 和 Qwait-S 相比,控制帧率比从编码器跳帧获得更好的性能。这是因为跳过帧会大大降低尾部帧率,为此基线参数被调整(6.3)。AFR-TX 可以比基于队列状态的基线更进一步地减少排队延迟,表明观察服务过程可以提前知道潜在的退化并有效地采取行动,验证了我们在3.3中的分析。AFR-Kingman 算法对 AFR-TX 算法的性能进一步提高了10% ,表明高质量 RTC 的波动到达也会影响解码器队列的估计。对于 AFR-Kingman 算法,AFR 最终减少了2-4% 的尾部排队延迟,说明了临时控制器处理突发事件的必要性。
此外,我们还发现,当网络质量较好时,AFR 具有较大的性能改善。两组以太网 traces 的性能改进(分别为 55% 和 37% For Cat.(1)和(3)) 大于 WiFi 上的traces (35% 和 27% 的 Cat.(2)和(4).)考虑到正在部署的下一代接入网络具有更好的网络条件(例如,5G 和 WiFi 6) ,控制解码器队列的必要性将更加显著。
6.2 维持帧率
此外,我们还测量了 AFR 对帧率的影响。我们首先测量每帧到达客户端时帧之间的到达时间之差。例如,每秒 60 帧的帧率应该导致大约 16.7 毫秒的到达时间差。我们对每个算法的参数进行调整,以使它们的到达时间差的第99个百分点保持在同一水平(详见6.3)。因此,对于10-90百分位数,如图15(a)所示,除 DropTail 之外的大多数算法性能都是差不多的。相对于现有的部署机制 DropTail,AFR 由于其更好的丢帧管理,甚至提高了尾部用户感知的帧率。AFR 略微降低了中值帧率 3% -9%,考虑到延迟的改善,这给用户带来的体验质量(QoE)降低可以忽略不计。
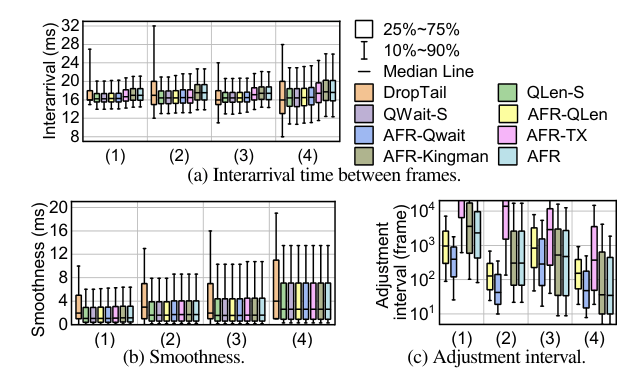
我们进一步测量帧率的平滑性,这也可能对用户的体验有潜在的影响。我们测量到达间隔时间的差异作为帧率平滑性的指标,并在图15(b)中给出了结果。 除 DropTail 外,所有基线和 AFR 都具有相似的到达间差异,优于 DropTail。这主要是因为 DropTail 中的帧丢失会引入到达间差异的突然增加。此外,我们还测量了帧调整间隔,并在图15(c)中给出了分布。AFR 的中值调整间隔为数百到数千帧,远远大于帧率调整的响应时间(6.4)。
6.3 参数敏感度
然后我们评估 AFR 和其他基线参数的灵敏度。我们在 5.2 中调整所有基线的参数: QLen-S 和 Qwait-S 跳过帧的阈值,也对应 AFR-QLen 和 AFR-Qwait,AFR-TX 的 ρ 和 AFR-Kingman 和 AFR 的 W0。我们展示了排队延迟 > 50ms (P (Q > 50ms))的帧的比率和在 Cat(1) traces 上的第99个百分点的到达时间间隔。左下角表明该算法在队列延迟和帧率之间取得了令人满意的平衡。
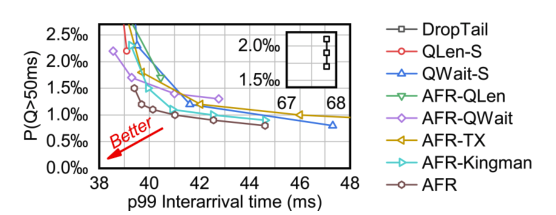
正如我们所看到的,AFR 优于所有其他基线的设置,实现了更好的排队延迟与帧率的权衡。基于 Q-Len 的算法在实现超短队列延迟方面面临挑战: 在极端参数(只要队列长度为非零就跳帧或降低队列长度)下,QLen-S 和 AFR-QLen 只能达到2.2‰和1.7‰的 P (Q > 50ms) ,远高于其他基线。这是根据我们在3.3中的分析得出的结论,即队列长度作为信号太粗粒度,无法用超短目标控制队列。与基于帧率的算法相比,基于跳跃的算法可以获得更低的队列延迟,但是具有更高的到达时间差。所有算法的参数都按照图 16 调整,方法是对齐第 99 个百分点的到达间隔时间。
我们在附录 D.3 中还评估了不同百分位数的排队延迟和总延迟是如何被 W0 的设置所影响的。AFR 的性能对 W0 的设置有敏感的反应,表明算法可以通过调整 W0 可以有效地平衡总延迟和帧率。我们也在附录 D.3 中进一步评估了转换控制器中 EWMA 和 EWMV 的折扣因子 ξ 的灵敏度,展示了操作者该如何设置这些参数去平衡精确度和敏感度。
6.4 微观基准测试
我们还在我们的云游戏服务的测试平台上对 AFR 进行了基准测试。
帧速率调整的有效性。我们首先在视频编码器上测量帧率调整的响应度和精度。我们列举了{25,30,… ,60} fps 内的所有帧率切换,并测量编码器需要采取多少帧才能在新的帧率下稳定地输出视频流。以帧为量度的响应时间(响应帧)见图17(a)。对于每组设置,我们重复实验100次,以消除随机性。当帧率降低时,90% 的响应帧小于 3 帧,说明编码器和游戏应用可以及时地降低帧率。这样可以有效地减轻解码器队列的过载。当显著增加帧率时,帧率可能会稍稍延迟以改变。这是因为客户端的帧率遵循 bucket 效应。无论是编码器还是游戏应用程序降低帧率将导致最终帧率的下降,而帧率的增加需要从两个组件增加。即便如此,尾部响应帧小于 10 帧,这比调整间隔小得多(图15(c))。
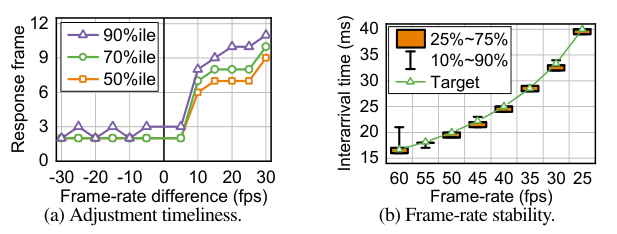
然后测量流式编码器输出帧率的波动。我们将帧率设置为上述几个级别,并测量每个帧之间的到达时间差。对于每个帧率,我们测量 30,000 个帧之间的到达时间差,并在图 17(b) 中显示分布。帧之间的间隔时间大部分落在目标帧率附近。因此,不同于视频流中波动的比特率,帧率可以由编码器精确控制。
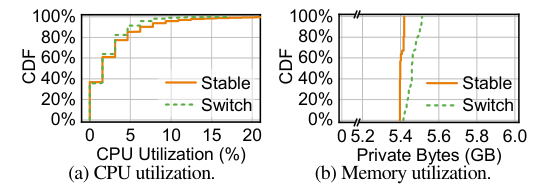
帧率调整开销。我们进一步测量边缘服务器上帧率调整的潜在处理开销。为了放大开销,我们将帧率从 60fps 改为 30fps,每 6 帧改为 60fps,这比通常的调整间隔要短得多。然后,我们通过每 1 秒使用 typeperf 对 CPU 处理时间和应用程序私有字节进行采样来测量云游戏应用程序和编码器的 CPU 和内存利用率。我们测量 30 分钟来消除随机性。在图 18 中,我们将该场景与 60fps (稳定)的稳定帧率和频繁切换的帧率(开关)进行了比较。对于 CPU 利用率,两种情况的分布类似,从0% 到20% 。由于产生较低的帧率需要较少的游戏应用程序 CPU 资源,所以Switch 比稳定帧率稍微好一点。至于内存利用率,主要的内存消耗来自于游戏应用程序。帧率切换略微增加了私有字节的利用率,因为频繁地重置编码器需要分配内存。尽管如此,即使在 99% ile 时,内存利用率的增加也低于1.8% ,这是可以忽略不计的,在正常帧率调整的情况下甚至可能更低。
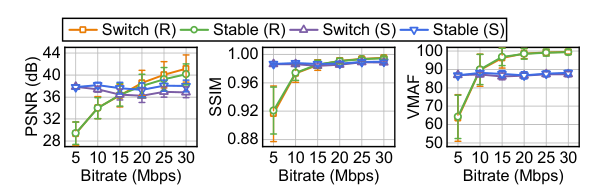
图像质量降低。我们还研究了 AFR 引起的图像质量下降的可能性。我们从游戏中录制两个原始视频,一个在跑步场景(R)中,另一个在站立场景(S)中。对于每个视频,我们每 100 帧切换帧率 15 次,并测量接下来的 400 帧质量。我们研究了三个视频质量指标,峰值信噪比(PSNR),结构相似性指数(SSIM)和视频多方法评估融合(VMAF),并在图 19 中显示了结果。stabel 和 switch 表示帧率保持不变或频繁切换的情况。结果表明,频繁切换帧速率不会影响视频质量: 两个视频在三个指标上的视频质量在所有情况下都是相当的。
6.5 在实际系统中部署
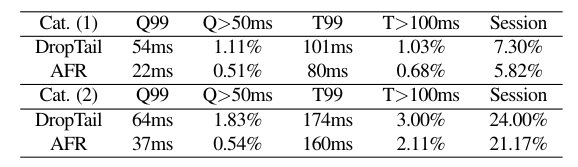
最后,我们通过将 AFR 部署到我们的云游戏服务 Tecent Start 的 Windows 客户端上来评估 AFR 的性能。在部署 AFR 之前,我们的云游戏服务遵循 WebRTC 中的帧控制策略(即 DropTail)。为了进行清晰和可控的比较,当所有其他实现和设置保持不变时,我们只在生产集群中显示在线 A/B 测试的结果。A/B 测试在2021年1月8日至2021年1月14日期间进行,产生5369个以太网会话和1467个 WiFi 会话。AFR 的参数设置与仿真结果(5.2)相同。
我们以每个会话 50% 的概率随机启用(或禁用) AFR,并在表 2 中显示结果。与仿真结果相似,两种类型的总延迟(P(T > 100ms))测量的卡顿帧比分别提高了34% 和30% ,显著改善了用户在交互式流媒体中的体验。卡顿的会话(与图14(a)的衡量标准相同)也平均减少了 17% ,表明这些用户可以从卡顿的流体验中得到缓解。 因此,在线部署还显示了 AFR 对高质量 RTC 用户的显著好处。AFR 已经部署到 Tecent Start 的所有生产集群超过一年,每天为数千用户服务。
7.讨论
在本节中,我们将讨论 AFR 的潜在局限性。
应用场景。在本文中,我们主要评估 AFR 在我们的云游戏服务的跟踪或生产集群上的性能。然而,正如我们在 1 和 2 中介绍的,解码器队列过载通常存在于许多高质量的 RTC 场景中,如 VR 流或4K 直播流,只要它们将高帧率和高比特率视频流传输到商业客户端。我们评估 AFR 与云游戏,由于现实世界的 traces 和生产服务 X。我们将 AFR 的部署放在其他场景上作为我们未来的工作。
多个控制回路的共存。在 RTC 系统中还有其他同时工作的控制回路。例如,底层的拥塞控制器还将根据网络条件控制视频的比特率。视频编解码器还将根据场景调整量化参数进行编码。正如我们在3.2中所讨论的,这些参数受到不同原因(拥塞控制、解码器退化、场景变化)的影响,它们彼此正交。 因此,在 RTC 系统中,帧率的自适应与其他控制器是正交的。在 6.5 中,我们用所有这些控制器在实际生产中对 AFR 的性能进行了评估。我们将不同控制器之间的协调留给未来用户体验的联合优化。
8.总结
本文提出了通过动态调整帧率来降低高质量 RTC 解码器队列延迟的 AFR 算法。AFR 引入一个平稳控制器和一个暂态控制器来分别缓解平稳的繁忙业务和偶然到达的服务。我们进一步通过 traces 驱动的模拟和生产集群中的部署来评估 AFR 的性能。实验表明,AFR 可以显著降低卡顿率和尾部总延迟。这项工作没有引起任何伦理问题。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。