
随着线上互动需求的增加,直播连麦、语音/视频聊天的应用越来越广泛。我们一直在说“追求用户的极致体验”,但是体验是一个抽象的概念,很难量化和统计。如何从用户的行为中得到所在场景的优化“极值”,如何依据“极值”建立统一的质量指标体系以指导业务优化?如何迁移抖音的服务经验,满足toB用户的体验需求?LiveVideoStackCon 2022北京站邀请到火山引擎RTC团队负责人——杨智超,为大家介绍在实时通信场景下火山引擎RTC对体验的理解与应用落地。
文/杨智超
编辑/LiveVideoStack
原文:https://mp.weixin.qq.com/s/fhMD00IpfGeJugz2-8Q2Yw
大家好,本次和大家分享的题目是RTC体验优化的“极值”度量与应用,重点在于“极值”二字,因为RTC很多时候很难定义体验天花板,如何通过数据手段定义天花板并指导团队进行极致体验优化?
我是杨智超,火山引擎RTC体验团队的负责人。

本次分享包括以下方面:
一、RTC指标体系及目标;
二、直接指标的“极值”探索-以进房为例、间接指标的“极值”探索-以卡顿为例、“异常特征库”指标:这三类指标在日常的使用和分析过程中的思路不同;
三、体验优化的能力迁移与最佳实践:用实例说明以上三类指标如何提升用户体验。
-01-RTC指标体系及目标

为什么要花大精力做指标呢?因为很多团队做RTC时在指标体系花的精力并不大,很多是算出来,我刚进字节的前两年管理RTC供应商,他们为我提供了非常多指标,但在过程中遇到了一些事情让我意识到指标的重要性。在一次重大事故中,抖音连麦持续40+分钟无法成功进房,只能直播无法连麦,而进房指标依然99%+,我们对此表示怀疑,供应商提出的理由是一个旁路服务器出现了故障,但这也同时体现出了指标定义的问题。

在日常工作中,即使整体的服务业务没有波动,指标有时也会持续变化,且变化的范围在绝对值20%-30%。直观地看来是服务业务的某一环节出现了问题,但在实际排查后得到的回应往往是没有达到阈值,暂时无需关注。当达到阈值后,又会发现供应商侧的报警形同虚设,也无法排查出原因,此时得到的建议是再观察两天,而最终结果要么是过两天指标自动恢复正常,要么是持续处于高位,供应商便会问我们的用户体验反馈有何变化,如果没有变化,那就直接调整较高的阈值后继续观察。

在多次发生此类事件后,我们便开始自己做指标。经过两年的沉淀后,指标体系也变得“稳、准、狠”。
- 稳——极小波动,月初14日的核心指标的方差<0.003,选取月初14天的原因是国内套餐在月初14天的网络波动较小。非核心指标包括进房、80ms音频卡顿及500ms视频卡顿的方差基本在万分级的水平波动。
- 准——波动即有因,在出现问题时要找准大致方向排查原因,在进行了大量的归因分析后,我们定下了归因比例>95%的目标,只有达到此水平,才能看出指标的整体波动趋势,有章可循,反之没有分析出原因的波动是无意义的。核心指标的归因比例如进房达到98.23%、80ms音频卡顿是94.92%,这个比较低,因为小的卡顿没有必要归因,500ms视频卡顿是97.36%。
- 狠——有因必有果,报警的时候必须查明原因,近一个月的报警次数是41次,近一年能查出确切原因的比例是92.7%。
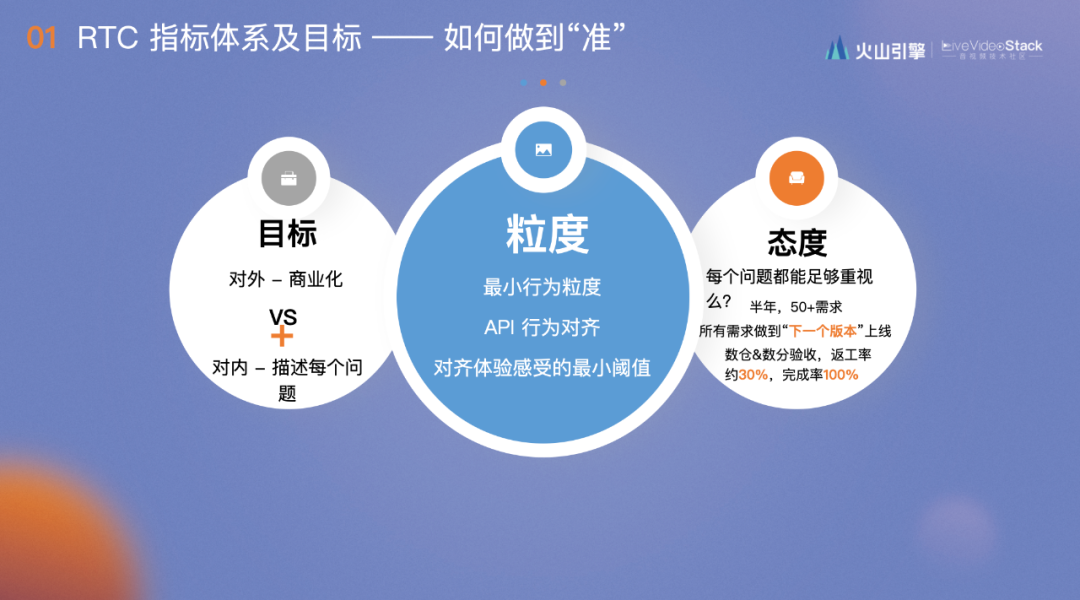
指标做“准”的要求有三个:
- 目标清晰。这是非常关键的一点,对于RTC来说,目标包括相背的两方面:一个是商业化,要求指标尽可能准,波动不大;另一个是敏感,只要出现问题,就要提前出现波动,能够展示每一个case并分析原因。我们调研市场中的其他方案,他们都将其当成两套指标执行,但我们在拉着产品和研发讨论后认为要做成一套指标,将另一套指标的经验放在这套指标的研究上,争取把这套指标研究透彻,向业务方展现更多细节,使其更加信任我们。
- 态度。每个数据的问题是否能在下一版本上线?火山引擎本身非常关注AB实验,大家对数据的需求非常重视,这点做的非常好。
- 落到实地。我总结要将指标做准的三个词,最小行为粒度、API行为对齐、对其体验感受的最小阈值。

在会议场景中,从进房到发言、Mute自己、Unmute自己,再到发言,其中包含了两次首帧发送,每次首帧发送都是一个样本,这一点在指标定义中非常重要,要找到最小行为粒度并将其定义为最小的指标粒度。
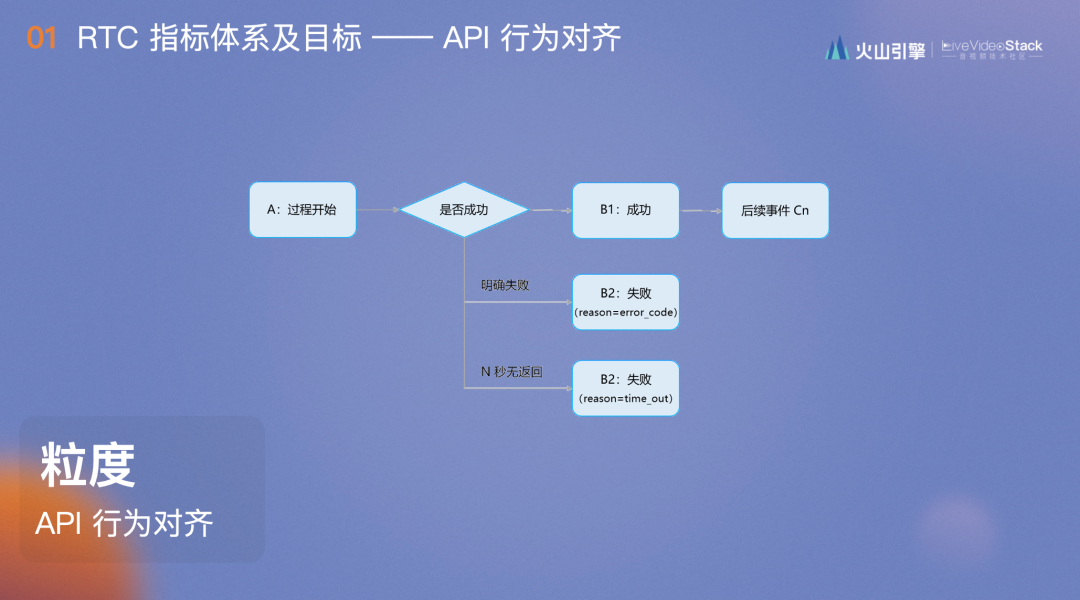
这是典型的成功率指标的计算模型,从过程开始到成功/失败/超时,成功后还有其他事件。但计算指标的时候只会选取B事件或者A/B1事件,如果不考虑所有的ABC三类事件,指标很容易随着日志上报量的波动而波动,考虑所有ABC事件是和用户调用API行为完全对齐的,不会出现用户已经无法进房,而指标仍然99%的情况。

RTC指标中有许多阈值,最简单的是音频卡顿率阈值,业内音频卡顿率一般是80ms、100ms、200ms,我们定指标的时候如何判断阈值呢?RTC主要使用Opus编码器,编码器出现卡顿时会有补偿,当补偿到4帧时,它会把声音分为清音、谐音和噪音进行编码,谐波的衰减系数已经降到0.48,一般衰减系数降至0.5以下,其实已经完全听不清了。所以最多补齐4帧,也就是80ms,正常人说话发一个音节的声音也是80ms,可以理解为,当发“和/he”的音时,如果“h音”出现了卡顿,那么对面听到的就是“额/e”,如果大于80ms,声音已经发生了偏移,不是原来的声音,这是无法接受的,所以我们在定义指标的时候针对此原则确定最小阈值。
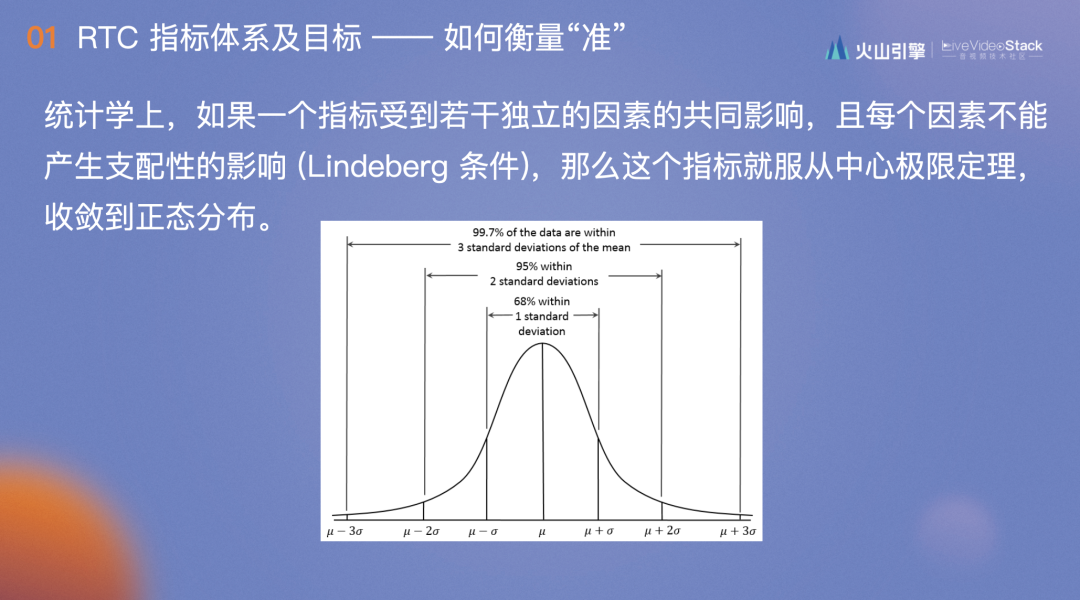
做出指标体系后,如何对其进行打磨?这个过程持续了大概两年,原理是当一个指标非常稳定的时候,它是符合正态分布的,也就是3倍标准差范围的概率是99.7%,也就是说一旦超过了3倍标准差的范围,那么会有99.7%的可能性出现了问题。
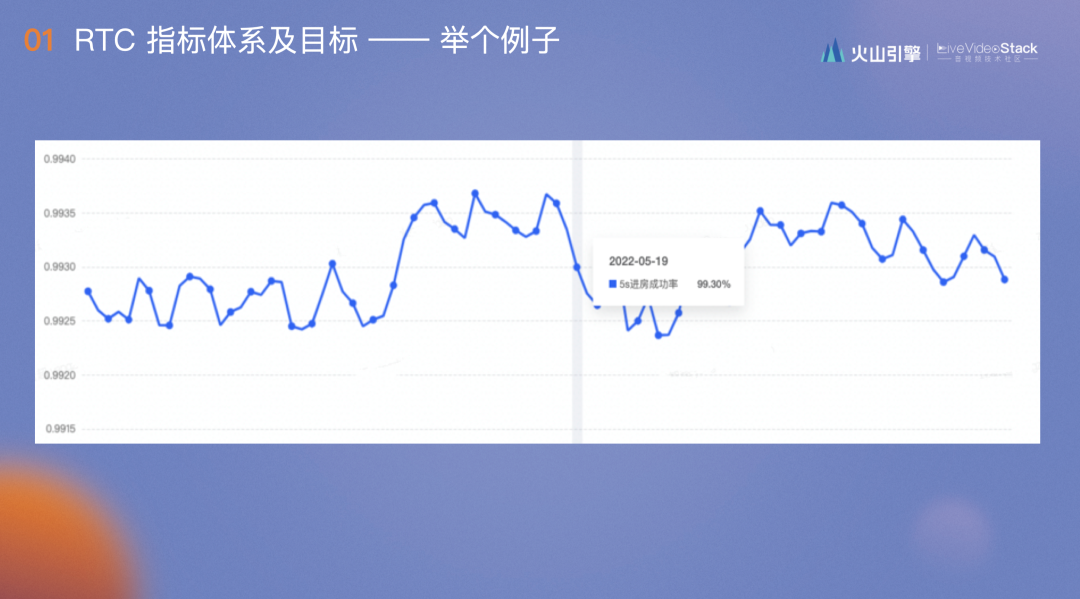

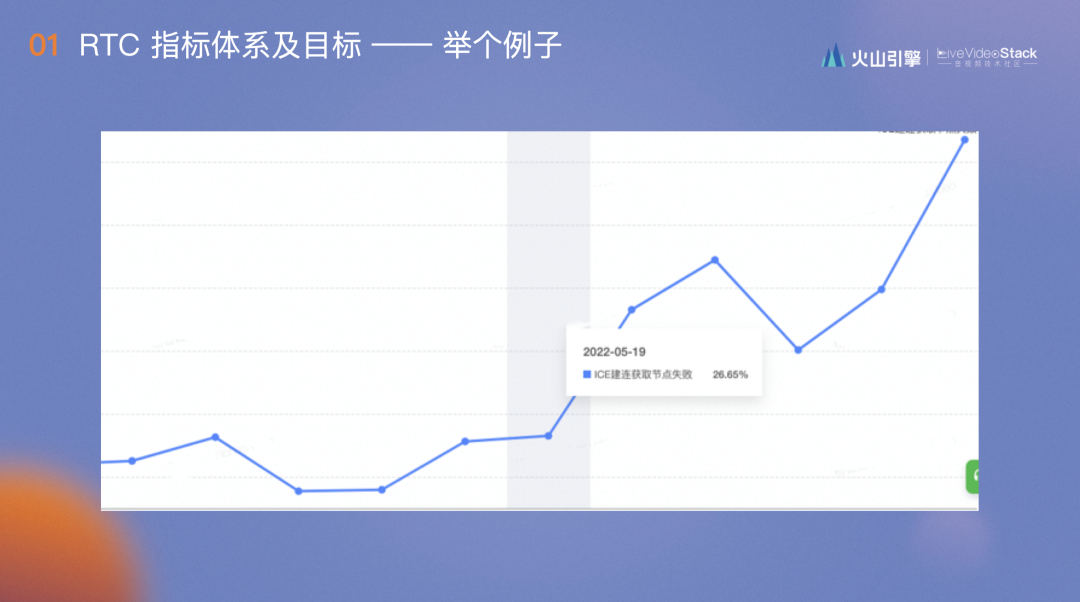
去年5月19日,我们的5s进房成功率变为99.3%,拉长看好像没什么问题,但将其单抽出来,可以看到前14天的平均值是99.342%,标准差是0.013%,监控阈值判定是99.303%,也就是99.3%的实际值中有超过99.7%的可能性是线上出现了问题,根据当时的归因,5月19日的ICE建联获取节点失败也在上涨。我们由此牵引开始排查,发现服务器上线了一个概率非常小的bug,有一定的可能拒绝连接,影响进房成功率不到0.01%。这正是因为指标非常准确,及时发现问题,才能够避免它在线上一直存在且随时可能爆发。

指标体系分为三类:直接指标、间接指标和异常特征库指标。
直接指标包括进房类、首帧类、Crash等,间接指标包括卡顿类、延迟类、CPU、内存等,两者是0和1的关系,对单个语音用户来说,进房要么成功要么失败。而间接指标如卡顿可以是50ms、100ms等,是一种程度的关系。
异常特征库指标解决的是QoS指标无法覆盖的无声问题、噪音问题、回声问题等。
本文分别通过举例具体介绍这三类指标。
-02-直接指标的“极值”探索——以进房为例
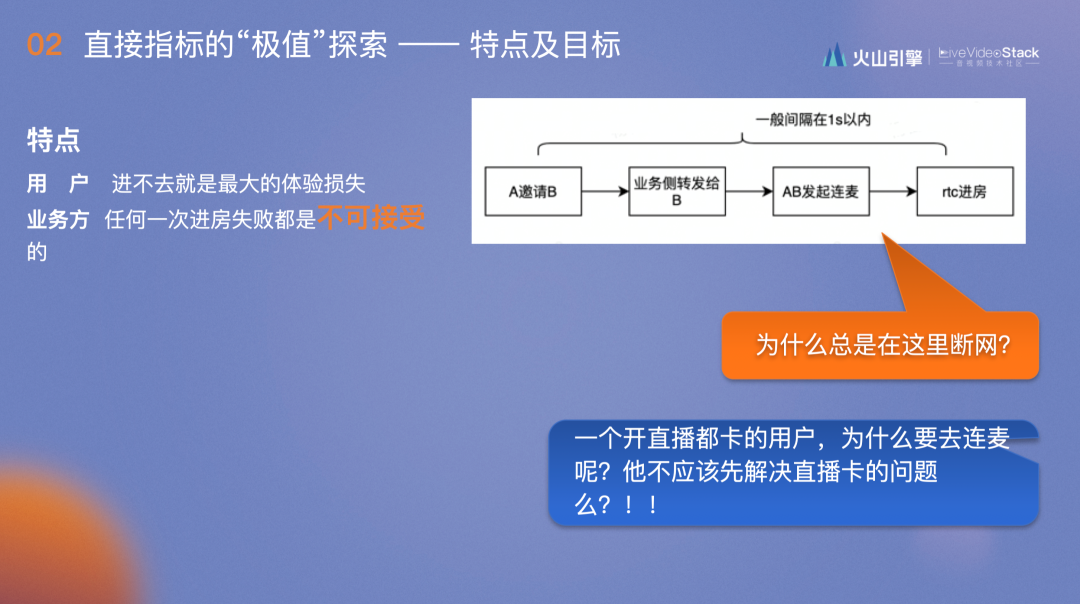

进房类指标对用户来说进不去房是最大的的体验损失,最初对接抖音的时候,对方提出的要求是任何一次进房失败都是不可接受的,而当时我们的结论是,这样的要求也是不可接受的,甚至认为这是不可能的,于是我们理直气壮地和业务方PK。
PK的结果是抖音给我们看了连麦的流程图:用户A邀请用户B后,业务侧转发给B,AB一起进房开始连麦。然后抖音提出两个问题,第一,如果说断网是由于网络不好,那为什么前面的业务请求都是好的,却总是在你这里断网?第二,一个开直播都卡的用户,为什么要去连麦呢?他不应该先解决直播卡的问题吗?
我们认为业务侧视角的解读很有道理,于是定了一个目标,实现进房成功率100%。


经过分析,我们认为要扎扎实实做好拆解与归因,典型的例子便是“ICE建联失败不等于网络不好”。在之前排查case的时候,大部分建联失败的原因会归结于网络不好,但业务方并不认可这个结果,他们认为是业务内部的bug导致失败。
后来我们内部明确了一个观念,分析指标的时候,拆解和归因完全是两件事情,ICE建联失败只能说是一个步骤的失败,并不能说是这次失败的原因。第一步要明确拆解的步骤,在做进行具体归因的时候需要达到“技术认可,业务理解”的标准,如果业务不理解,只能说是技术的“自嗨”,如果技术认可,业务理解,那么便可以达成共识并为此100%努力。
关于上文业务方提到的网络问题,后续的解决方法是我们在进房的同时会发出标准http请求,标准到完全和业务方对齐,覆盖全球30+域名,每次请求至少选中3个域名,当这些请求失败时,我们认为业务网络不通是由用户网络不通所导致,这次的归因也得到了业务方的认可。相应地便有了第二条归因:http成功但ICE建联失败,这是技术和业务都认可的,是技术内部的bug,需要继续优化,这是因为ICE建联本身应该比http更易成功。
此外还有一些归因:在欧洲比较常见的,用户只支持ipV6导致的失败;用户调用的时候有bug,导致在进房的同时出现crash;域名质量不佳等。

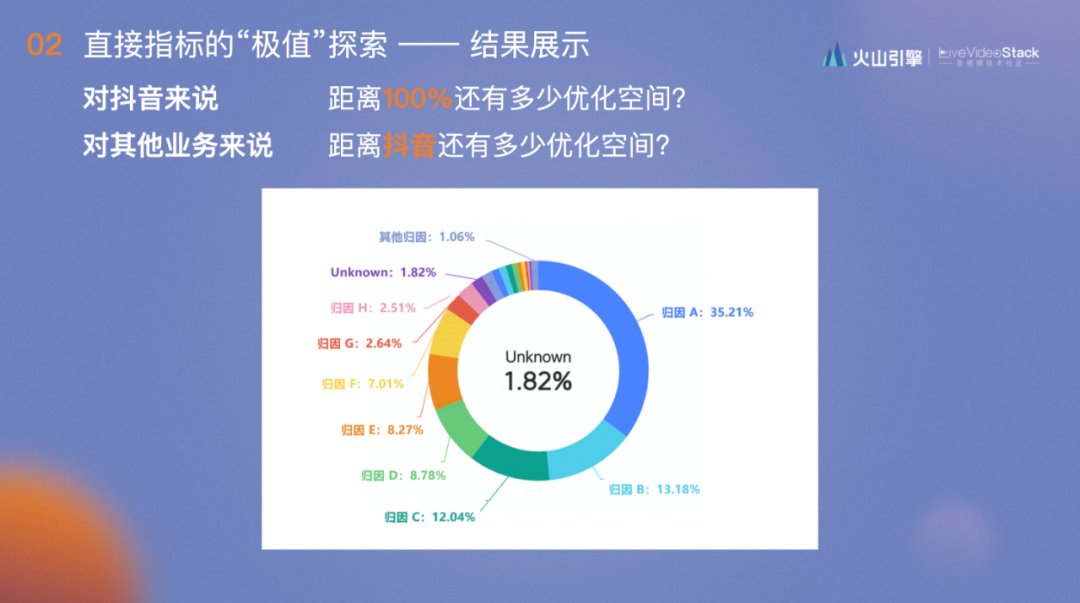
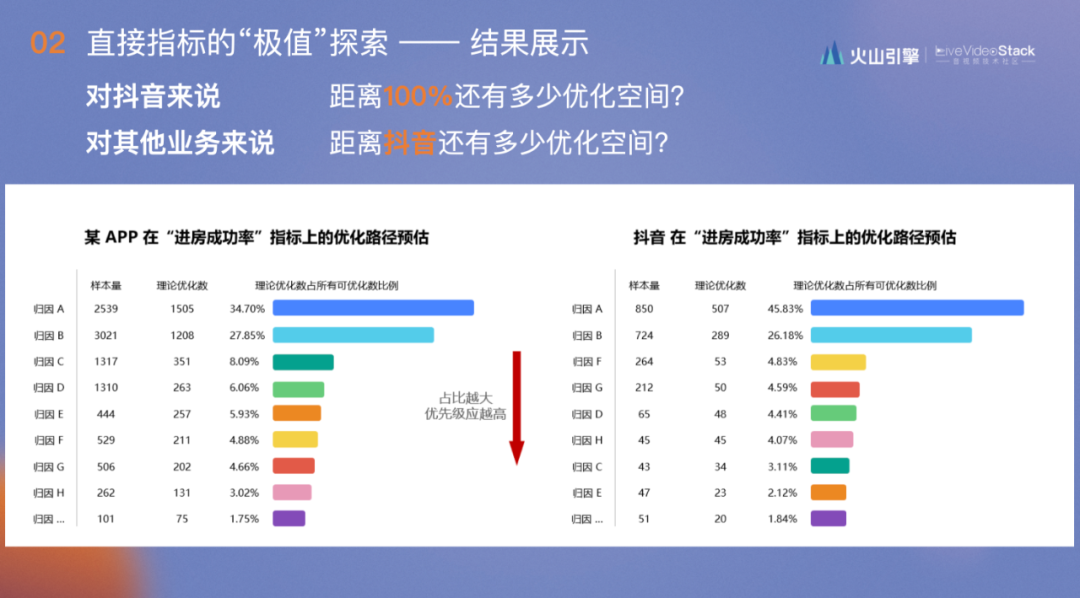
每个归因会在具体计算理论的优化数后,结合核算出的指标同抖音进行对比就可以得出此业务和抖音优化空间的区别,同时可以得到优化天花板是多少。
-03-间接指标的“极值”探索——以卡顿为例

间接指标对于单个用户及不同场景来说标准各不相同,比如主播PK和语音聊天室对卡顿的忍受程度完全不同,前者主要为了提升人气,一旦和主播连麦的时候,对方出现了卡顿,他很可能会结束连麦,换下一个人PK,但后者更注重聊天室积累,主播可以和观众聊一整天,不会轻易的换房间。再细分到语音聊天室会发现主播和嘉宾对卡顿的容忍度也不同,主播为了保证直播间热度,出现卡顿的时候不会轻易离开,但嘉宾可能会直接更换聊天室。
对此,我们制定了一个目标,找到一种能够尽可能适应多场景的衡量用户不爽的方法。
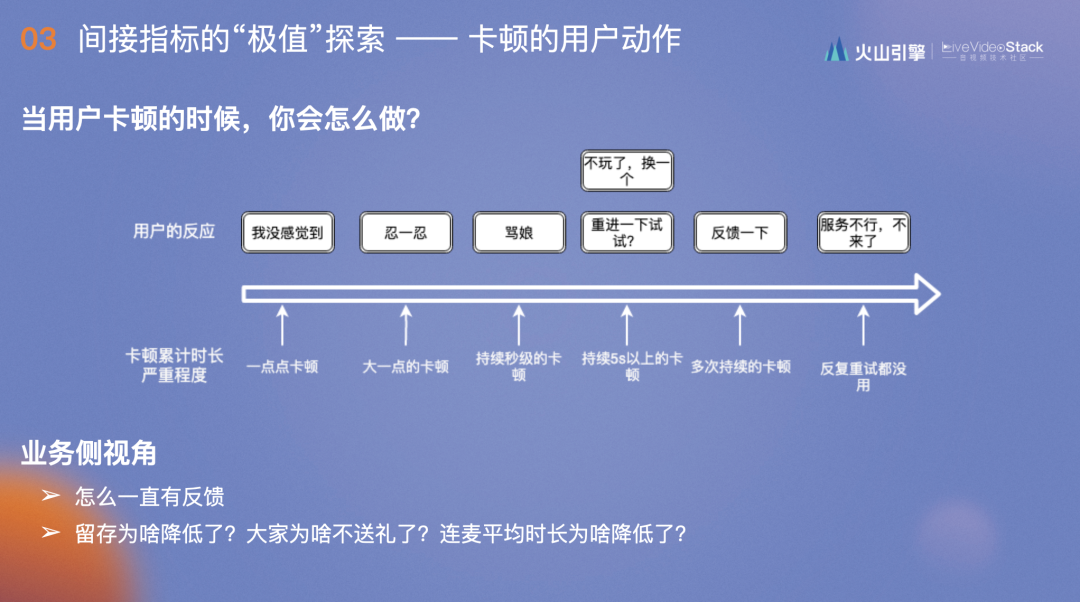
上图是站在用户的角度,根据不同的卡顿累计时长及严重程度,用户做出的不同反应:
- 一点点卡顿如100ms时,用户无法感受到;
- 卡顿大一点在500-700ms时,用户会忍一忍;
- 持续秒级的卡顿时,用户虽然发牢骚,但还会坚持看;
- 卡顿达到5s以上,大部分用户会选择退出重进或直接结束;
- 多次持续的卡顿时,用户会试着进行反馈;
- 当反复重试都没用时,用户会认为该服务不行,不再使用。
而业务侧视角则是一直有反馈,此起彼伏,且留存及连麦平均时长降低。连麦平均时长可以作为重要的和QoS打通的QoE指标,原因是当一次连麦不爽的时候会再连一次,一段时间内连麦次数多了,相应的平均连麦时长自然会降低,业务的指标就会向下走。
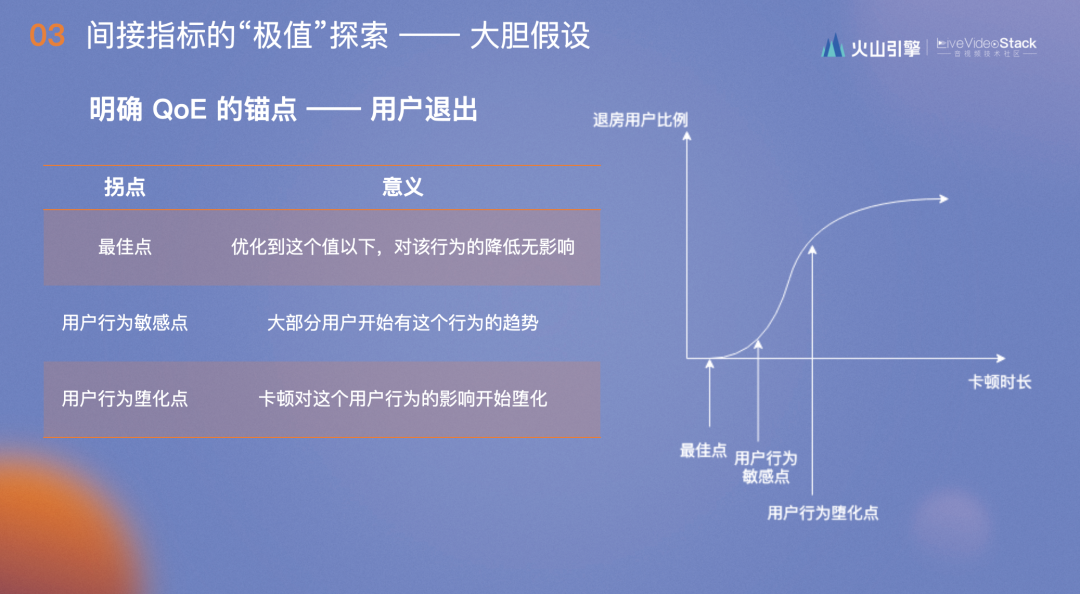
在上文的反应链下,我们大胆假设,首先明确什么是QoE?我们唯一能够控制并能用自己的锚点能够表述的就是“用户退出”动作。
卡顿时长逐渐增长时,退出的比例如下图所示,刚开始用户感知不到,退房用户比例很低,而随着卡顿时长增长到某一点时,大部分用户便开始退房,斜率会增大到极值。达到此点后,会发现有些用户对卡顿无感,他们由于一些固定的原因而必须连麦,比如参加早会,早会的内容如何不重要,重要的是参加,此时卡顿再严重,用户也不会退房。我们发现,不同的场景都会有一定的堕化比例,所以最终选择用户行为的敏感点作为卡顿是否影响用户体验的阈值。
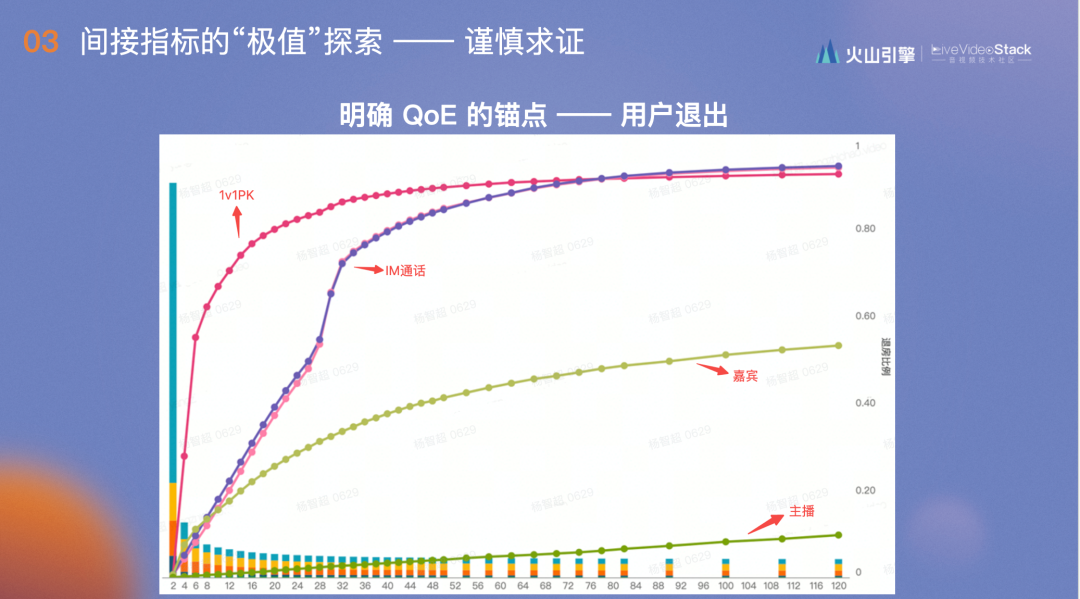
以上是整体的假设,图中是具体到抖音中的数据。
1v1PK对卡顿非常敏感,在2s左右便出现用户大规模退出重连,主播基本没有曲线形状,他对卡顿容受程度非常高,嘉宾的忍受程度介于1v1 PK和主播之间。中间是抖音的IM通话,这里主叫和被叫的曲线完全一致,代表场景完全一致。
这张图最有趣的在于不会随着时间而转移,无论是每个月的第一周,前半年还是后半年,在不同时间段验证,这张图都几乎重叠,完全和用户体验场景和APP对应的用户群体相关。
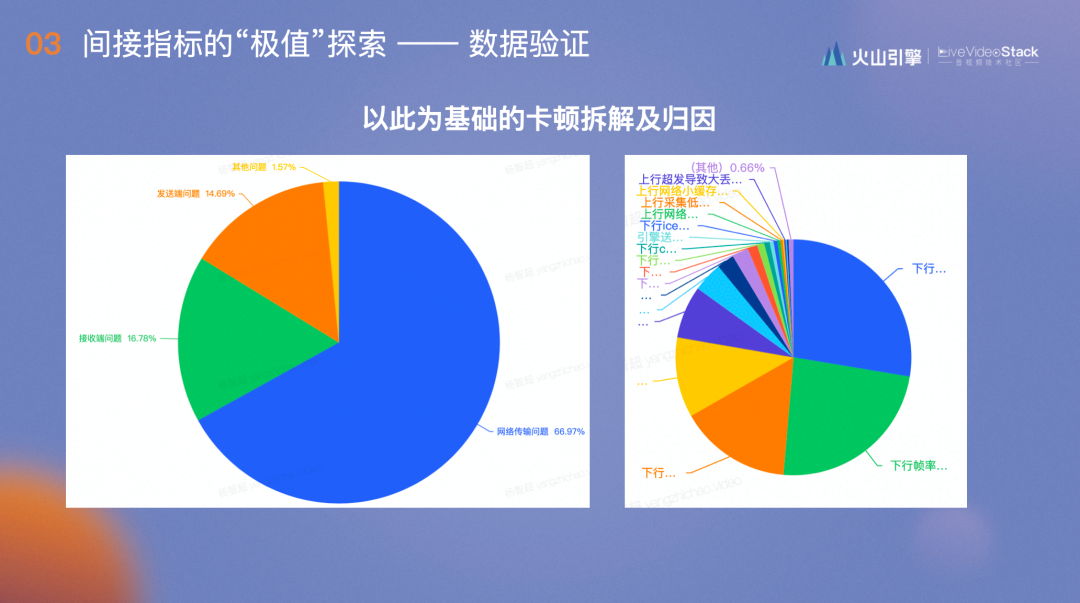
我们在此基础上根据每个图算出敏感点,以此为基础,分析超过敏感点的卡顿原因并做拆解,得到以上两图,并指导用户进行线上优化。这样可以得到更容易引起QoE变化的结果。
-04-“异常特征库”指标



在支持各种业务包括内部创新业务、保密项目及对外的toB业务时发现,业务方对我们用QoS指标做出的东西并不感冒,他们之间存在很大的Gap。C端用户很容易用QoS指标衡量,但B端业务方会受到关键人即老板的影响。我们经常收到一些反馈说又卡了,需要排查原因,于是业务方便认为我们的RTC不过关。还有一种情况是,部分用户会自行反馈或APP自带反馈功能,当我们拿着很好的QoS指标跟业务方沟通汇报时,他们只会质疑,这么多的反馈,你跟我说质量变好了?
一开始我们认为业内都用QoS指标衡量系统质量,怎么在这就和业务方说不通呢?经过分析得出这类case有三个特点:
①很难用指标来衡量,因为每次问题都是随机的;
②我们与业务方都有可能出现问题,也许是业务方调用错了或是调用的时候改变逻辑才导致了问题;
③量小虽然不影响线上指标,但很影响用户体验,对单个用户来说,他发生较大的卡顿并且都开始反馈了,说明在他自己的场景下很容易闭线,这是非常严重的问题。
为了解决此类问题,我们分析了许多类似的case,得出了“用户比老板更早发现问题”的结论,老板发现的问题都在之前的用户反馈中出现过,没有重视的原因是反馈体量较小,数据量波动较大,很难抽取有用的信息,而且对反馈不太关注。于是针对反馈,我们做出了一套异常特征库指标,希望它能够体验用户的评价体系。

能做成这套指标的基础是抖音集团的特点——在意用户反馈,我们公司的食堂屏幕会无删减地播放用户反馈。

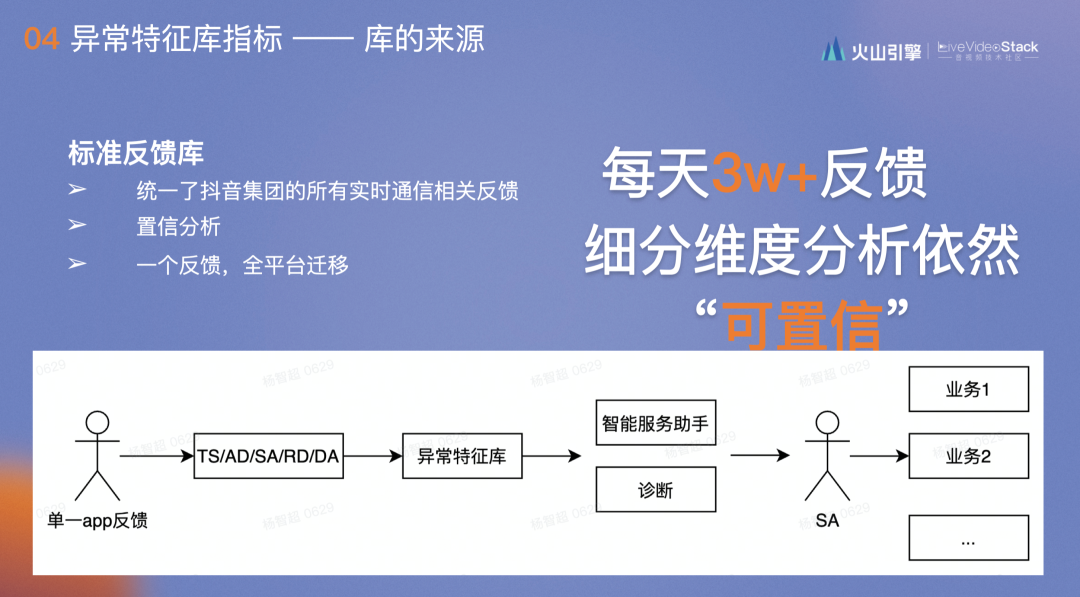

在此之前,我们统一了抖音集团的所有实时通信相关反馈并将其分类。
其次,抖音集团每天线上的反馈多达3W+,都是用户一个字一个字打出来的。我们将其细分维度分析依然很稳定,这对后续分析帮助很大。
我们还设计了一套流程:单个用户做反馈时,会有一波人对其进行分析,再落到异常特征库中,通过两套系统的调用,智能服务助手主动发送给SA,SA能够直接和用户沟通,并根据客户的特点将信息转换为服务落实下去。
这里的关键在于两点:
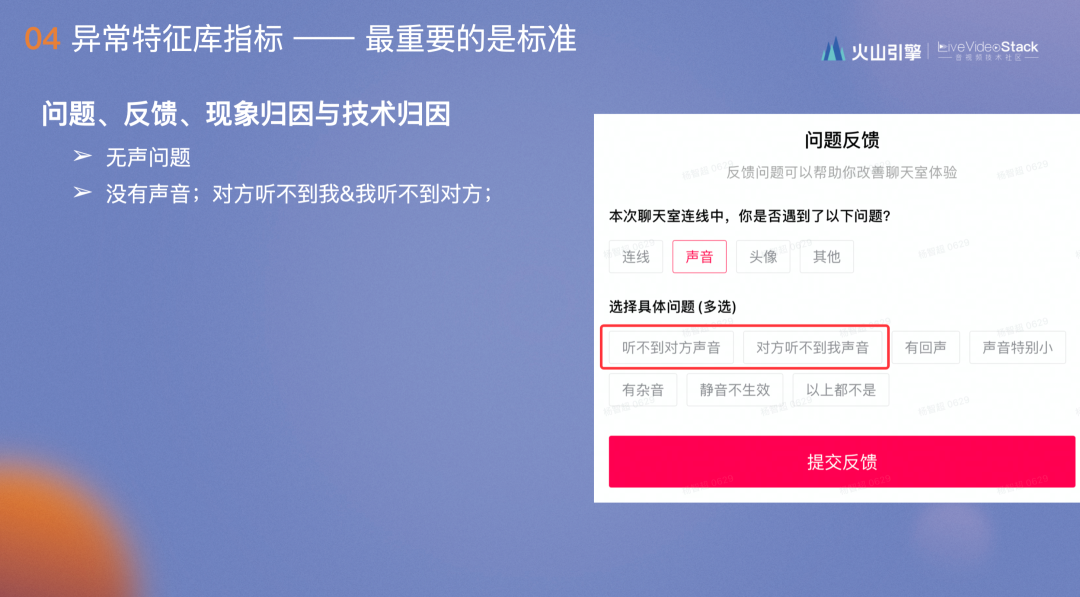
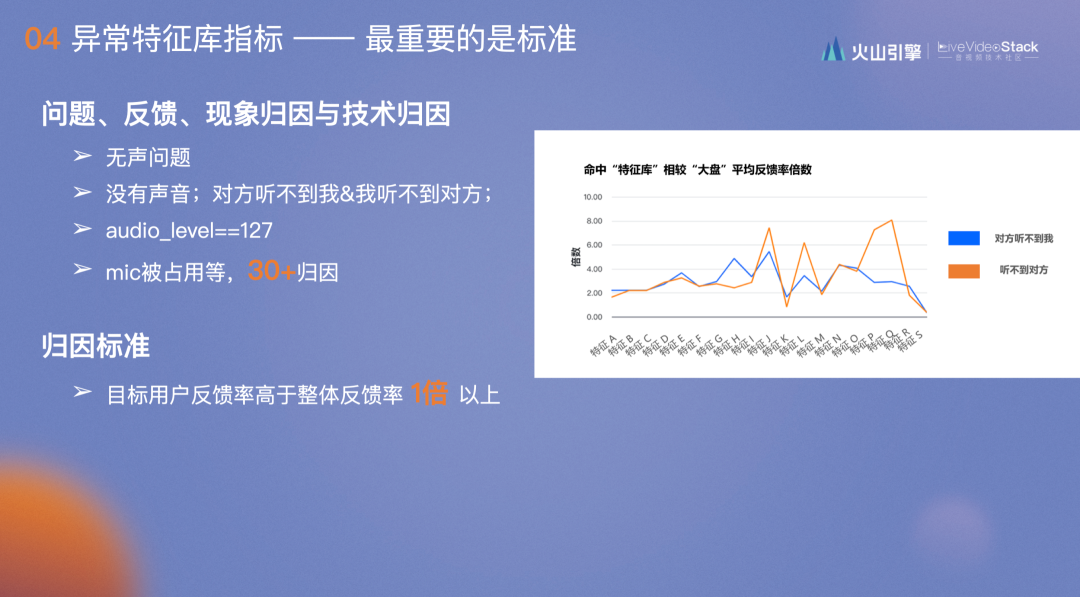
- 第一点是定义概念:“问题”包括无声问题;“反馈”,无声问题对应的反馈包括“我听不到对方”和“对方听不到我”,看上去没有区别,但这两个bug在同一优化上的走势是完全不同的;“现象归因”,比如audio_level==127是无声问题最重要的现象归因,即采集音量为零。对应采集这一现象归因后便是第四点,“技术归因”,如无声问题,光是audio_level==127就有30+个归因。
- 第二点是归因标准,我们之前也将反馈内容抽象出来作为标准规则供大家使用,但存在的问题是标准是否通用或是反馈强相关?对此,我们定了三个强制标准:
- 目标用户反馈率高于整体反馈率1倍以上,右图是实际内容,大部分反馈的归因对应的反馈率是整体反馈率的2倍以上,最高的达到8倍,说明这一特征对应的无声反馈最明显,基本出现这个特征便会出现无声问题。
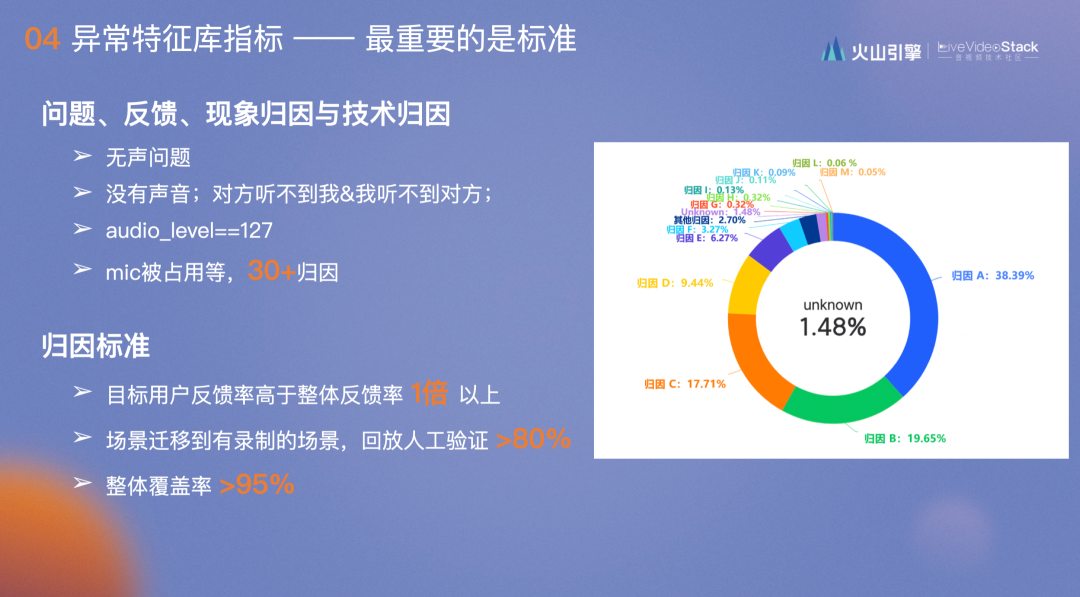
- 迁移到有录制的场景,回放人工验证>80%,由于底层的埋点是通用的,所以在某一场景发现问题后,如在会议场景下很难验证此归因是不是无声的,往往只有看录像才能验证,但会议又不可能保留录像,于是我们把会议规则迁移至有录像的连麦场景下,通过人工验证的方式验证规则是否准确。所有的规则要求验证时准确率>80%。
- 整体覆盖率>95%。前两项标准是为了说明归因的规则和无声的反馈是非常强相关的,而这一项是为了能将以上规则拟合成QoS指标,和QoE反馈的动作强相关。

图中是通过反馈优化发现的问题,如“组合必然无声”体现的是产品兼容性问题,这是代码迭代过程中出现的,当时的无声反馈突然增多,于是在业务方反馈之前便排查并修正了bug。还有一种无声问题是由业务方调用或客户设备所造成,典型的是麦克风被占用。右图是收到了啸叫反馈,许多用户没戴耳机使用电脑开会时,会和会议室的设备产生啸叫,此时系统会主动提示“是否采用无音频模式入会”,由此解决问题。
-05-体验优化的能力迁移与最佳实践



这个是无声的案例,此类情况在抖音其实无时无刻都在发,我们以复盘角度展开:
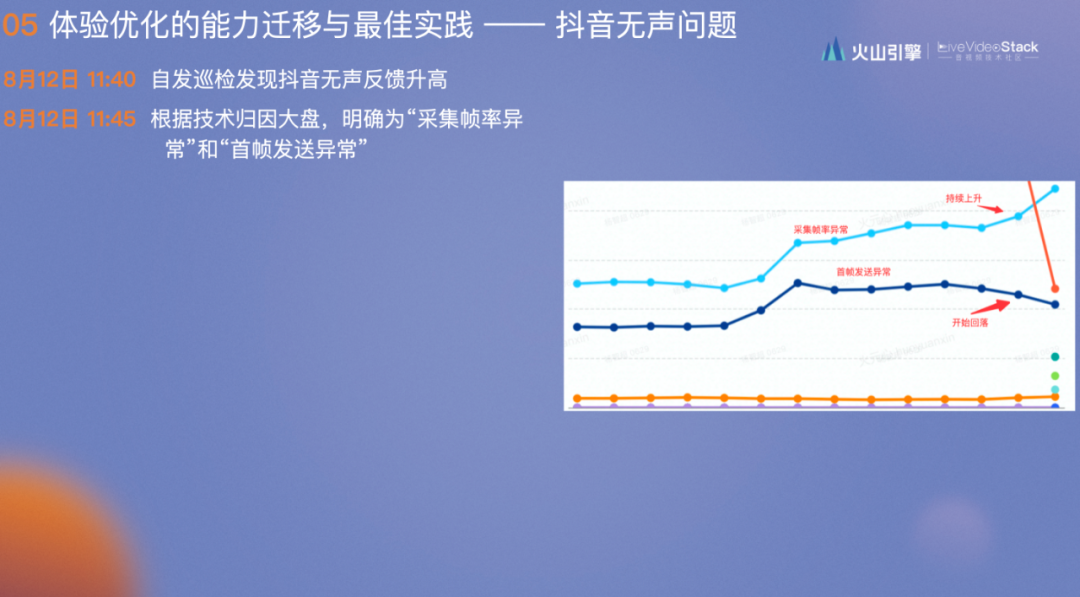
8月12日 11:40 自发巡检发现抖音无声反馈升高
8月12日 11:45 根据技术归因大盘,明确为“采集帧率异常”和“首帧发送异常”,此时前者持续增高,后者开始回落
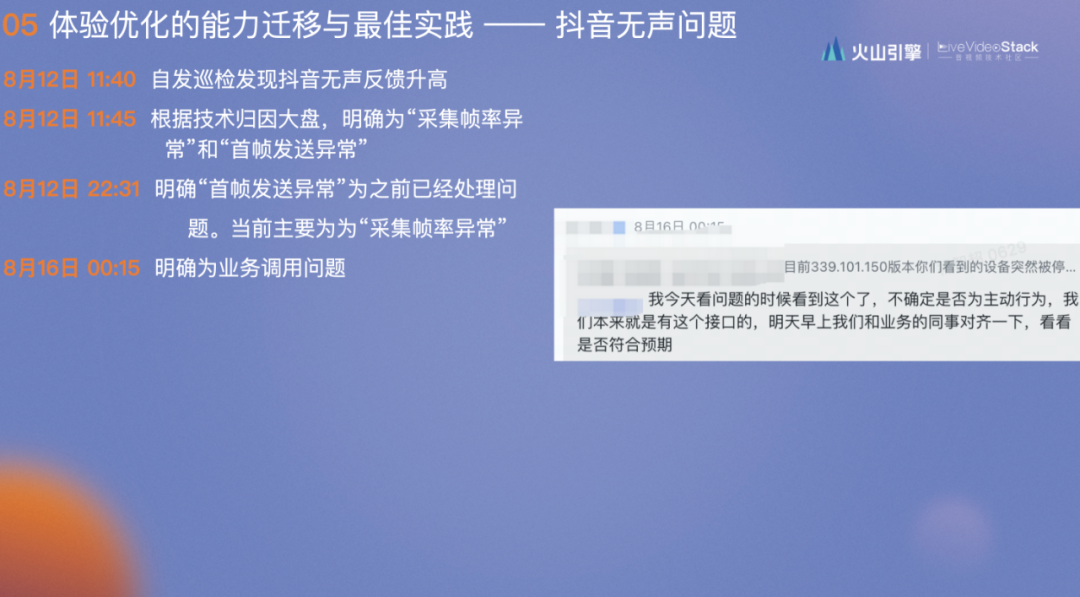
8月12日 22:31 明确为“首帧发送异常”之前已经处理问题。当前主要为“采集帧率异常”(若非进行了细致的分析,此时会得出和供应商相同的结论,“问题已经解决了,再观察两天”)
8月16日 00:15 明确为业务调用问题,RTC没有实际问题
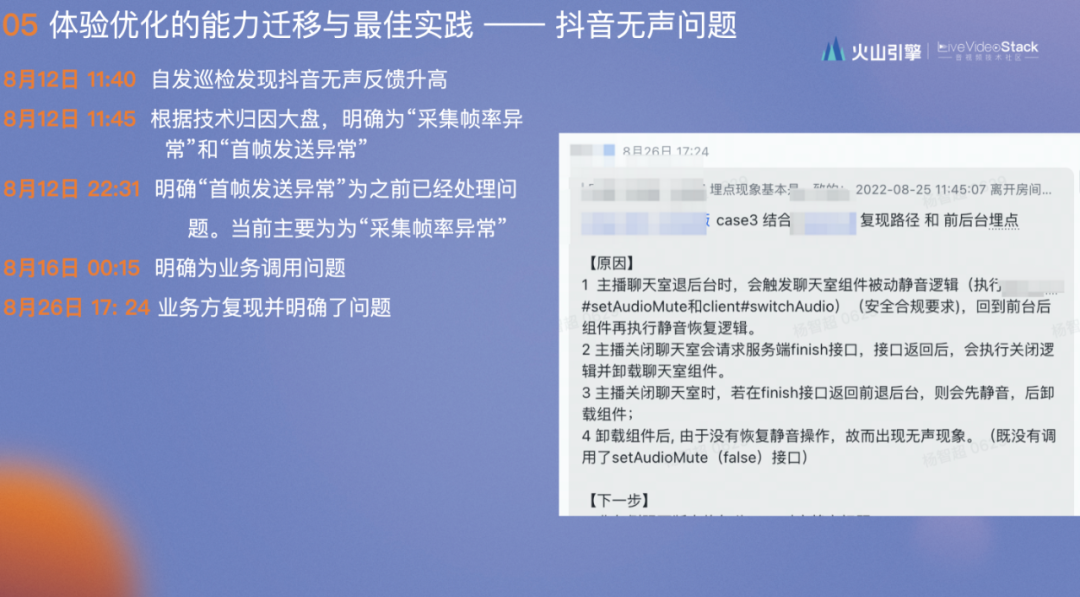
8月26日 17: 24 业务方复现并明确了问题,由于他们调用多线程,导致在接电话时会给客户设置Mute
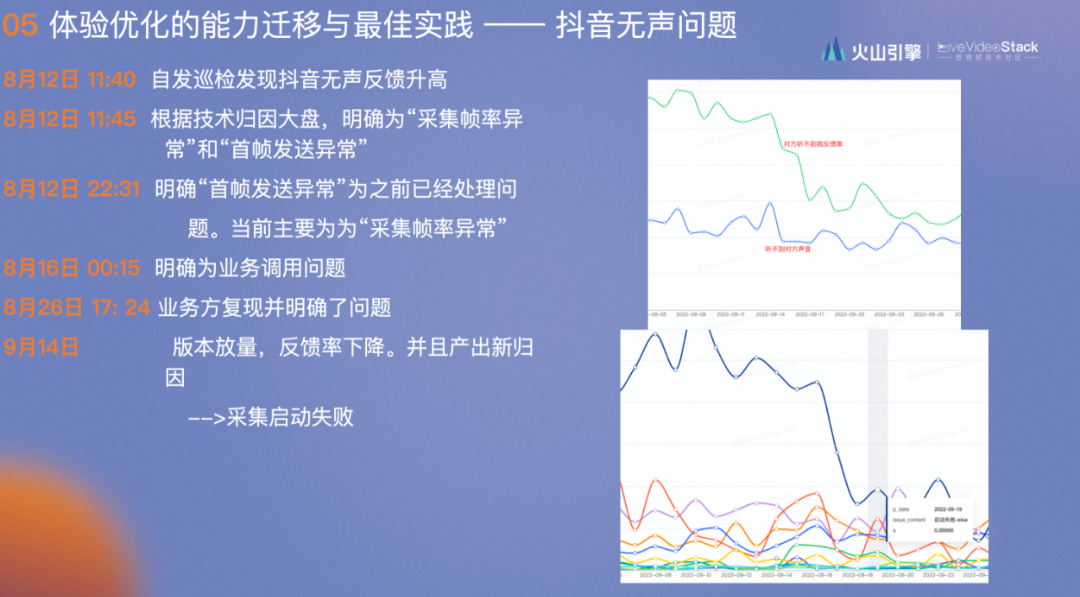
9月14日 bug接触之后,“对方听不到我”的反馈率下降,“我听不到对方”的反馈率无明显变化,并且产出新归因——采集启动失败
10月12日 规则 review 过程中,修订规则为“同一用户连续多次连麦,首次正常,后面无声”,因为“首次正常”代表客户设备没有问题,而“后面无声”代表某一环节出现了问题
11月20日 明确规则后放入特征库,发现某内部创新业务同样存在问题,已经优化上线
整体上,我们便是通过以上方式逐步提升用户体验。以上是本次的分享,谢谢!
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
