
作者:Philipp Hancke
编辑:Chad Hart
特别感谢:Justin Uberti
译自:https://webrtchacks.com/measuring-the-response-latency-of-openais-webrtc-based-real-time-api/
我们一直在深入研究 OpenAI 在 WebRTC 方面的工作。在过去的几个月里,我们对 OpenAI 的实时 API 和 chatgpt 进行了全面的拆解和比较。最让我们感兴趣的是如何测量响应延迟。
任何语音机器人的关键指标之一都是响应延迟——你听到响应的速度有多快。如果该指标不低于某个阈值,即使在恶劣的网络条件下,对话也会感觉不自然。延迟不仅取决于 LLM 生成响应的速度,还取决于将响应发送给用户所需的时间。后者是 WebRTC 的工作。这些因素加在一起就是总响应延迟。我们可以通过从 Chrome 浏览器中提取的原始 RTP 数据包来测量总延迟,具体方法请参见本博文中关于video_replay 工具的介绍。这种方法在黑盒探索中比较不同服务时也非常有效。
在这篇文章中,我们回顾了该方法在 OpenAI 的 WebRTC 实时 API 中的应用,并分析了结果。
注意:此处显示的结果是于 2025 年 1 月 4 日获得的。从那时起,结果有所改善,特别是 STUN 往返时间。
STUN 的往返时间
我们经常使用 Chrome 浏览器的 webrtc-internals 页面进行分析,该页面擅长将 W3C getStats API 的结果可视化。这种可视化提供了有价值的信息,例如目标比特率和发送和接收的字节数,为了解 OpenAI 的 WebRTC API 配置情况提供了更多信息。
在延迟方面,candidate-pair对统计中的 STUN 往返时间显示了数据包从客户端到服务器往返所需的时间,代表了响应延迟的理论下限。


通常情况下,往返时间(RTT)约为 60-70 毫秒(与其他服务相比似乎相对较高),尽管两个小的突起表明可能存在数据包丢失。这可以通过将服务器部署在离用户更近的物理位置来减少(例如使用基于延迟的 DNS,如 Amazons route53)。
RTP 数据包和响应延迟
接下来,我们使用 Wireshark 分析提取的数据包, Wireshark是一种广泛使用的网络分析器,擅长 VoIP/WebRTC 特定任务,例如数据包过滤甚至音频播放。通过检查生成的图表,我们可以准确估计系统的响应延迟。
你可以在此处下载我们提取的 PCAP 。
有一个错误很明显:对方发送的所有音频 RTP 数据包都包含 RTP 标记位。在音频中,该位本质上指示抖动缓冲区刷新。对每个数据包执行此操作完全没有意义,因为它会导致没有缓冲区(这甚至不是 libWebRTC 的行为方式):

Wireshark 的“RTP 播放器”功能(可在电话部分找到)对于收听 Chrome 解密的音频非常有用。我们使用此功能来研究是否可以测量响应时间。
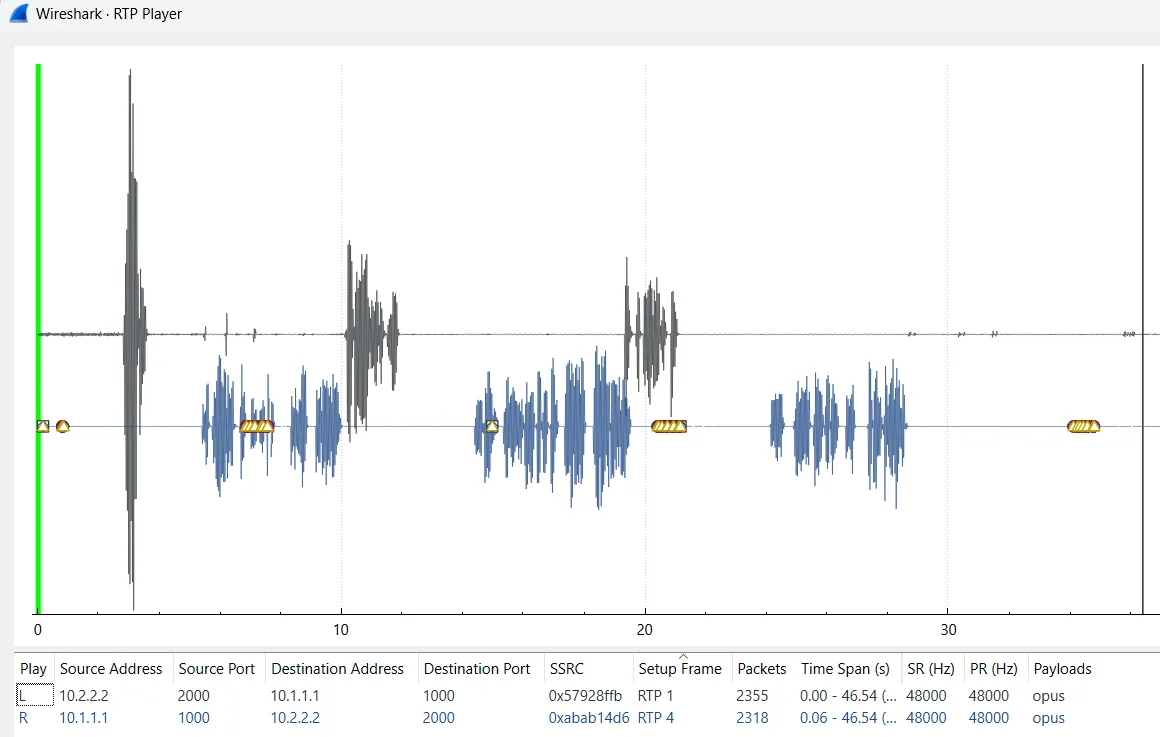
由于非语音数据包的静音内容始终相同,因此确定服务器端的实际语音何时开始相对容易。 确定 Chad 何时停止说话则稍微复杂一些。 我们需要在 Wireshark 中回放数据流,并在波形中选择一个 “silent”点,这样就能找到相应的数据包,如下图所示:
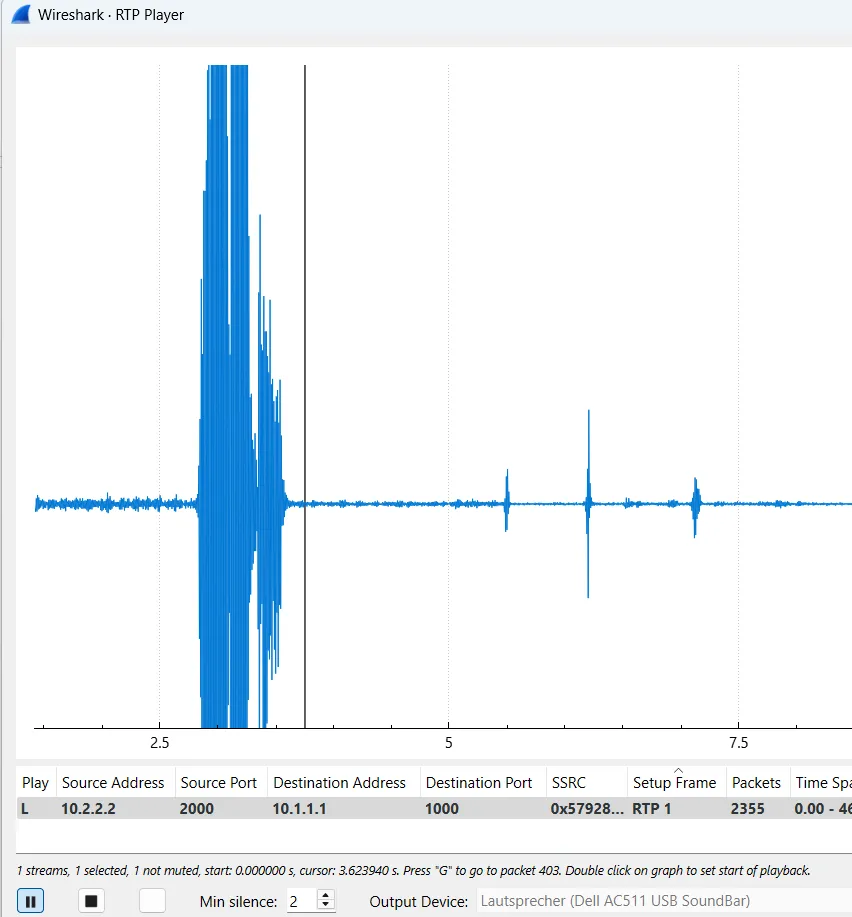
通过标记 Chad 发言的结束时间(屏幕截图中的数据包 403)和模型发言的开始时间,我们可以大致估算出响应时间:
| 语音包结束/时间 | 响应包开始/时间 | 响应延迟 |
| #399,3.58秒 | #591,5.27秒 | 1.68秒 |
| #1335,11.88秒 | #1535,13.67秒 | 1.78秒 |
| #2364,21.10秒 | #2558,22.77秒 | 1.66秒 |
这显然是一个非常有限的样本(并且是一个非常手动的过程),但响应延迟约为 1.7 秒。
通过语音活动检测测量响应延迟
libWebRTC 的 neteq_rtpplay 工具(相当于 video_replay 的音频工具)可以从带有未加密数据的 PCAP 文件中提取 WAV 文件。
out/Default/neteq_rtpplay api-rtp.pcap -ssrc 0x57928ffb chad.wav
out/Default/neteq_rtpplay api-rtp.pcap -ssrc 0xabab14d6 bot.wav这将分别提取呼叫者和被叫者的两个 RTP 流。数据包的开始时间相当接近,为 56 毫秒,正如我们在使用 Wireshark 的 PCAP 中看到的那样:
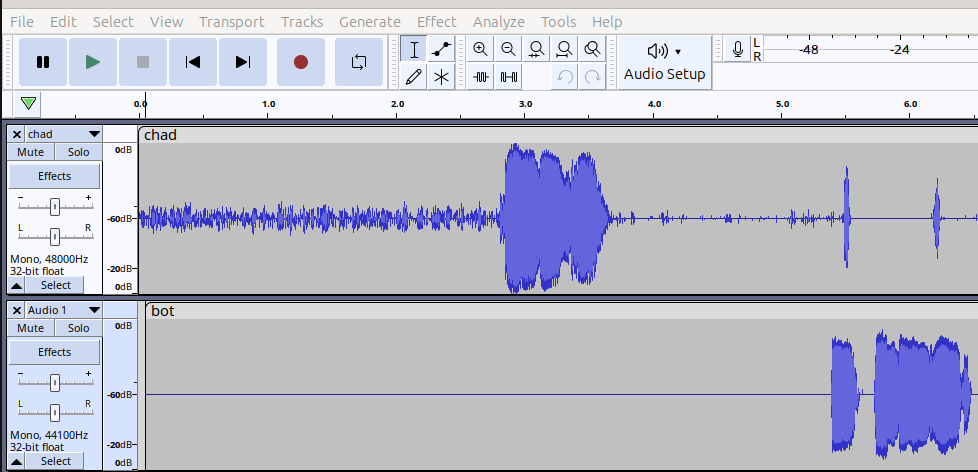
接下来,我们将两个 WAV 文件导入多功能音频工具 audacity。根据前面提到的 RTP 偏移量,很容易对齐两个音轨。波形还显示 Chad 端的回声消除功能出现短暂故障。
现在,我们将两个音轨的混音导出为单个 WAV 文件,以便于播放。现在我们有了一个音频文件,我们需要识别其中的“语音”。为此,我们可以安装silero-vad,这是一个非常常见的基于“AI”(或 ML)的语音活动检测库,用于在 WAV 文件中查找语音。
python3 -m venv env
source env/bin/activate
pip install silero-vad接下来,我们运行下面的 Python 脚本。它导入并初始化 silero,加载 WAV 文件,并使用辅助函数get_speech_timestamps获取语音开始和语音结束时间戳的数组。我们将它们转储到与上表类似格式的时间戳中:
import os
from silero_vad import load_silero_vad, read_audio, get_speech_timestamps
silero = load_silero_vad()
wav = read_audio(os.getcwd() + '/openai-realtime-api.wav')
speech_timestamps = get_speech_timestamps(
wav,
silero,
return_seconds=False, # Return speech timestamps in samples
)
FS = 16000 # hz
print(speech_timestamps)
print('START\tDUR\tGAP')
for i in range(1, len(speech_timestamps)):
print(speech_timestamps[i-1]['end'] / FS, '\t',
speech_timestamps[i]['start'] / FS, '\t',
(speech_timestamps[i]['start'] - speech_timestamps[i-1]['end']) / FS)运行脚本python3 webrtchacks.py将产生以下输出:
[{'start': 45088, 'end': 58848}, {'start': 87072, 'end': 120800},
{'start': 125472, 'end': 135136}, {'start': 138784, 'end': 152544},
{'start': 162336, 'end': 192992}, {'start': 222752, 'end': 234976},
{'start': 237600, 'end': 266720}, {'start': 269344, 'end': 281056},
{'start': 284704, 'end': 304096}, {'start': 309280, 'end': 338400},
{'start': 367136, 'end': 376800}, {'start': 379936, 'end': 413152},
{'start': 418336, 'end': 440800}]
START DUR GAP
3.678 5.442 1.764 --- first gap
7.55 7.842 0.292
8.446 8.674 0.228
9.534 10.146 0.612 --- second gap
12.062 13.922 1.86
14.686 14.85 0.164
16.67 16.834 0.164
17.566 17.794 0.228
19.006 19.33 0.324
21.15 22.946 1.796 --- third gap
23.55 23.746 0.196
25.822 26.146 0.324虽然其中一些语音事件是误报,但我们可以看到三次说话人切换的间隔分别为 1.764 秒、1.86 秒和 1.796 秒。与手动提取的值相比有轻微的偏差。
使用所示技术测量响应延迟非常准确。虽然它忽略了播放造成的任何延迟,但这是一个恒定的偏移。而且测量可以相当好地实现自动化。
基准测试以及就基准测试方法达成一致非常重要。显然,无论是对于 OpenAI(实际上就是 Justin Uberti),还是对于如何将 WebRTC 用于此用例,都还有一些工作要做。敬请期待!
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/57184.html