
来源:音视频小话
链接:https://mp.weixin.qq.com/s/43KlmfNxXYpryG1Ssjq-1w
上一篇博文总体描述如何构造一个webrtc视频会议实时语音翻译文字的总体架构:webrtc视频会议AI实时语音转字幕。
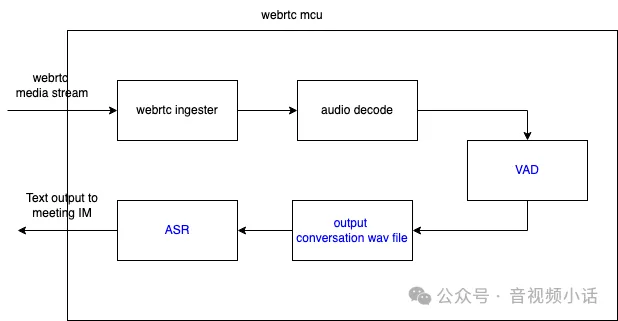
其中语音转文字部分的第一步需要有效的语音断句,这里采用VAD方法(Voice Activity Detection),检测语音会话什么时候开始(有声音),什么时候结束(无声音)。
实际上,当前openai的webrtc语音接入,用户语音的输入也是经过了语音转文字的过程,其中也有经过VAD到ASR的过程。
见openai webrtc接入文档中:Transcription begins when the input audio buffer is committed by the client or server (in server_vad mode).在信令初始化过程中,可以设定openai webrtc服务端的vad参数:
"turn_detection": {
"type": "server_vad",
"threshold": 0.5,
"prefix_padding_ms": 300,
"silence_duration_ms": 200
},Realtime API models accept audio natively, and thus input transcription is a separate process run on a separate ASR (Automatic Speech Recognition) model, currently always whisper-1。
也就是openai的webrtc语音接入,语音转文字,也是要在服务的实现VAD和ASR的。而且ASR服务当前使用的是whisper-1(其模型也已经开源)。
本文介绍两种vad开源实现。推荐两个常用的vad开源:
- libwebrtc中的vad
- fftw3
1、libwebrtc中的vad
libwebrtc库是webrtc客户端常用的动态库,东西非常多,也非常大。很多模块可以进行抽离后,直接拿出来使用,vad就是非常容易抽离和独立应用的模块。libwebrtc地址:
git clone https://webrtc.googlesource.com/src1.1 vad部分的代码抽取
代码路径:
common_audio/vadvad的模块比较独立,仅仅需要include几个外部的头文件:
rtc_base/sanitizer.h
rtc_base/compile_assert_c.h
common_audio/signal_processing/
thirty_payty/spl_sqrt_floor1.2 代码示例
webrtc中常用opus编码,采样率48000,双通道,解码后采用int16_t类型的pcm数据
VadInst* vad = WebRtcVad_Create();
WebRtcVad_Init(vad);
//设置敏感度
WebRtcVad_set_mode(vad, 3);
int sampleRate = 48000;
int frameLength = 960;
for (...) {
int16_t* frame = ReadFrameSample(frameLength);
int ret = WebRtcVad_Process(vad, sampleRate,
frame, frameLength);
//ret == 1, voice is valid.
vad_callback_->OnCallback(ret);
}
WebRtcVad_Free(vad);2、fftw3
FFTW(Fastest Fourier Transform in the West)是一个用于计算快速傅里叶变换(FFT)的高性能C库。可以用来做VAD检测。它的功能非常强大,不仅仅可以用来做vad。debian系统可以直接安装。
apt-get install -y libfftw3-dev2.1 代码例子
webrtc中常用opus编码,采样率48000,双通道,解码后采用int16_t类型的pcm。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <stdint.h>
#include <fftw3.h>
#define SAMPLE_RATE 48000 // 采样率提高到 48000 Hz
#define FRAME_SIZE 1024 // 增加帧大小以提高频率分辨率
#define THRESHOLD 30000.0 // 根据新的帧大小和数据类型调整阈值
// 计算能量
double calculate_energy(int16_t *frame, int frame_size) {
double energy = 0.0;
for (int i = 0; i < frame_size; i++) {
double sample = (double)frame[i] / 32768.0; // 归一化到 [-1.0, 1.0]
energy += sample * sample;
}
return energy;
}
// 进行FFT变换
void perform_fft(int16_t *frame, fftw_complex *fft_out, fftw_plan plan) {
// 将 int16_t 数据归一化并转换为 double 类型
double *normalized_frame = (double *)malloc(sizeof(double) * FRAME_SIZE);
for (int i = 0; i < FRAME_SIZE; i++) {
normalized_frame[i] = (double)frame[i] / 32768.0; // 归一化
}
// 将实数帧数据复制到复数数组中,虚部设为0
for (int i = 0; i < FRAME_SIZE; i++) {
fft_out[i][0] = normalized_frame[i];
fft_out[i][1] = 0.0;
}
// 执行FFT计划
fftw_execute(plan);
free(normalized_frame);
}
// 判断是否为语音帧
int is_voice_frame(int16_t *frame, fftw_complex *fft_out, int frame_size) {
double energy = calculate_energy(frame, frame_size);
// 计算频谱幅度
double magnitude = 0.0;
for (int i = 0; i < frame_size / 2 + 1; i++) {
magnitude += sqrt(fft_out[i][0] * fft_out[i][0] + fft_out[i][1] * fft_out[i][1]);
}
magnitude /= (frame_size / 2 + 1);
// 根据能量和频谱幅度判断是否为语音帧
if (energy > THRESHOLD && magnitude > THRESHOLD) {
return 1;
} else {
return 0;
}
}
int main() {
// 初始化FFTW3
fftw_init_threads();
fftw_plan_with_nthreads(4);
// 创建FFT计划
fftw_complex *fft_out = (fftw_complex *) fftw_malloc(sizeof(fftw_complex) * FRAME_SIZE);
fftw_plan plan = fftw_plan_dft_r2c_1d(FRAME_SIZE, NULL, fft_out, FFTW_ESTIMATE);
// 模拟语音数据(这里用随机数代替)
int16_t *frame = (int16_t *) malloc(sizeof(int16_t) * FRAME_SIZE);
for (int i = 0; i < FRAME_SIZE; i++) {
frame[i] = (int16_t)(rand() % 65536 - 32768); // 生成 [-32768, 32767] 的随机数
}
// 进行VAD检测
if (is_voice_frame(frame, fft_out, FRAME_SIZE)) {
printf("This is a voice frame.\n");
} else {
printf("This is a non-voice frame.\n");
}
// 释放资源
fftw_destroy_plan(plan);
fftw_free(fft_out);
free(frame);
fftw_cleanup_threads();
return 0;
}3 总结
本文介绍两种常用的vad开源,实现opus解码后语音的有效性检测,用来进行语音断句。后面继续介绍ASR的开源实现,也就是语音(pcm)转文字的开源实现。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
