
音视频的很多业务也开始使用AI工具,本文介绍如何使用AI对webrtc视频会议进行升级,实时生成会议内容的实时字幕。
作者:音视频小话
原文:https://mp.weixin.qq.com/s/1prjIeQ2B-ZNun0rqq3hCA
扩展:如果转换的文字,再经过TTS服务(文字转语音),可以再转换成语音,推送该音频流回到视频会议的某用户,这样就实现视频会议的同声传译了。
本文主要集中在语音内容的实时字幕,而TTS服务部分,后面会有新的博文来讨论。
1 应用场景
webrtc视频会议需要实时字幕的需求一般有这几种:
- 跨国英文会议:与会者能听懂一些英文,有一些英文基础,但不是全部能听懂,通过字幕提示就能完美参会。AI未来会慢慢消灭同声翻译。
- 会议纪要比较重要的会议:如技术讨论会议,内容比较多,讨论比较激烈,需要论述和总结,如果有文字记录,后面写总结和博客,就比较容易。
- webrtc面试系统:尤其是高端技术面试,可能有多轮面试。在面试后,未参加面试主管想知道某些技术问题的回答记录,如果有自动的文字记录,对招聘方有很大帮助;
2 如何实现
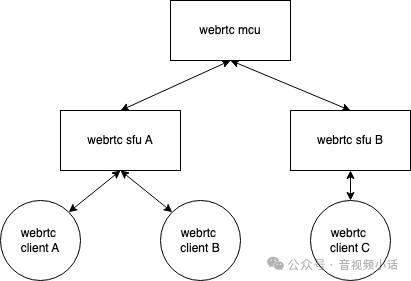
整个webrtc视频会议系统一般有这几部分:
- webrtc客户端:用户音视频webrtc接入端,常规安卓,ios,windows pc,macos pc,或web原生;
- webrtc sfu服务器:用于接入webrtc客户端,实现音视频媒体转发;
- webrtc mcu服务器:用于webrtc的音视频二次加工,如webrtc流的转码/转推,媒体流视频合成/音频合声等。
如下图:

实现AI实时语音字幕,主要实现就在webrtc mcu服务程序中,具体mcu中的实现模块与流程如下:
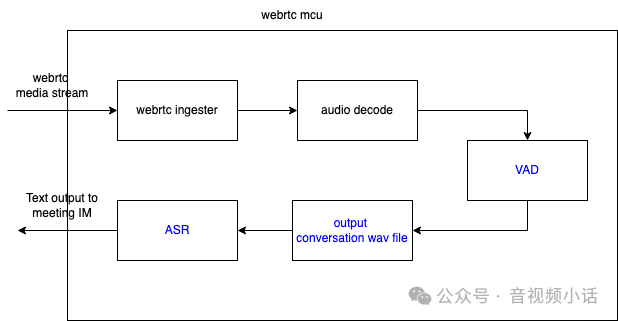
关键步骤:
- 拉取webrtc音频流(webrtc ingester):从sfu服务拉取webrtc音频流,也就是拉取会议中参与者的音频流,准备为后续处理对应的音频数据。
- 音频解码(audio decode): 解码音频为pcm原始数据,方便后续做vad检测,和生成对应的wav语音文件;
- VAD(Voice Activity Detection): 语音有效检测模块,检测语音会话什么时候开始(有声音),什么时候结束(无声音);
- 生成某个会话的音频文件wav:把原始pcm在某个会话结束的时候,存一个wav音频文件;
- 语音转问之模块(ASR): 把wav文件用ai工具,如whisper,解析出文字,并通过会议的IM接口把对应文字写入到视频会议中。
2.1 webrtc ingester
webrtc拉流,这里推荐cpp_streamer开源,实现服务端一个简单的PeerConnection,能支持对SRS webrtc拉流,也能支持MediaSoup webrtc的拉流。
cpp_streamer 开源地址:
https://github.com/runner365/cpp_streamermediasoup拉流demo:
https://github.com/runner365/cpp_streamer/blob/v1.1/src/tools/whep_srs_demo.cppsrs拉流demo:
https://github.com/runner365/cpp_streamer/blob/v1.1/src/tools/whep_srs_demo.cpp2.2 audio decode
对于opus的解码,推荐使用ffmpeg decode的api,这里参考ffmpeg api例子:
参考ffmpeg开源代码中
doc/examples/decode_audio.c2.3 VAD(Voice Activity Detection)
语音检测,检测语音会话什么时候开始(有声音),什么时候结束(无声音)。当前有很多开源,推荐两个常用的,可以供你选择:
- libwebrtc中的vad
libwebrtc 开源代码:common_audio/vad/- fftw3
FFTW(Fastest Fourier Transform in the West)是一个用于计算快速傅里叶变换(FFT)的高性能C库。可以用来做VAD检测。debian系统可以直接安装:
apt-get install -y libfftw3-devTODO:后续会再写博文和个人开源,介绍如何写一个自己的VAD程序。
2.4 写wav文件
TODO:后续会给出博文和个人开源,如何用pcm写一个wav文件。
2.5 ASR
语音转文字(Automatic Speech Recognition, ASR)是一种将人类语音信号转换为对应文本的技术。推荐两个开源:
- 首先是openai的whisper
OpenAI Whisper,一种先进的AI模型,重新定义了语音转文字转换。
https://openai.com/index/whisper/TODO:本号后面会写博文,如何使用whipser开源模型来做语音转文字
- FireRedASR
小红书 FireRed 团队正式发布并开源了基于大模型的语音识别模型 ——FireRedASR。FireRedASR 在字错误率(CER)这一核心技术指标上,对比此前的 SOTA Seed-ASR,错误率相对降低 8.4%,充分体现了团队在语音识别技术领域的创新能力与技术突破。开源地址:
https://github.com/FireRedTeam/FireRedASR3 总结
本文介绍如何实现一个webrtc会议中,实时语音转文字,提供实时字幕的解决方案。防止篇幅过长,VAD和ASR的详细实现,本文没有介绍。后面号内博文会详细介绍如何实现:
- VAD:博文+开源
- ASR:博文+开源的应用
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。