
随着我们不断驾驭远程工作和虚拟互动的复杂性,对无缝和引人入胜的视频会议体验的需求从未像现在这样强烈。长期以来,WebRTC 一直是实现与会者之间实时通信的关键角色,但最近人工智能 (AI) 的进步正在将这些功能提升到新的高度。
在本篇文章中,我们将探讨 AI 改变 WebRTC 视频会议应用的精彩方式——从媒体处理和传输到提高生产力的功能以及创新的语音和视频机器人。
提升 WebRTC 媒体管道
WebRTC 视频会议应用程序执行多个步骤来实现与会者之间的通信。其中包括获取、处理和将媒体数据从一个设备传输到另一个设备。
将其视为一个媒体管道,从光线和声音进入您的设备的摄像头和麦克风开始,到在其他与会者的设备上播放相应的视频和音频流结束。
AI 正在成为这一管道的另一个阶段。然而,它并不是墙上的另一块砖,而是蛋糕顶上的樱桃。AI 正在增强媒体处理和传输能力,并引入创新功能,丰富整体体验。
这些改进和功能通常分为以下几类:
- 媒体处理和传输
- 提高生产力的技术
- 语音和视频机器人
媒体处理和传输
AI 正在通过降噪和背景消除等功能提升 WebRTC 的媒体处理能力。目前正在使用 RNNoise、Krisp SDK 和 MediaPipe 等工具来处理音频和视频流,然后再通过对等连接发送。
流程如下:
GetUserMedia API提供未经处理的原始流。- 未处理的数据流会经过在设备上或云上运行的基于 AI 的流程,具体取决于工具。
- 基于 AI 的流程生成经过处理的流,通过
RTCPeerConnection发送。
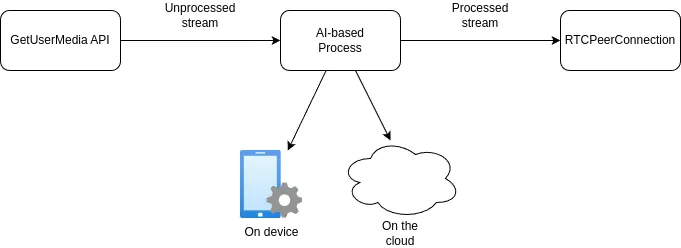

此外,Meta 和 Atlassian 等公司正在采用基于机器学习模型的方法来完善其带宽估算流程,优化其实时通信应用程序传输媒体的方式。
此外,Google Lyra 和 Microsoft Satin 等 AI 驱动的编解码器有望在保持质量的同时实现更高的音频压缩率。不过,这些技术还不能用于 WebRTC。
提高生产力的功能
AI 提供的功能可提高效率、减少人工工作量,并使业务环境中的决策更加明智。这些功能包括但不限于:
- 实时翻译
- 转录
- 总结
- 情感分析
- 字幕
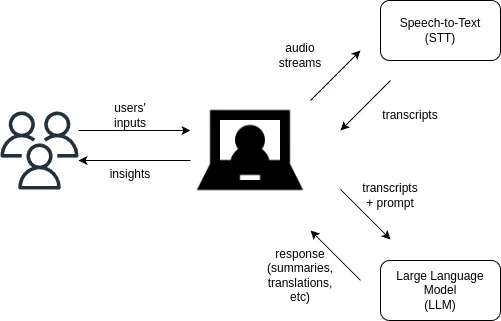
实现这些功能需要将媒体发送到语音转文本(STT)服务,如 Amazon Transcribe 或 Symbl.ai Streaming API,然后再发送到大型语言模型(LLM),如 OpenAI GPT 或 Meta Llama。这样就能以摘要、情感分析或响应请求的形式提供见解。
大型多模态模型 (LMM) 有望通过直接将音频流注入模型而无需 STT 服务来提供相同的方法并减少延迟。
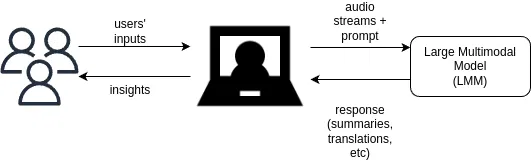
在撰写这篇文章时,OpenAI 已经启用了实时 API 的测试版访问权限,允许开发人员直接向其 GPT-4o 多模态模型提供音频流。
语音和视频机器人
AI 还支持语音和视频机器人参与 WebRTC 会话并与参与者互动。
使用的方法与实现辅助功能的方法类似。只是在这里,用户可以直接与 LLM 模型 “对话”,而 LLM 模型则会对用户的请求做出直接回应。
这些机器人还能提取相关信息并代表用户执行任务,如更新账户信息或进行预订。
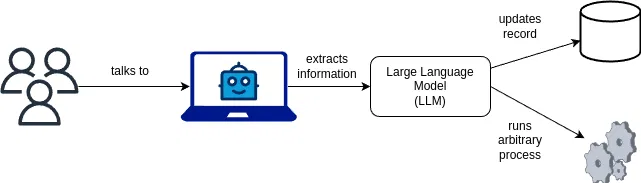
视频和语音机器人还能使用单独的无头浏览器或类似服务,加入第三方平台(如 Google Meet 或 Microsoft Teams)的视频会议会话。
利用 WebRTC 和 AI 改变虚拟交互
正如我们所看到的,AI 正在改变 WebRTC 视频会议应用程序的面貌。通过利用 AI 驱动的工具和技术,开发人员可以创建更具吸引力、更高效、更富有成效的通信体验。随着媒体处理、辅助功能以及语音和视频机器人的进步,可能性是无穷的。
作者:Hector Zelaya
译自:https://webrtc.ventures/2024/10/how-ai-is-enhancing-webrtc-video-conferencing-applications/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/53117.html