
WebRTC 正在改变我们的在线互动方式。它允许我们在网络浏览器之间直接共享音频、视频和数据,而无需额外的服务器。这项技术令人兴奋的新功能之一就是语音转文本(STT)。
此功能可将口头语言实时转换为书面文本,使沟通更加便捷,并改善用户体验。
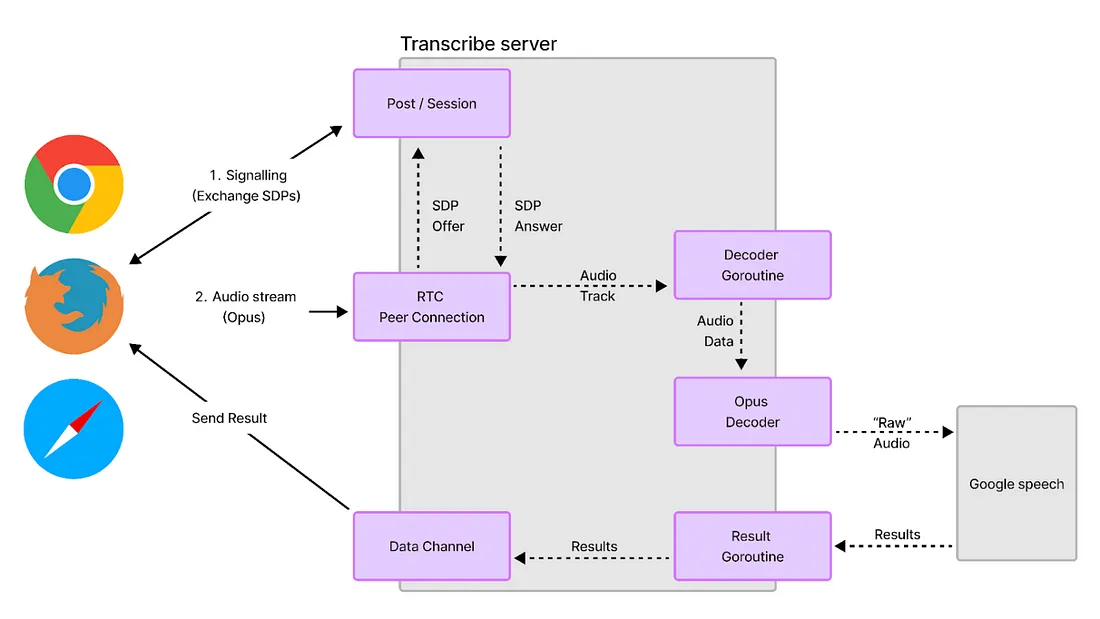
语音转文本技术如何与 WebRTC 配合使用
语音转文本技术使用智能计算机程序和语言工具将口头语言转化为文本。当与 WebRTC 结合使用时,这项技术可以改进各种应用。例如,它可以在视频通话中提供实时字幕,或生成便于搜索和查看的会议文本记录。
下面简单介绍一下语音文本如何与 WebRTC 配合使用:
- 采集音频:
WebRTC 从用户的麦克风中采集音频。
- 处理音频:
音频被发送到 “语音转文本 ”服务,该服务将音频翻译成文本。
- 显示文本:
文本显示在屏幕上或用于其他目的,如创建可搜索的文档或日志。
这种实时转录在在线教育、远程医疗保健和客户支持等领域特别有用。它有助于确保准确捕捉重要信息,并在稍后进行审查。
AI 对语音转文本技术的改进
AI 为语音转文本技术带来了额外的改进,使其更加有效和用户友好。AI 可以帮助系统过滤背景噪音,识别不同的说话者,甚至根据说话的方式理解情绪。例如,AI 可以分辨出某人是在提问还是在陈述,从而帮助创建更准确、更有反映力的文本。这些改进意味着由 AI 驱动的语音转文本系统不仅速度更快,而且更加智能,确保转录的内容反映了口语的真实本质。
自然语言处理(NLP)在语音转文本中的作用
自然语言处理(NLP)是人工智能的一种形式,可帮助计算机更自然地理解人类语言。在语音转文本技术中,NLP 通过提高系统识别口语的准确性发挥着重要作用,即使在人们口音不同或语速较快的情况下也是如此。NLP 还能帮助技术理解句子中单词的含义,使文本输出更准确、更有意义。这种把握上下文的能力可确保转录的内容不仅仅是一串单词,而是一个清晰易懂的句子,从而提升用户体验。
如何在 WebRTC 中添加语音转文本
要将语音转文本与 WebRTC 应用程序集成,您可以使用各种服务,例如 Google Cloud Speech to Text。以下是有关如何使用 Google 服务进行设置的分步指南:
步骤 1:启动 WebRTC 连接
// 设置 WebRTC 连接
const peerConnection = new RTCPeerConnection (configuration);说明 这段代码初始化两个对等方之间的 WebRTC 连接。配置部分包括建立连接所需的服务器的详细信息。
步骤 2:从麦克风获取音频
navigator.mediaDevices.getUserMedia({ audio: true })
.then(stream => {此代码请求访问用户的麦克风并采集音频流。流对象包含处理所需的音频数据。
步骤 3:将音频添加到连接
peerConnection.addStream (stream); const
audioTrack = stream.getAudioTracks ( )[ 0 ];使用 addStream() 将音频流添加到 WebRTC 连接中。getAudioTracks() 从音频流中获取音轨,以便进一步处理。
步骤 4:设置语音转文本 API
const speechToTextAPI = new GoogleCloudSpeechToText({
key: 'YOUR_API_KEY'
});此代码使用 API 密钥创建 Google Cloud 语音转文本服务的新实例。使用此密钥可访问用于转录音频的服务。
步骤 5:创建音频处理节点
const audioInput = new MediaStreamAudioSourceNode(audioTrack);
const audioProcessor = audioInput.context.createScriptProcessor(4096, 1, 1);MediaStreamAudioSourceNode(audioTrack) 将音轨连接到网络音频 API,以便进行实时处理。
createScriptProcessor(4096, 1, 1) 创建一个脚本处理器节点,以块为单位处理音频数据。4096 是每个块的大小,1, 1 代表输入和输出通道的数量。
步骤 6:处理音频以获取文本
当有足够的音频数据需要处理时,会触发 onaudioprocess。
event.inputBuffer.getChannelData(0) 获取音频样本。
speechToTextAPI.recognize(inputData) 将音频数据发送到 Google 的 API 进行转录,然后返回文本。然后将文本显示在屏幕上。任何错误都会被捕捉并记录下来。
步骤 7:完成音频设置
audioInput.connect(audioProcessor);
audioProcessor.connect(audioInput.context.destination);
})
.catch(error => console.error('Error accessing microphone:', error));audioInput.connect(audioProcessor) 将音频输入链接到脚本处理器进行实时处理。
audioProcessor.connect(audio input.context.destination) 确保处理后的音频被直接输出,即使它没有播放。
本指南介绍如何从麦克风捕获音频、使用语音转文本服务处理音频以及显示生成的文本。在实际应用中,您还需要处理错误、优化性能并收集用户反馈以改进系统。
用途和好处
可访问性:在通话或网络研讨会期间为有听力障碍的人添加实时字幕,使对话更容易理解。
实时转录:自动将会议、讲座和网络研讨会转换为可供稍后搜索和查看的文本。
多语言支持:将口语翻译成不同的语言,帮助团队跨境沟通。
语音命令:允许用户使用语音命令控制应用程序和导航,使交互更加直观。
挑战
使用 WebRTC 的语音转文本面临一些挑战:
准确性:语音识别可能会因不同的口音、背景噪音或较差的音频质量而受到影响。
延迟:实时转录需要快速,这对于速度较慢的互联网连接来说可能具有挑战性。
隐私和安全:保护敏感的音频数据至关重要,特别是在医疗保健等隐私最受关注的领域。
作者:Muhammad Aamir
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/52206.html
