
WebRTC 解决方案中经常被低估的一个方面是媒体质量监控。我们需要记住,我们构建实时解决方案不仅仅是为了进行音频和视频通信,而是为了提供尽可能好的体验。为了确保做到这一点,我们需要具备强大的可观察性,这样才能发现问题和倒退,衡量所发布的改进措施的影响,调试客户报告的问题,或使基础架构动态适应不断变化的条件。

发送什么?
我们需要回答的第一个问题是:发送什么数据?这包括两个方面:元数据和 WebRTC 统计数据。
对于元数据,通常要包括设备、软件和用户的上下文(如地理位置)。我们还包括用户的水桶信息,以防我们正在进行 A/B 测试或其他类型的实验。
对于 WebRTC 统计,有三种典型的方法:
a) 从服务器发送简单的指标,如比特率和丢包指标。
b) 从客户端发送简单指标,包括从解码帧速率到音频间隙甚至缓冲区大小等任何指标。
c) 使用从 WebRTC getStats() 获取的所有信息,从客户端发送原始数据,并让服务器决定如何处理这些数据。
方案 b)往往能提供最大的价值,而且更易于维护。方案 a)缺乏许多重要的指标,比如发送视频比特并不能保证接收方能解码。选项 c 会占用更多资源,需要在服务器端进行后处理。
如何发送?
您有两种选择。要么使用媒体服务器连接(websockets、数据通道等)将所有客户端指标发送到服务器端,要么使用独立的摄取端点另辟蹊径。
如果可能,我强烈建议使用后者,通常是通过简单的 HTTP 数据摄取 API。这不仅能分离解决方案中的关注点,还能让你在无法连接媒体服务器的情况下发送数据,例如报告连接故障。
在可能的情况下,还可以尝试通过压缩和批处理来优化发送,尤其是在数据量或事件数量非常大的情况下。
如何处理?
所有接收到的数据都应存储在某种队列系统(通常是 Kafka 或类似的基础设施)中,以便一个或多个消费者以最快的速度读取。该队列还为我们提供了在需要时重播事件的能力,不过在实际应用中,我们并不会做太多这样的事情。
如果我们选择发送客户端指标(”发送什么 “中的选项 b),那么除了一些节流/安全和合理性检查以防止不良数据污染存储外,所需的服务器端处理将微乎其微。
但是,如果我们选择发送原始客户端数据(选项 c),则需要对原始数据进行处理,以便从原始数据中提取比特率等指标。
如何存储数据?
通常,我们至少以两种不同的方式存储数据:
- 为了调试,我们需要原始的分类数据。长期保留或实时访问不是必须的,尽管它们总是有益的。如果需要长期保留,可以使用 BigQuery 或 Snowflake 等产品;否则,可以使用 Elasticsearch 等产品。
- 在监控、警报和分析方面,我们使用聚合数据来生成具有不同维度(如设备、国家/地区、应用程序或用于 A/B 测试的通用桶)的时间序列指标。理想情况下,我们希望长期保留数据并尽可能实时访问。
如何消费?
这取决于我们使用的存储及其提供的应用程序接口和工具。通常情况下,有一个 API 用于消费数据,该 API 可集成到 WebRTC 基础架构中用于警报和动态调整,还有一些可视化工具用于查询存储中的数据。在许多情况下,这种工具就是开源的著名 Grafana 解决方案。
考虑到以上五点,参考架构就是这样的:
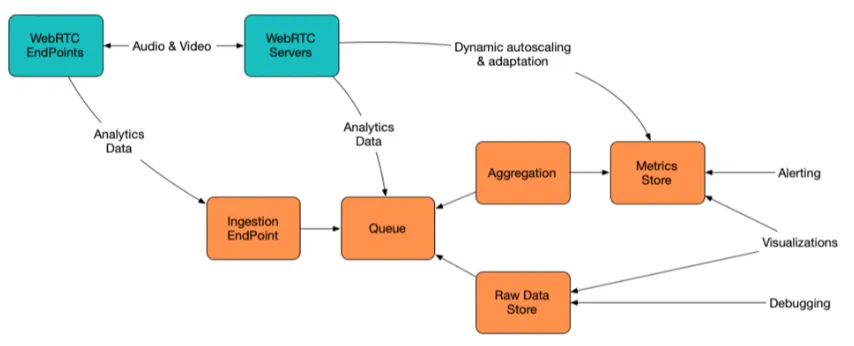
这种架构通过独立的摄取端点将媒体和数据路径分离开来。它允许原始数据存储,但保留时间有限,以便于调试;允许聚合指标存储,但保留时间较长,以便于警报、可视化和调整。
这种架构的一个显著优势是,只需连接一些现有部件,就能轻松实现数据基础设施的零编码。
- 对于摄取(API和队列),我们可以使用 segment.com,它为不同平台提供了可扩展的解决方案,具有多种集成和客户端应用程序接口。
- 对于聚合和指标存储,我们可以使用 aggregations.io,它可以使用 JSON 配置语言灵活定义聚合,并提供经济实惠的长期存储。它可以轻松连接到著名的 Grafana 工具,用于可视化和警报。
- 对于原始数据存储和调试,我们可以使用 Elasticsearch 协议栈,通过其 Kibana 工具提供具有索引和查询功能的存储。
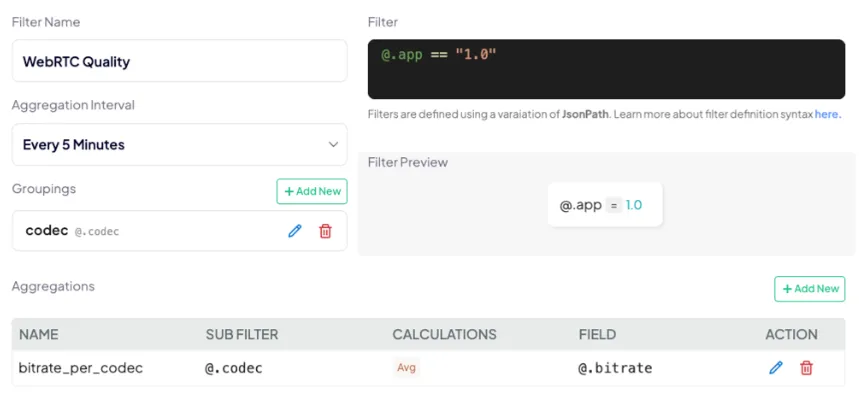
有了这个解决方案,您就能可靠地监控和确保 WebRTC 基础设施的质量,并获得实时更新和无限保留的可视化效果。下面是一个非常常见的指标(视频比特率)在不同维度(编解码器)下的配置和结果示例:

您怎么看?您如何解决这个问题?
作者:Gustavo Garcia
来自https://twitter.com/anarchyco
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/45866.html
