
上个月,Lorenzo Miniero 发布了一篇关于他在Janus 上所做的工作的更新文章,以改进其 AudioBridge 插件。它触及了我很长一段时间(如果有的话)没有写过的一点,所以我也想分享我对此的想法和看法。
我将首先快速解释一下 – Lorenzo 为 Janus 添加了许多层次和灵活性,这是在 WebRTC 会议中采用混合音频路线的开发人员所需要的。这里我想讨论的是什么时候使用混音,什么时候不使用混音。和其他事情一样,这里通常没有明确的决定。
WebRTC 中什么是混合、什么是路由?
WebRTC 中的群组通话可以采用不同的形式和规模。大多数情况下,WebRTC 多方通话有 3 种主要架构:mesh(网格)、混合和路由。
我将在这里重点讨论混合和路由,因为它们可以很好地扩展到 100 名或更多用户。
让我们从基础开始。
假设有 5 个人之间的对话。这些人中的每个人都可以说出自己的想法,其他人也可以听到他的讲话。如果所有这些人彼此远程,并且我们现在需要在 WebRTC 中对其进行建模,我们可能会将其视为如下图所示:
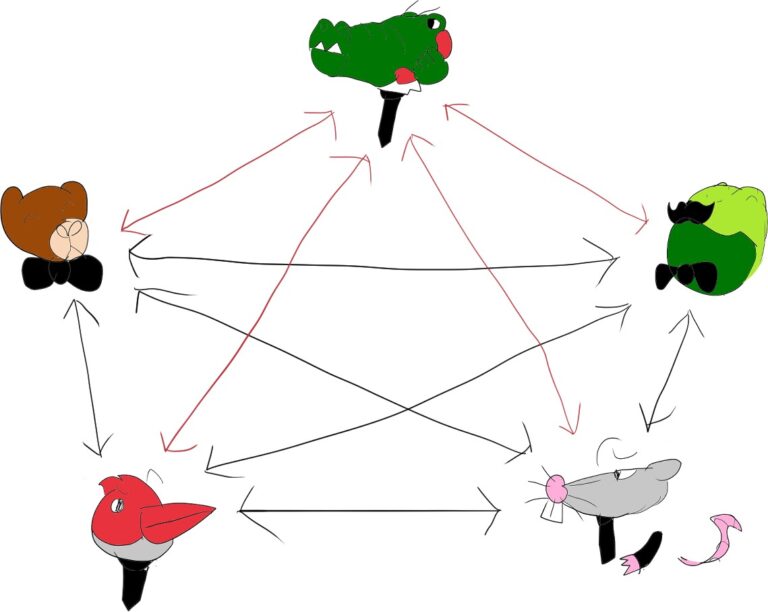
这称为Mesh网络。它对我们来说最大的缺点(尽管还有其他缺点)是它的混乱——参与者之间的连接数量随着用户数量呈多项式增长。我们需要分别向所有参与者发送相同的音频流,这是另一个巨大的缺点。通常,我们假设(并且有充分的理由)我们可用的网络是有限的。
最直接的解决方案是让中央媒体服务器混合所有音频输入,减少所有网络流量和用户处理:
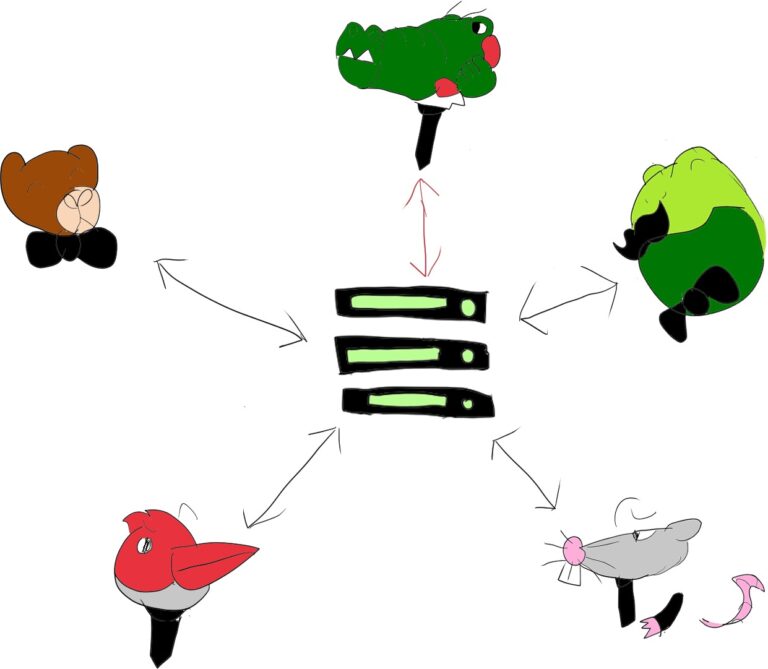
该媒体服务器通常称为 MCU。在这里,用户 “感觉 “到他们是在与一个单独的实体/用户进行会话,而 MCU 则代表用户处理所有令人头疼的问题。
对于服务提供商来说,这种混合器方式可能有点昂贵,有时也不是最灵活的方式。因此,我们引入了 SFU 路由模式,但主要用于视频会议。在这里,我们试图同时享受两个世界–我们让 SFU 对媒体进行路由,试图将比特率和网络使用保持在合理水平,同时努力降低我们作为服务提供商的托管和媒体处理成本:
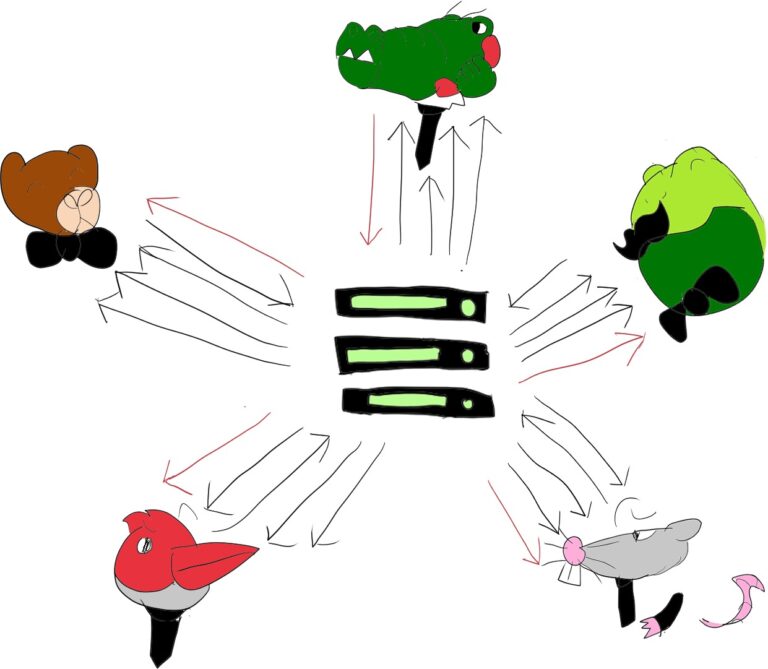
SFU 几乎已成为视频会议的常用架构模式。不过,语音会议一直处于两者之间。这可能是因为在 WebRTC 出现之前,音频桥接器就已经存在并广泛使用了。
这就引出了一个问题:我们应该为群组通话中的音频使用哪种架构?我们应该在媒体服务器中混合音频,还是像处理视频一样路由音频?
在我尝试回答这个问题之前,我还想再介绍一件事,那就是目前我们在 WebRTC 中可用的音频媒体处理工具。
WebRTC 中可用的音频处理工具
音频编码和解码是基础事情。但除此之外,还有相当多的媒体处理和网络相关算法可以帮助应用程序达到所需的音频规模和质量。
在列出它们之前,以下是我收集所有这些内容时想到的一些想法:
- 该列表是动态的。随着新技术的引入,它每年都会发生一些变化。一个例子是主动说话者检测,首先由 Jitsi 采用,然后由hopin团队添加到mediasoup。
- 您无法真正针对所有用例始终使用它们。需要挑选与用例、用户和所处的特定上下文相关的选项。
- 我们现在也有一个基于机器学习的工具,我们肯定会在一两年内拥有更多这样的产品。
音频电平(Audio level)
音频电平有一个 RTP 标头扩展。这允许 WebRTC 客户端指出发送的编码音频数据包的音量。
这样,接收方就可以使用该信息,而无需对数据包进行解码。
如何使用?
如果没有或很少有语音活动,或者音频电平太低(反正也没人会听到里面的内容),则决定是否需要解码该数据包,或者直接丢弃它。
您可以用 DTX 替代它(见下文),或在 Last-N 架构中不转发数据包(见下文)。
不将其内容与其他音频信道混合(它不包含对任何人都有用的足够信息)。
DTX
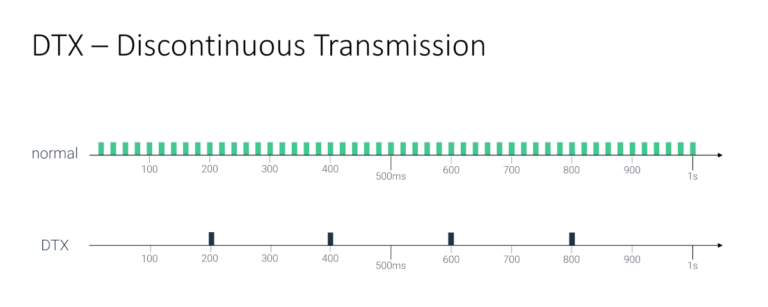
如果没有什么需要发送的信息–对方没有说话,但麦克风是打开的–那么就发送 “静音”,但通过网络发送的数据包要少一些。
这就是 DTX,它非常棒。
在大型会议上,大多数人都会倾听,而不会相互讲话。因此,大多数音频流将只是 “静音 “或静音。如果不是静音,那么发送 DTX 而不是实际音频就会减少产生的流量。这对 SFU 来说是个福音,因为它最终处理的数据包会更少。
在路由媒体时,SFU 媒体服务器也可以决定用 DTX 数据 “替换 “从用户处接收到的实际音频(因为用户的音频电平较低,或者因为他做出了 Last-N 决定)。
PLC
Packet Loss Concealment(丢包隐藏)
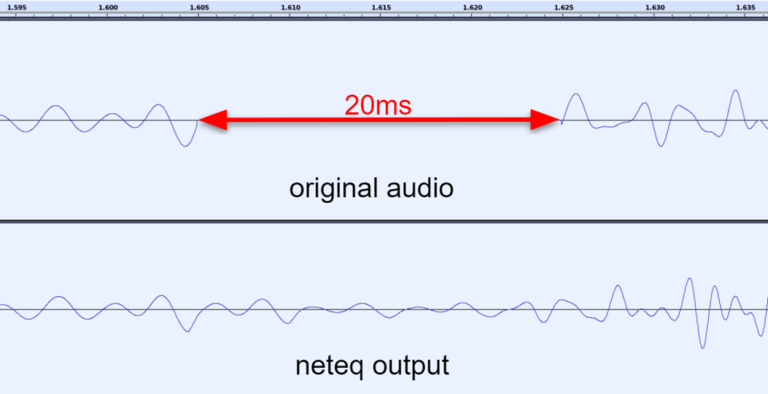
数据包会丢失,但仍有内容需要播放给用户。
您可以决定播放静音、重复上次听到的数据包、降低音量等。
这既可以在服务器端完成(特别是在 MCU 混合器的情况下),也可以在客户端完成(浏览器中已经实现了这种算法)。SFU 可以忽略这一点,主要是因为它们并不对实际媒体进行解码和处理。
有时,可以使用机器学习来完成,如谷歌专有的 WaveNetEq,它试图根据过去接收到的数据包来估计和预测丢失数据包中的内容。
丢包隐藏并非在任何时候都能做到,但它是必要的处理方式。
RTX 和 NACK
理论上,您可以对丢失的数据包进行重传。
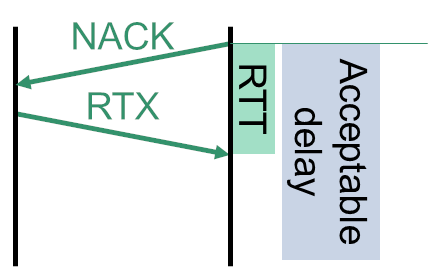
WebRTC 主要针对视频数据包执行此操作,但也可以为音频找到一个归宿。
由于 PLC 和 Opus inband FEC 技术效果很好,它现在/曾经是一个相当被忽视的领域。
目前,您可能会跳过这个工具,但如果我对音频质量的进步非常感兴趣,我会密切关注它。
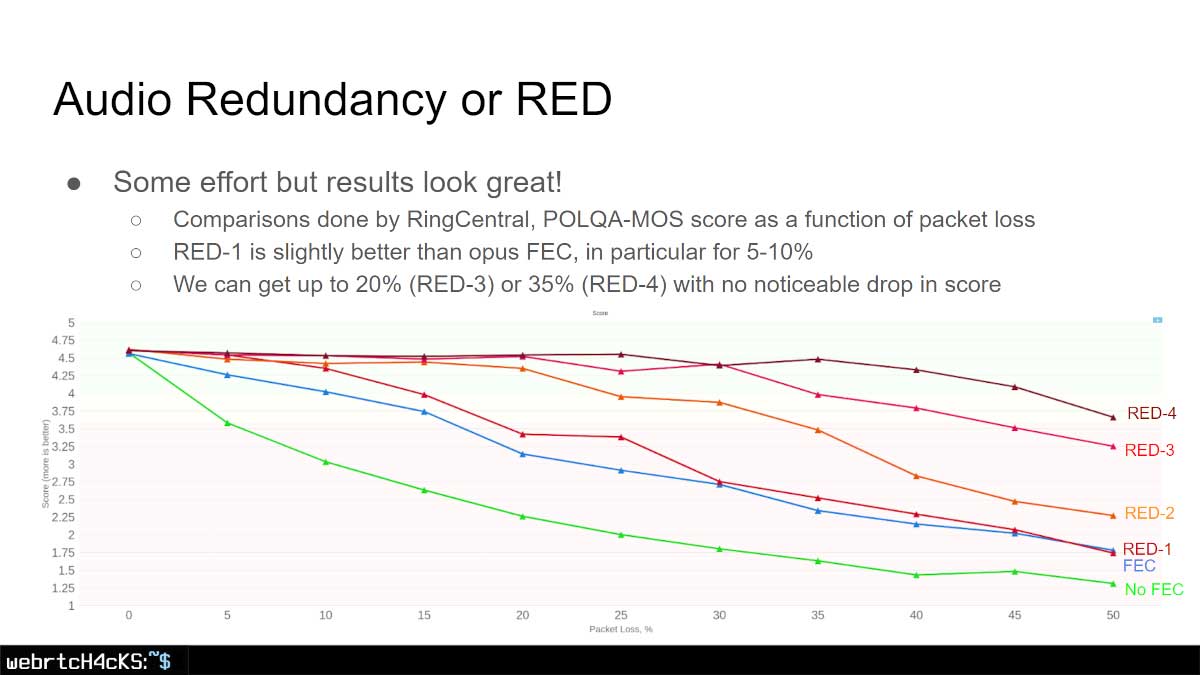
FEC 和 RED
FEC(前向纠错)是指发送可用于重建丢失数据包的冗余数据。RED(冗余编码)是我们通常对音频所做的,即复制编码帧。
音频带宽要求较低,因此复制帧不会对我们的网络造成太大负担,尤其是在视频通话中。
这种方法使我们能够以“低成本”获得更高的数据包丢失弹性。
这可以由客户端发送者使用,甚至可以从服务器端使用,以增强其接收到的内容 – 无论是作为 SFU 还是 MCU。
Last-N
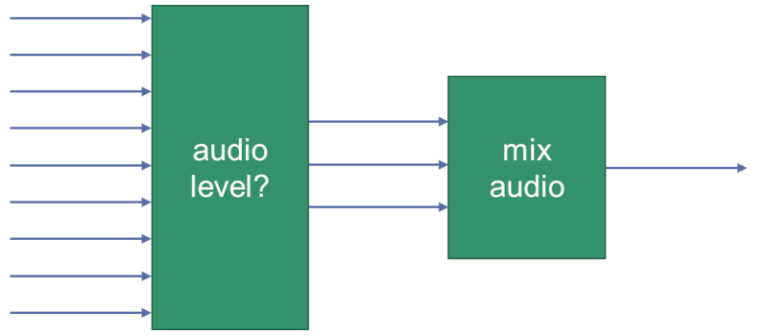
WebRTC 实现中的一个已知技术细节是,它在播放音频之前仅混合 3 个声音最大的传入音频通道。
为什么是3?因为我猜 2 个还不够,而 4 个似乎没有必要。此外,混合的源越多,噪声水平就会越高,特别是在没有良好的噪声抑制的情况下(更多内容见下文)
嗯……谷歌刚刚决定取消该限制。根据公告,这是因为音频解码在任何情况下都会发生,因此没有太多的性能优化来不混合它们。
所以现在,您可以决定是否要混合所有内容(以前无法混合),或者是否只想混合或路由一些最大音量(或最重要)的音频流(如果这就是您所追求的)。这会减少 CPU 和网络负载(取决于您使用的架构)。
例如,Google Meet 采用 Last-3 技术,最多仅向会议中的用户发送 3 个最大声的音频流。
噪声抑制:RNNoise等机器学习算法
如今,噪声抑制技术风靡全球。
RNNoise 是基于 ML 的噪声抑制算法中的佼佼者,如今颇受欢迎。
例如,Janus 在其 AudioBridge 中加入了 RNNoise,并在 MCU 混频器中针对每个输入流实施了可选的 RNNoise 逻辑,以处理基于通道的噪声抑制。
谷歌在其 Google Meet 云中添加了这一功能,他们的 SFU 实现将音频传递到专用服务器,由服务器处理噪声抑制,可能是通过解码、噪声抑制和编码返回音频。
混合可以让浏览器远离麻烦
为什么使用 MCU 来混合音频通话?因为它消除了浏览器的所有实施难题和细节。
为了了解它对服务器的一些影响,我建议您再次阅读 Lorenzo 的帖子。
这样做的好处在于,在大多数情况下,添加更多用户意味着需要投入更多云和硬件来解决问题。至少在某种程度上,这可以很好地发挥作用,而无需考虑扩展、去中心化和其他。
这也是多年来的做法。
以下是我在音频 MCU 中使用的工具:
| 工具 | 使用 | 推理 |
| Audio level | ✔️ | 解码更少的流将为服务器获得更高的性能密度。将此与 Last-N 逻辑结合使用 |
| DTX | ✔️ | 解码和编码时都是如此 |
| PLC | ✔️ | 分别在每个传入的音频流上 |
| RTX 和 NACK | ❌ | 今天做这个还太早 |
| FEC 和 RED | ✔️ | 如今,对于 MCU 来说,很少能看到这种受支持的功能。请考虑传出音频流,以及启用从设备输入的数据流 |
| Last-N | ✔️ | Last-3 是一个很好的默认值,除非您考虑到特定的用户体验(请参见下面的示例) |
| 噪声抑制 | ✔️ | 在输入通道上,先清理通过 Last-N 过滤的通道,然后再将输入数据流混合在一起 |
对于音频 MCU 需要注意的是,MCU 需要生成相当多不同的输出流。对于 10 位参与者和 4 个发言者(Last-4 配置),情况如下:
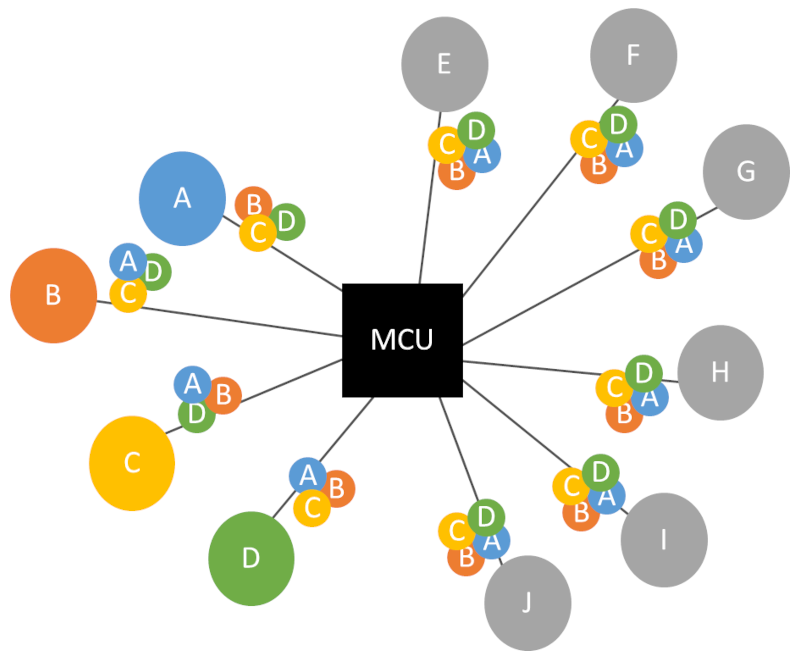
我们这里有 5 个独立的混音器:
- 1 混合所有 4 个有源扬声器
- 4 每次仅混合 4 个中的 3 个 – 我们不想让说话的人在流中混合自己的音频
路由带来更好的灵活性
为什么我们使用 SFU 进行音频会议?因为我们已经在视频会议中使用了 SFU……或者因为我们相信这是当今的现代方式。
说到音频路由,需要记住的是,我们要在 SFU 和与会者之间保持微妙的平衡,每个人都要发挥作用,最终获得更好的体验。
以下是我用于音频 SFU 的工具:
| 工具 | 使用? | 推理 |
| Audio level | ✔️ | 我们必须实现并启用这个东西,特别是因为我们真的非常非常希望能够执行 Last-N 逻辑,而不是向每个用户发送来自所有其他参与者的所有音频通道 |
| DTX | ✔️ | 我们也可以在这里使用它来检测静音(并从 Last-N 逻辑中删除)。在发送逻辑上,SFU 可以决定对 Last-N 中静音或低音量的通道进行 DTX,以节省一点额外的带宽(较小的优化) |
| PLC | ❌ | 不需要。我们对音频数据包进行路由,并让参与者修复发生的任何损失 |
| RTX 和 NACK | ❌ | 今天做这个还太早 |
| FEC 和 RED | ✔️ | 这可以添加到 SFU 的接收端和发送端,以提高音频质量。根据网络条件添加逻辑以动态设置何时和多少冗余也是一个优势。 |
| Last-N | ✔️ | Last-3 是一个很好的默认值。可能最好最多将其保留在 Last-5,因为这里的决定意味着参与者会使用更多的 CPU |
| 噪声抑制 | ❌ | 不需要。这可以在参与者方面完成 |
在许多方面,音频 SFU 比音频 MCU 更容易实现,但如何对其进行适当调整,以便从客户端实现中获得所有优势和优化,则是非常棘手的部分。
谈谈用例
与我处理的其他所有事情一样,使用哪种方法取决于具体情况。在这种情况下,主要的决定标准之一是您正在处理的用例以及您正在解决的场景。
以下是我想到的一些。
通往旧世界的门户
第一个问题非常 “显而易见”。
在 WebRTC 之前,没有人真正使用 SFU 架构召开过音频会议。即使有,也是独特、专有和特殊的。这个世界现在仍然围绕着 MCU 和混合音频桥接器。
如果您的服务需要连接到传统电话服务、通过 SIP(或 H.323)运行的现有 VoIP 服务部署、连接到大型 XMPP 网络–不管是什么–这个 “另一个 “世界将作为 MCU 运行。每个设备可能只能处理一个输入音频流。
因此,要想从您的服务中连接几个用户(无论您使用的是 SFU 还是 MCU),就需要在将这些用户连接到传统服务时将他们混合在一起。
混合音频视频会议
有些服务决定使用 SFU 来路由视频流,而使用 MCU 来路由音频流。
有时,这是因为主要服务开始时是音频服务(因此音频桥接器已经/正在成为服务的核心),而视频是在平台上附加的。有时是因为通向旧世界的网关是服务及其思维方式的核心。
有时则是为了减少发送的音频流数量,或降低仅音频参与者的技术要求。
无论出于何种原因,这都是您可能会遇到的问题。
这种方法的最大缺点是失去唇同步。要同步代表多个视频流混合内容的单一音频流,没有任何实际可行的方法。事实上,任何视频流都无法实现唇同步……
通常,我听到的借口是延迟差异并不明显,也没有人抱怨。这就引出了一个问题–那我们为什么还要使用唇同步机制呢?(我们这样做是因为它确实很重要,而且很明显–尤其是当网络比平时稍微颠簸的时候)
体验人群
想想一场足球比赛。体育场内有 50,000 人。当进球或失球时,会发生Raring。
通过混合 Last-3 音频流,当观众“远程”发生这种情况时,您不会听到任何有趣的声音。
这同样适用于虚拟在线音乐会。
你想要传达的体验的一部分是人群以及他们产生的噪音和声音。
如果我们都忙于降低噪音水平、抑制噪音、挑选人群中的 2-3 个声音进行混音,那么我们只会降低体验。
在某些情况下,人群很重要。并且通过路由音频流无法保持他们的正确体验。尤其是当我们开始谈论数百名更活跃的参与者时。
这种情况需要使用 MCU 音频桥接。当用户数量攀升时,可能会采用分布式方法。
元宇宙和空间音频
元宇宙即将到来,现在Apple Vision Pro 就在我们身边。但甚至在此之前,我们已经看到了一些元宇宙用例。
这里想到的一件事是它的沉浸部分,它带来了空间音频。听到来自不同方向的多种声音的意图——基于说话者所在的位置。
这意味着几件事:
- 对于每个用户,每个人说话的角度和距离(=音量)都会不同
- Last-3 策略不再有效。如果您可以单独区分方向和音量级别,那么可能需要在这里“混合”更多来源
您是通过 SFU 实现在客户端执行此操作,还是在 MCU 实现中执行此操作更好?
尝试在虚拟宇宙中举办音乐节会怎么样?您如何在音频方面给出人群的概念?
这些问题肯定没有单一答案。
很可能,在某些元宇宙情况下,SFU 模型将是最好的架构方法,而在其他情况下,MCU 会工作得更好。
记录这一切
这本身并不是一个用例,而是一个经常需要的功能。
当我们需要录制会话时,我们该如何做呢?
如今,至少 99% 的情况下都是将所有音频和视频源混合在一起,然后创建一个可作为 “常规 “mp4 文件(或类似文件)播放的单一流。
录制成单一流意味着要使用类似 MCU 的解决方案。有时是在无头浏览器中实现(就好像它是会话中的一个沉默参与者),有时是通过专用媒体服务器来实现。结果都是相似的–将多个输入流混合成一个输出流,直接传输到存储空间。
这样做的弊端是,除了需要花费精力来混合人们可能永远不会看到的内容(例如,这也是选择哪种架构的一个决定点)外,你只能看到和听到单个用户的单一观点–因为混合后的录音已经根据它的观点 “意见化 “了。
理论上,我们可以分别 “录制 “流媒体,然后再分别播放,但这并不容易实现,而且在大多数情况下也并不常见。
如今,我们在专业录音和播客服务中看到的一种折中方法是,以混合和分离的音频流进行录音。这样就可以根据混音需要进行后期制作,但需要手动完成。
会是哪一个呢?您的下一次音频会议需要 MCU 还是 SFU?
我们以此开始,也将以此结束。
这要看情况。
您需要了解自己的需求,然后确定所需的解决方案是基于 MCU 还是 SFU,或者两者兼而有之。
作者:Tsahi Levent-Levi
原文:https://bloggeek.me/webrtc-conferences-mix-or-route-audio/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/33223.html
