
我真正接触 WebRTC 的 ADM 是在做 iOS 混音的时候,iOS 的音频采集、播放之前没有做过,所以想着从 WebRTC 的音频采集播放代码里借鉴一下 AudioUnit 的使用,结果折腾了半天愣是没搞定,后来索性直接使用了 ADM,为混音项目草草地画上了句号。
今天,就让我们仔细看看 WebRTC 的 ADM。
功能介绍
ADM 被 WebRtcVoiceEngine 所使用,它在 WebRTC 中的地位如下图所示:
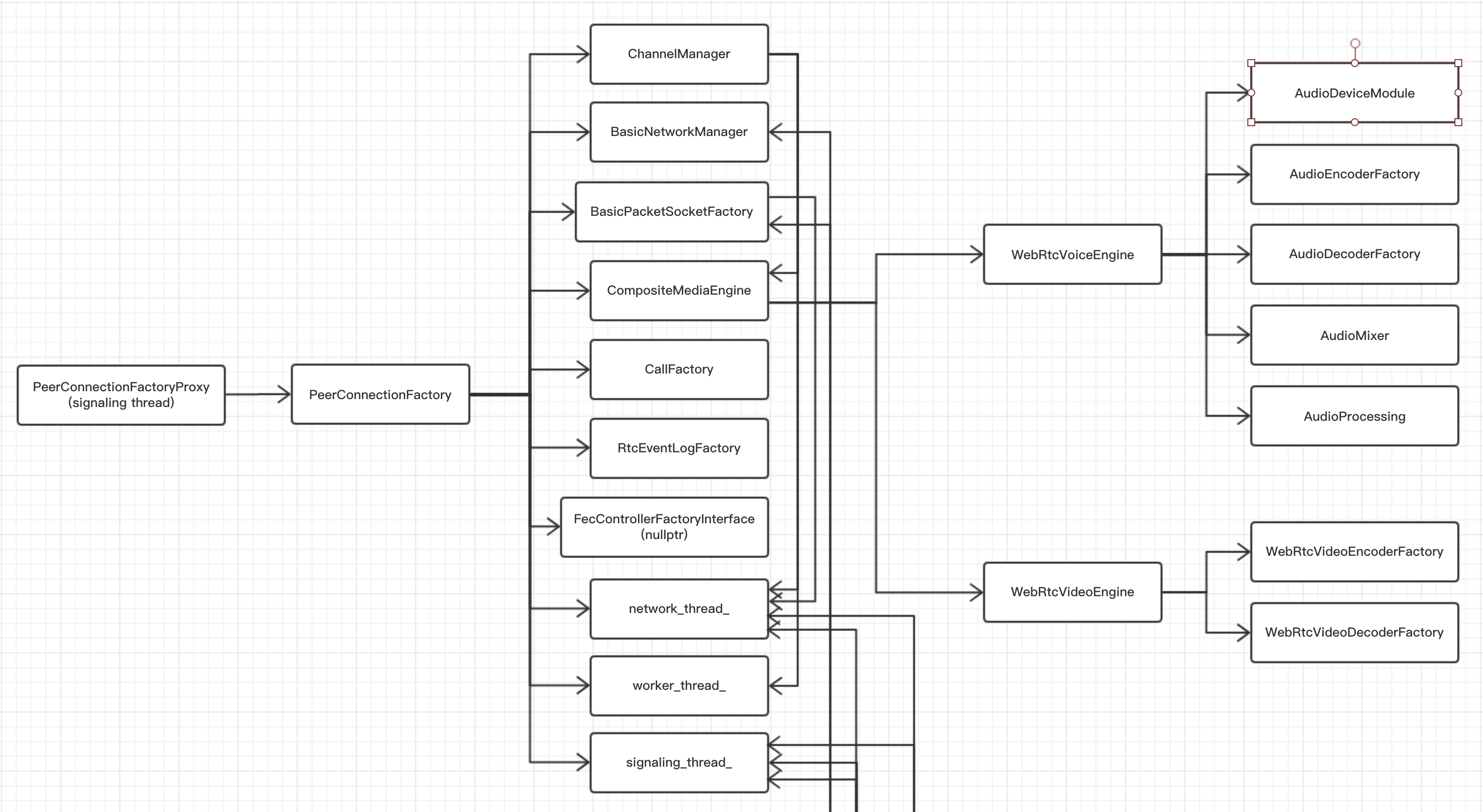
纵观 ADM 的接口,我们可以总结出它有如下功能:选择采集/播放音频设备、采集/播放启停控制、采集/播放音量控制、采集/播放静音、双声道采集/播放、获取播放延迟。
在 Android 和 iOS 平台,选择设备、静音、双声道都没有实现。Android 只支持设置播放音量,iOS 采集播放都不支持设置音量。播放延迟也并没有实际实现,返回的都是固定值,不过这个播放延迟也没有什么实际的作用,只是供查询用。
不过,Android 的 ADM 对象是在 Java 代码里创建的,而且 Java 类提供了采集/播放静音的接口,因此倒也能比较方便的使用这两个接口。其内部实现原理是,采集若静音,则发送静音数据(全零),播放若静音则播放静音数据(全零)。
下面就让我们来看看启停控制、数据传递在两个平台的实现。
Android ADM
Android 的 ADM 实现类在 sdk/android/src/jni/audio_device/audio_device_module.cc 中,其主要接口都是委托给 AudioInput 和 AudioOutput,而它们分别由 AudioRecordJni 和 AudioTrackJni 实现,而 AudioRecordJni 和 AudioTrackJni 的接口则是调用 Java 层的 WebRtcAudioRecord 和 WebRtcAudioTrack 类。
Java 层的 ADM 类只封装了创建 native 层 ADM 对象的接口,以及提供能能够设置采集、播放静音的接口,和我们上面介绍的 ADM 类关系不大。
音频采集
native 层的代码,最终都会调用到 org.webrtc.audio.WebRtcAudioRecord 这个 Java 类里,注意 WebRTC 项目里有两个 WebRtcAudioRecord 类,一个在 audio 包下,是新的实现,另一个在 voiceengine 包下,是老的实现,我们只关注新的实现。
WebRTC 的音频采集利用 Android 系统的 AudioRecord 类实现,AudioRecord 和我是老相识了,网上介绍的文章也很多,这里我就只强调几个有意思的要点:
- 由于采集到的数据要交给 native 代码使用,为了避免降低数据传递的开销,在初始化采集时(
initRecording),会把 direct byte buffer 的 native 地址,缓存在 native 层;但在 native 代码里,仍会有数据拷贝,不是直接使用这个 direct byte buffer 的地址; - 构造 AudioRecord 对象时,捕获
IllegalArgumentException,构造完成后,验证其状态为STATE_INITIALIZED; startRecording函数中,调用audioRecord.startRecording时,捕获IllegalStateException,并在之后验证其状态为RECORDSTATE_RECORDING;- 原来的实现里,若
audioRecord.startRecording后状态不对,会 sleep 200ms,再重试,一共重试三次,后来这一逻辑被去掉了; - 从 AudioRecord 读数据是在一个单独的线程里,这个线程会调用
Process.setThreadPriority(Process.THREAD_PRIORITY_URGENT_AUDIO)以提高线程优先级; - 音频数据采集到之后,送往 native 层之后,会把数据拷贝一份,交给一个可选的数据回调;这个逻辑有两个小问题,一是修改数据的需求无法满足,二是每次都新建数组,会引发内存抖动;
- 如果
audioRecord.read返回的读得数据大小不等于欲读数据大小,那就不会使用读到的数据,若返回值为ERROR_INVALID_OPERATION,那就会停止采集、报告错误;
数据传递:
- 在采集线程读取到数据后,调用 native 接口执行到
AudioRecordJni::DataIsRecorded; - 调用
AudioDeviceBuffer::SetRecordedBuffer,其中会把采集到的数据拷贝到rec_buffer_中; - 调用
AudioDeviceBuffer::DeliverRecordedData,接下来就是对数据的编码、发送了:
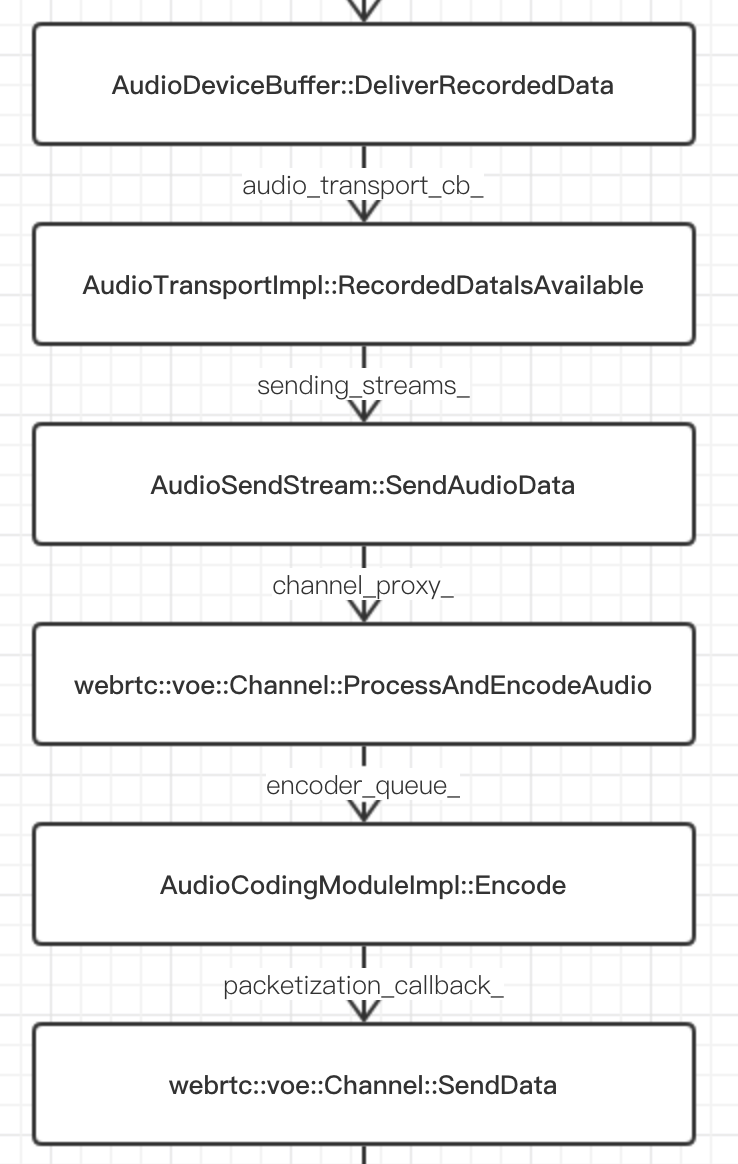
注:WebRTC Android JNI 接口的 C 层函数定义,都不是手写的,而是用 Python 脚本生成的,生成的代码在 out/debug/gen/sdk/android/generated_xxx_jni/jni 目录中,其内则是调用 sdk/android/src/jni 目录下的 XXXJni 类。
音频播放
和音频采集类似,native 的代码都会调用到 Java 的 WebRtcAudioTrack 类,而且这个类也有新老两个版本,我们只关注 audio 包下的新版本。
WebRTC 的音频播放利用 Android 系统的 AudioTrack 类实现,这里我也只强调有意思的要点:
- WebRTC 全局只会使用一个 AudioTrack 对象,无论是一个 PC 多路流,还是多个 PC,多路流的音频数据会在 AudioMixer 里混好音,然后用这个 AudioTrack 对象进行播放;
- 和采集类似,播放端也会在
initPlayout里缓存 direct byte buffer 的 native 地址; - 构造 AudioTrack 对象时,也会捕获
IllegalArgumentException,构造完毕后,也会验证其处于STATE_INITIALIZED状态; - 在
startPlayout里调用audioTrack.play时也会捕获IllegalStateException,之后也会验证其处于PLAYSTATE_PLAYING状态; - 向 AudioTrack 写数据是在一个单独的线程里,它也会调用
Process.setThreadPriority(Process.THREAD_PRIORITY_URGENT_AUDIO)提高线程优先级; - 如果
audioTrack.write返回的写入数据大小不等于欲写数据大小,那也不会重试写未被写入的数据,但若返回了错误,那就会停止播放、报告错误;
数据传递:
- Java 层的播放线程不停地调用 native 接口获取待播放的数据,执行到
AudioTrackJni::GetPlayoutData; - 调用
AudioDeviceBuffer::RequestPlayoutData,其中会向 audio transport 索要已解码的音频数据,其调用栈为:
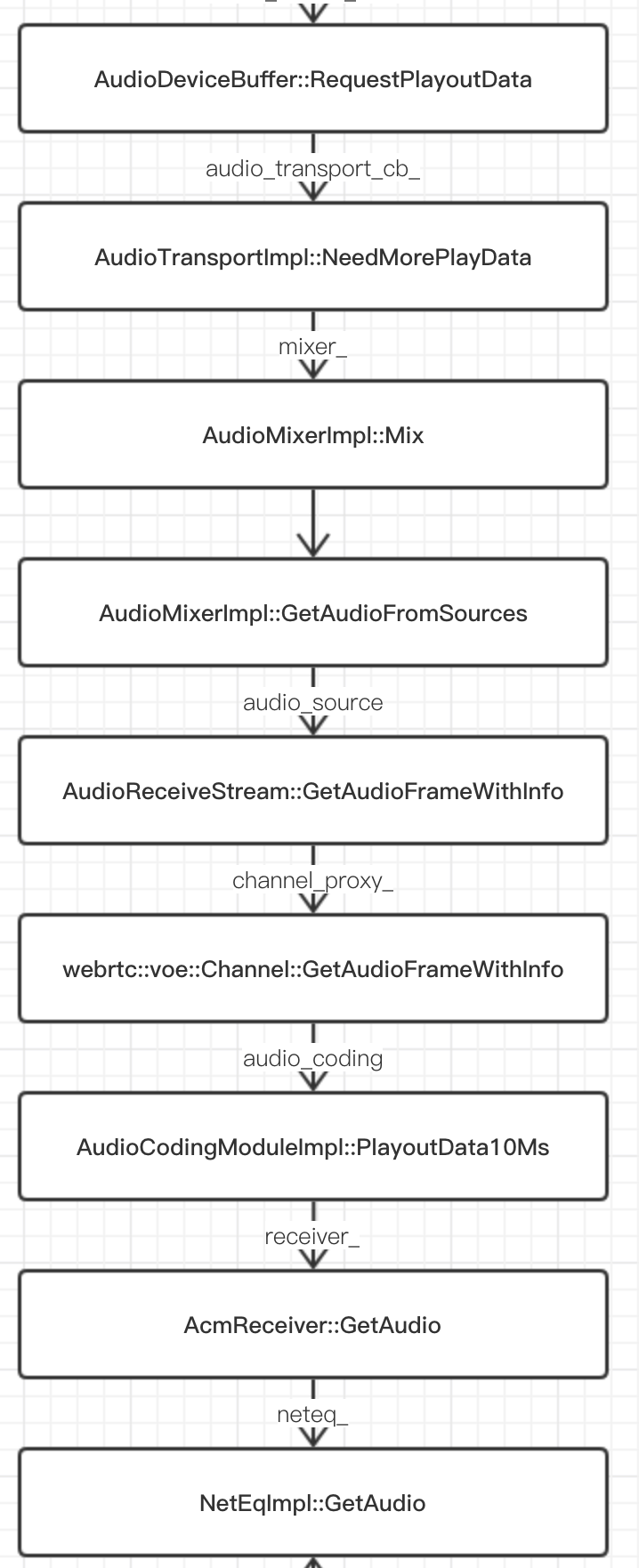
- AudioMixer 前面已经分析过了,NetEq 这次我们先不展开,就认为它是一个音频数据的队列即可;
- 之后 AudioTrackJni 会调用
AudioDeviceBuffer::GetPlayoutData,把已解码的音频数据拷贝到 direct byte buffer 中; - Java 层采集线程拿到音频数据,写入 AudioTrack 播放;
AEC
如果系统硬件支持 AEC,则 WebRTC 会禁用软件实现的 AEC,这一逻辑实现在 WebRtcVoiceEngine::ApplyOptions 中。
查询逻辑实现在 WebRtcAudioEffects#isAcousticEchoCancelerSupported 里,通过对比 AudioEffect.queryEffects 返回的 Descriptor 实现:类型为 AudioEffect.EFFECT_TYPE_AEC,但 uuid 不是 AOSP 软件实现的 uuid。
启用硬件 AEC 时,会调用 ADM 的接口,进而调用到 WebRtcAudioRecord#enableBuiltInAEC,但其中只是记下一个标记,实际启用则是在 WebRtcAudioRecord#initRecording 中触发,构造好 AudioRecord 后,拿着它的 session id,去启用 AEC(和下面要讲的 NS)。
NS
NS 和 AEC 类似,如果系统硬件支持 NS,则禁用 WebRTC 软件实现的 NS。
iOS ADM
iOS 的 ADM 实现类在 sdk/objc/native/src/audio/audio_device_module_ios.mm 中,而它则把所有的接口调用都转发给了同目录下的 audio_device_ios.mm 中,所以干活的都是 AudioDeviceIOS 类。
而 AudioDeviceIOS 则是把工作分派给了 VoiceProcessingAudioUnit 和 FineAudioBuffer,前者是对 AudioUnit 的封装,后者则是对数据长度处理逻辑的封装,因为 iOS 系统采集和播放的数据单位长度和 WebRTC 内部处理的长度可能不一致,所以需要对数据做缓冲处理。
音频采集
WebRTC iOS 的音频采集通过 AudioUnit 实现,而对 AudioUnit 的使用,则封装在 VoiceProcessingAudioUnit 类中,具体代码这里就不贴了,另外我对 AudioUnit 也不是很熟悉,也就不像安卓那样做「看点分析」了 :)
只有一点比较特殊的是,WebRTC 禁用了 AudioUnit 为采集数据的 buffer 分配,而是自己管理 buffer,在收到 AudioUnit 的回调之后,再手动调用 AudioUnitRender 把采集到的数据取出来。
这里我们看看音频采集的数据传递过程:
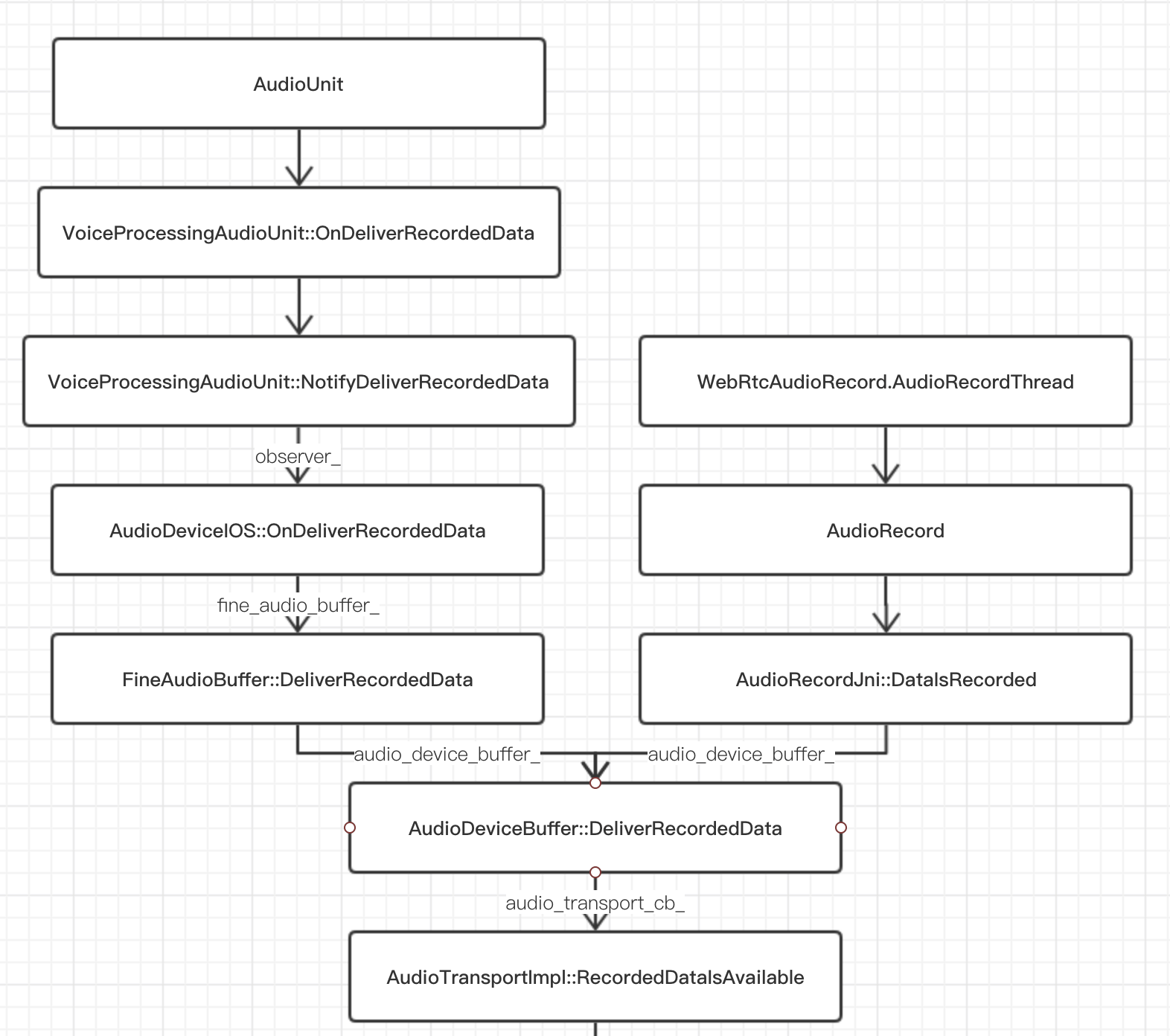
数据到达 AudioDeviceBuffer 类之后,就和安卓殊途同归了。
音频播放
音频播放这边我们也只是看一下数据传递流程:
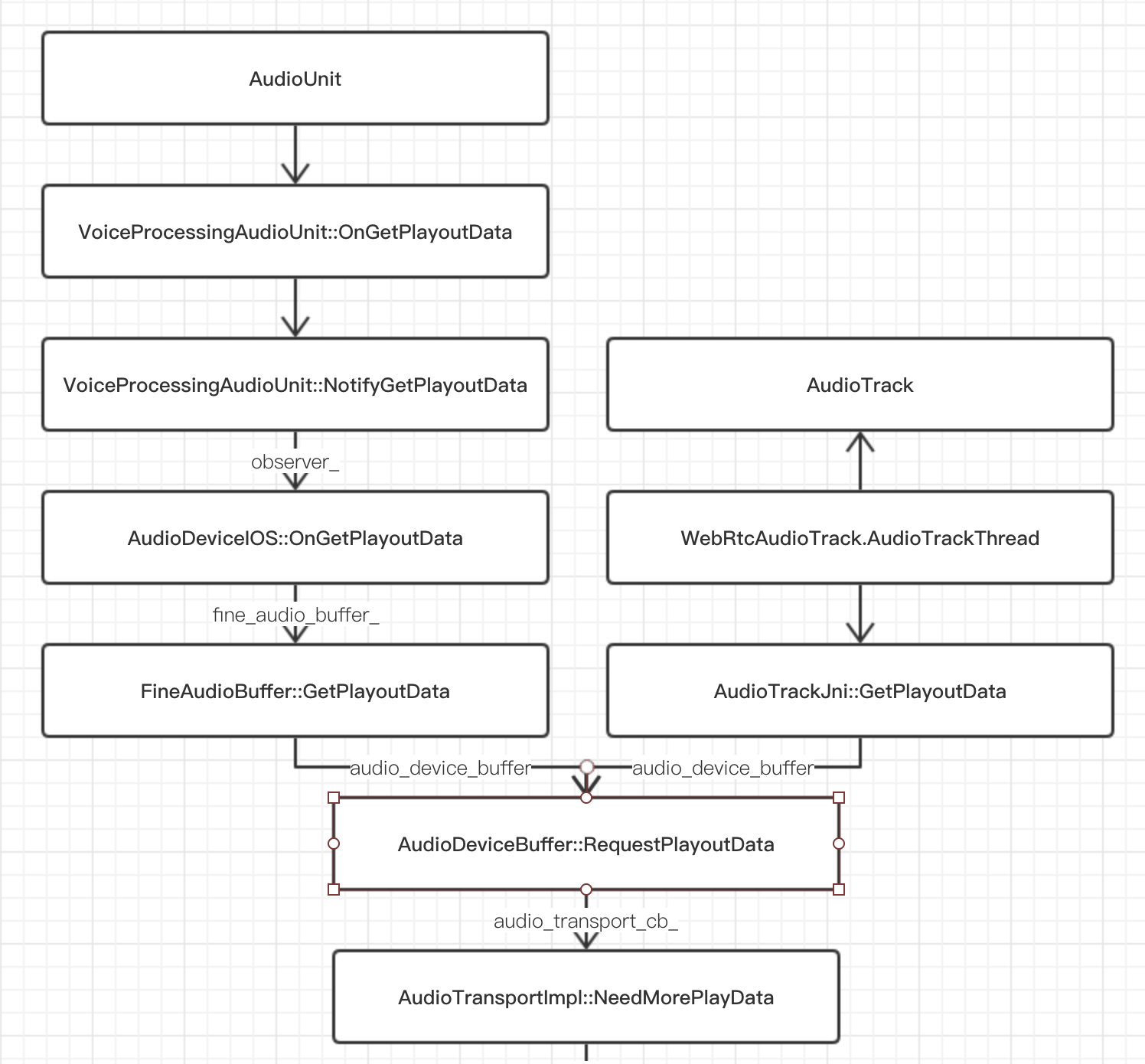
和采集一样,一直到 AudioDeviceBuffer 类,Android 和 iOS 的逻辑都是一样的,只不过 iOS 是系统自己有单独的 IO 线程,无需像 Android 那样自己维护单独的线程。
AEC
WebRTC iOS 并未实现开关 AEC 的逻辑,但是提供了一个 ios_force_software_aec_HACK 选项,用以在硬件 AEC 不生效的机器上强制开启软件 AEC 实现,但这种做法的具体表现如何,WebRTC 也是持观望态度。
整体上来讲,iOS 的 AEC 效果比 Android 还是好很多的,它的开启是通过设置 AudioUnit 的 componentSubType 为 kAudioUnitSubType_VoiceProcessingIO 实现的,设置这个 sub type 后,会启用系统的 AEC, AGC, NS 等。
NS
iOS 的 NS 完全依赖系统的实现,没有实现任何开关、查询的逻辑。
声音路由
WebRTC Android 和 iOS 声音路由相关的逻辑没有封装到 SDK 里,而是在 demo 项目中,声音路由主要是指控制声音从哪里播放出来(听筒/扬声器)、音量调节是否生效。
Android
Android 的声音路由可以通过调用 AudioManager 的接口实现,WebRTC 在 demo 的代码里对其进行了一点封装,包括监听音频设备的变化、声音路由的切换与恢复等,在 AppRTCAudioManager 类里。
WebRTC 对 AudioManager 的主要调用代码如下:
audioManager.setMode(AudioManager.MODE_IN_COMMUNICATION);
audioManager.setSpeakerphoneOn(on);
首先 AudioRecord 使用 VOICE_COMMUNICATION、AudioTrack 使用 STREAM_VOICE_CALL,才能实现 AEC 等效果,而此时只有调节通话音量才能正确调节 AudioTrack 的音量大小,AudioManager 设置为 MODE_IN_COMMUNICATION 模式就是为了让按音量调节键能调节通话音量。setSpeakerphoneOn 则是控制声音是从扬声器播放,还是从听筒播放。
iOS
iOS 可以在 ADM Init(创建 PC factory)之前通过 RTCAudioSessionConfiguration setWebRTCConfiguration 设置音频相关配置:
- category: AVFoundation 定义的 category,包括
AVAudioSessionCategoryPlayback,AVAudioSessionCategoryRecord,AVAudioSessionCategoryPlayAndRecord,AVAudioSessionCategoryMultiRoute等; - categoryOptions: AVFoundation 定义的 AVAudioSessionCategoryOptions,包括
AVAudioSessionCategoryOptionMixWithOthers,AVAudioSessionCategoryOptionDuckOthers,AVAudioSessionCategoryOptionDefaultToSpeaker等; - mode: AVFoundation 定义的 mode,包括
AVAudioSessionModeVoiceChat,AVAudioSessionModeVideoRecording,AVAudioSessionModeMoviePlayback,AVAudioSessionModeVideoChat等; - sampleRate: 采样率;
- ioBufferDuration: 音频 IO 的单位数据长度;
- inputNumberOfChannels: 采集声道数;
- outputNumberOfChannels: 播放声道数;
通话期间则可以通过如下代码实现配置的变更:
RTCAudioSessionConfiguration* configuration =
[RTCAudioSessionConfiguration webRTCConfiguration];
// change config
RTCAudioSession* session = [RTCAudioSession sharedInstance];
[session lockForConfiguration];
NSError* error = nil;
BOOL hasSucceeded =
[session setConfiguration:configuration active:YES error:&error];
if (!hasSucceeded) {
// error
}
[session unlockForConfiguration];
另外,如需切换听筒(receiver, earpiece)与扬声器(speaker),可以在上述代码之后调用:
AVAudioSession* sysSession = [AVAudioSession sharedInstance];
if (speakerOn) {
[sysSession overrideOutputAudioPort:AVAudioSessionPortOverrideSpeaker
error:&error];
} else {
[sysSession overrideOutputAudioPort:AVAudioSessionPortOverrideNone
error:&error];
}
因为 WebRTC 默认使用的 category 是 AVAudioSessionCategoryPlayAndRecord,此 category 默认是把声音从听筒播放的,因此 AVAudioSessionPortOverrideSpeaker 就可以使声音从扬声器播放,AVAudioSessionPortOverrideNone 就可以使声音恢复从听筒播放。
总结
好了,WebRTC ADM 的分析我们就进行到这里,这部分代码其实也是相对独立的,稍作裁剪就能摘出来直接使用,至于如何摘出 WebRTC 相关的 C++ 代码文件,可以看看我写的一个小脚本。
本文是 Piasy 原创,请阅读原文 https://blog.piasy.com/2018/09/14/WebRTC-ADM/
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
