
本文介绍WebRTC的单通道降噪方法,其核心是维纳滤波器。WebRTC ANR具体细节需要有一定的噪声估计基础才能理解,因此这里只介绍整体流程。
I. 维纳滤波器(Wiener Filter)
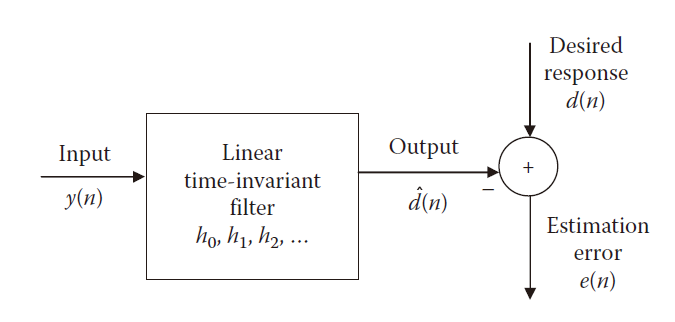

维纳滤波器的结构如上图所示,输入信号经过一个线性时不变的系统产生一个输出信号,其输出可以表示为

维纳滤波器的目的是使得输出信号与期望信号d(n)尽可能的相近,而这可以通过最小化预测误差e(n)来实现。维纳滤波器可以在时域实现也可以在频域实现,语音信号处理一般在频域进行,因此下面介绍其在频域的实现方法。我们将公式(1)改为使用成双边无限长滤波器形式,即
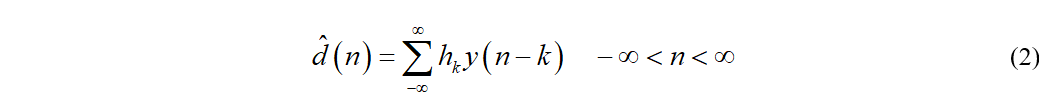
接着我们把上式写成卷积的形式
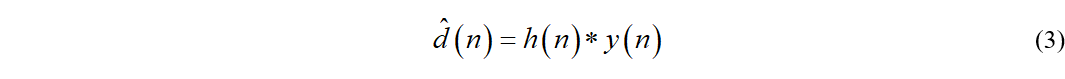
然后转化到频域,时域的卷积等于频域的乘积,即
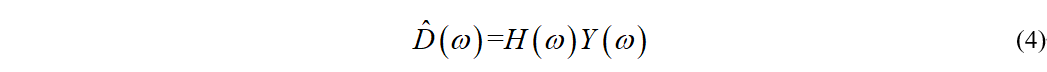
此时,期望信号与滤波器的输出的误差为
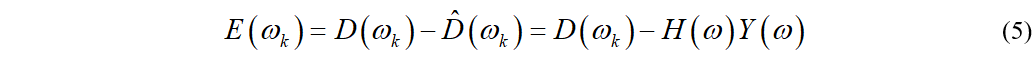
为了求解滤波器的系数,我们需要计算均方误差,即
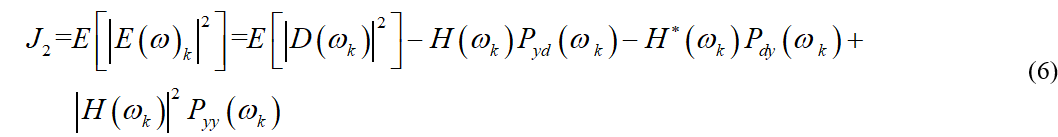 其中
其中
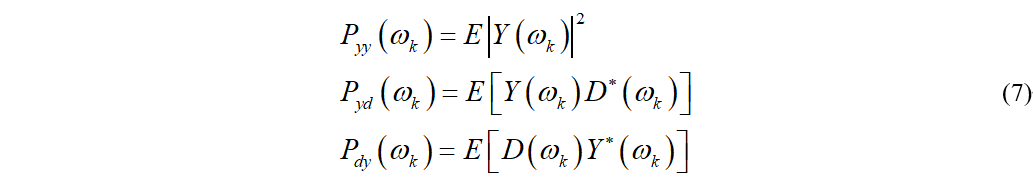
计算均方误差对H(ωk)求复导数并令其等于0有
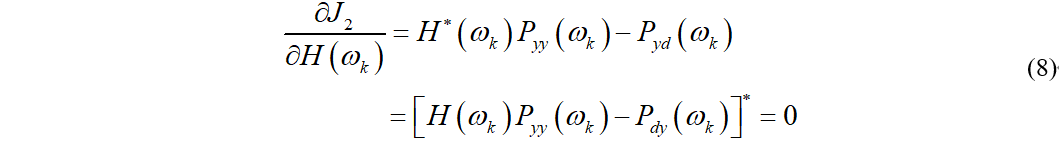
解得
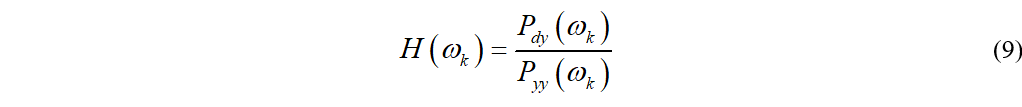
WebRTC的NS大致流程为通过计算先验和后验SNR来估计每个频段噪声存在的概率,然后对噪声估计进行更新,得到噪声谱后更新维纳滤波器的系数与输入信号结合输出干净的信号。下面详细介绍每个步骤。
II. 初始化 Initialize
WebRTC NS初始化的东西比较多,按函数顺序来。
int WebRtcNs_InitCore(NoiseSuppressionC* self, uint32_t fs)当信号是8kHz时每一帧是80个采样点,并计算128点的FFT,当信号是16/32/48kHz时每一帧是160个采样点,并计算256点的FFT,即NS算法只支持每次处理10ms的语音数据。然后设置了一堆参数,这里说下分位数这个参数,WebRTC跟踪噪声并不是使用最小值(MCRA)跟踪而是使用分位数跟踪噪声谱。
static void set_feature_extraction_parameters(NoiseSuppressionC* self)这里设定了对语音/噪声分类使用的特征包括LRT(Likelihood Ratio Test)均值特征、频谱平坦度和频谱差异度。
int WebRtcNs_set_policy_core(NoiseSuppressionC* self, int mode)这里设定了NS算法的噪声抑制等级,不同的等级设定了不同的参数,总共有四个等级,这四个等级对应不同的抑制强度。到这里WebRTC NS的初始化就结束了。
III. Analyze
在对语音信号正式处理之前有一个分析的过程,主要是一些准备工作。
void WebRtcNs_AnalyzeCore(NoiseSuppressionC* self, const float* speechFrame) 首先通过UpdateBuffer函数把就的数据丢掉,然后把新的数据加入analysis buffer中:
static void UpdateBuffer(const int16_t *frame,
size_t frame_length,
size_t buffer_length,
float *buffer) 接着计算analysis buffer中的时域能量,如果当前能量为0,那么直接什么都不做跳出WebRtcNs_AnalyzeCore。
static float WindowingEnergy(const float *window,
const float *data,
size_t length,
float *data_windowed)算完能量后对analysis buffer进行256点的FFT运算,并且还要计算能量谱、幅度谱、对数能量谱和对数幅度谱。
static void FFT(NoiseSuppressionC *self,
float *time_data,
size_t time_data_length,
size_t magnitude_length,
float *real,
float *imag,
float *magn, float *lmagn, int prev_calc, float *signalEnergy, float *sumMagn)通过上面计算的一系列值进行噪声谱估计,这里使用的是分位数估计方法,其实和最小值估计原理差不多(时域平滑、频域平滑、分位数跟踪、噪声更新),这里用对数幅度谱进行噪声估计。
static void NoiseEstimation(NoiseSuppressionC *self,
float *lmagn,
float *noise)值得注意的是,如果在初始阶段(前50帧),会直接使用一个简单的白噪声和粉红噪声模型来生成噪声。
接下来计算每个频点的先验和后验SNR,所谓先验SNR是纯净信号功率谱i与噪声功率谱的比值,而后验SNR是带噪信号功率谱与噪声功率谱的比值,但是WebRTC这里使用幅度谱减少计算量。但是实际情况下我们没有办法获得纯净的信号,因此使用上一帧估计的先验SNR和瞬时SNR进行平滑的结果作为先验SNR,下面是完整代码。
static void ComputeSnr(const NoiseSuppressionC *self,
const float *magn,
const float *noise,
float *snrLocPrior, float *logSnrLocPrior,
float *snrLocPost) {
size_t i;
for (i = 0; i < self->magnLen; i++) {
// Previous post SNR.
// Previous estimate: based on previous frame with gain filter.
float previousEstimateStsa = (self->magnPrevAnalyze[i] * self->smooth[i]) / (self->noisePrev[i] + epsilon);
// Post SNR.
snrLocPost[i] = 0.f;
if (magn[i] > noise[i]) {
snrLocPost[i] = (magn[i] - noise[i]) / (noise[i] + epsilon);
}
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of snrPrior.
snrLocPrior[i] = 2.f * (
DD_PR_SNR * previousEstimateStsa + (1.f - DD_PR_SNR) * snrLocPost[i]);
logSnrLocPrior[i] = log1pf(snrLocPrior[i]);
} // End of loop over frequencies.
}算完各种SNR后,更新LRT均值特征、频谱平坦度和频谱差异度这三个特征。
static void FeatureUpdate(NoiseSuppressionC *self,
const float *magn, const float *lmagn,
int updateParsFlag)接下来是语音/噪声存在概率,不过使用了更为复杂的特征。
static void SpeechNoiseProb(NoiseSuppressionC *self,
float *probSpeechFinal,
const float *snrLocPrior, const float *logSnrLocPrior,
const float *snrLocPost)最后我们更新噪声谱。
static void UpdateNoiseEstimate(NoiseSuppressionC *self,
const float *magn,
float *noise)IV. Process
计算完我们需要的各种参数之后,我们就可以对语音信号进行降噪处理了。首先还是更新buffer和计算能量,然后进行FFT运算(我个人认为Analyze函数应该放在Process函数里面的)。
static void UpdateBuffer(const int16_t *frame,
size_t frame_length,
size_t buffer_length,
float *buffer)
static float WindowingEnergy(const float *window,
const float *data,
size_t length,
float *data_windowed)接下来就是维纳滤波计算,其中overdrive控制了降噪的强度,这里theFilter是频率响应并不是滤波后的值。
static void ComputeDdBasedWienerFilter(const NoiseSuppressionC *self,
const float *magn,
float *theFilter) {
size_t i;
float snrPrior, previousEstimateStsa, currentEstimateStsa;
for (i = 0; i < self->magnLen; i++) {
// Previous estimate: based on previous frame with gain filter.
previousEstimateStsa = self->magnPrevProcess[i] * self->smooth[i] / (self->noisePrev[i] + epsilon);
// Post and prior SNR.
currentEstimateStsa = 0.f;
if (magn[i] > self->noise[i]) {
currentEstimateStsa = (magn[i] - self->noise[i]) / (self->noise[i] + epsilon);
}
// DD estimate is sum of two terms: current estimate and previous estimate.
// Directed decision update of |snrPrior|.
snrPrior = DD_PR_SNR * previousEstimateStsa +
(1.f - DD_PR_SNR) * currentEstimateStsa;
// Gain filter.
theFilter[i] = snrPrior / (self->overdrive + snrPrior);
} // End of loop over frequencies.
}然后根据一些判定条件修正theFilter的值,修正后的theFilter与当前帧的实部和虚部相乘,得到滤波后的结果。
self->smooth[i] = theFilter[i];
real[i] *= self->smooth[i];
imag[i] *= self->smooth[i];接着进行IFFT运算,获得时域结果。
static void IFFT(NoiseSuppressionC *self,
const float *real,
const float *imag,
size_t magnitude_length,
size_t time_data_length,
float *time_data) 接下来会进行overlap-and-add以及其他操作,一帧信号处理的整个流程就结束了。
最后看下降噪后的效果吧。
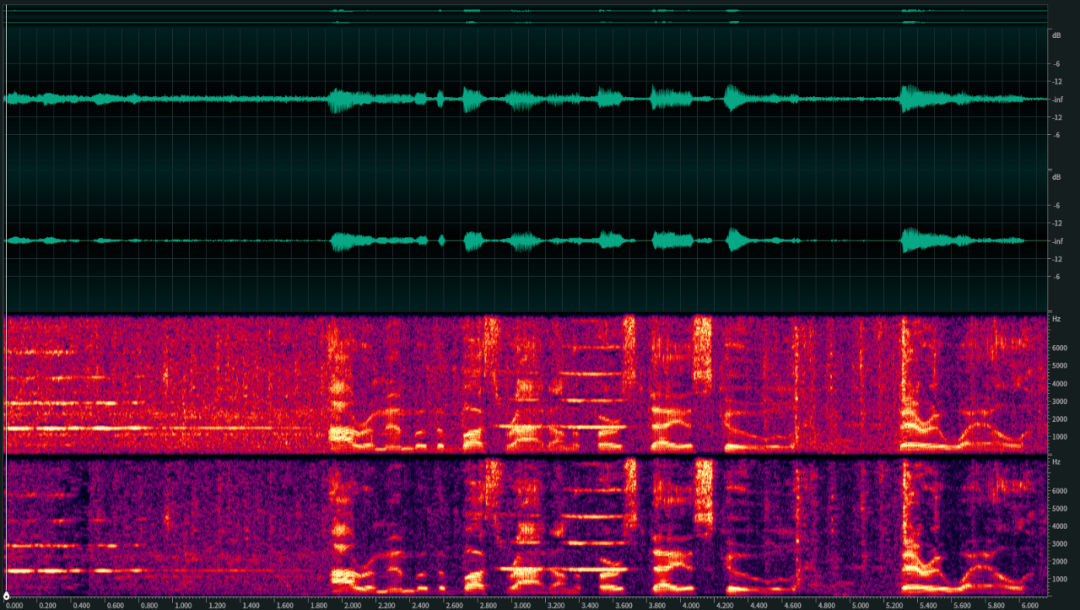
V. Conclusion
过去10年WebRTC ANR的效果还是不错的,其中很多工程化技巧也值得我们去研究。但是随着深度学习时代的来临,人们越来越渴望对非平稳噪声进行抑制,而基于噪声谱估计的算法需要较长的时间获得噪声特性,这种方法似乎对非平稳噪声无能为力。但是基于数据驱动的方法总会遇到与训练数据分布不匹配的情况,这时候信号处理算法的鲁棒性就体现出来了。因此,语音降噪何去何从,诸君将一同见证。
参考文献:
[1]. 实时语音处理实践指南
[2]. Speech Enhancement Theory and Practice
[3]. https://blog.csdn.net/golfbears/article/details/91882680
作者:Ryuk | 来源:公众号——语音算法组
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。