
最近在实现一个功能的时候,用到了webrtc模块的vad部分的python版本,因参考的原博客找不到链接了,为了方便自己以后查阅相关内容,故整理成博客供日后方便。接下来开始正题,当然了,要想使用这个webrtcvad,自然就是安装它了,命令也很简单。
pip install webrtcvad
关于该包的使用,github上有提供一个example.py,可以参照该example.py文件使用webrtcvad。网址为https://github.com/wiseman/py-webrtcvad/blob/master/example.py。不过该代码运行的结果是切分后的片段。接下来整理的是将vad后的片段整个保存。下面是整个代码,相关参数的含义可以查看webrtcvad的文档。
import contextlib
import wave
import webrtcvad
import os
import sys
import collections
MODE = 3
def read_wave(path):
"""Reads a .wav file.
Takes the path, and returns (PCM audio data, sample rate).
"""
with contextlib.closing(wave.open(path, 'rb')) as wf:
num_channels = wf.getnchannels()
assert num_channels == 1
sample_width = wf.getsampwidth()
assert sample_width == 2
sample_rate = wf.getframerate()
assert sample_rate in (8000, 16000, 32000, 48000)
pcm_data = wf.readframes(wf.getnframes())
return pcm_data, sample_rate
def write_wave(path, audio, sample_rate):
"""Writes a .wav file.
Takes path, PCM audio data, and sample rate.
"""
with contextlib.closing(wave.open(path, 'wb')) as wf:
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(sample_rate)
wf.writeframes(audio)
class Frame(object):
"""Represents a "frame" of audio data."""
def __init__(self, bytes, timestamp, duration):
self.bytes = bytes
self.timestamp = timestamp
self.duration = duration
def frame_generator(frame_duration_ms, audio, sample_rate):
"""Generates audio frames from PCM audio data.
Takes the desired frame duration in milliseconds, the PCM data, and
the sample rate.
Yields Frames of the requested duration.
"""
n = int(sample_rate * (frame_duration_ms / 1000.0) * 2)
offset = 0
timestamp = 0.0
duration = (float(n) / sample_rate) / 2.0
while offset + n < len(audio):
yield Frame(audio[offset:offset + n], timestamp, duration)
timestamp += duration
offset += n
def vad_collector(sample_rate, vad, frames):
voiced_frames = []
for idx, frame in enumerate(frames):
is_speech = vad.is_speech(frame.bytes, sample_rate)
if is_speech:
voiced_frames.append(frame)
return b''.join(f.bytes for f in voiced_frames)
def voiced_frames_expand(voiced_frames, duration=2):
total = duration * 16000
expand_voiced_frames = voiced_frames
while len(expand_voiced_frames) < total:
expand_num = total - len(expand_voiced_frames)
expand_voiced_frames += voiced_frames[: expand_num]
return expand_voiced_frames
def filter(wavpath, out_dir, expand=False):
audio, sample_rate = read_wave(wavpath)
vad = webrtcvad.Vad(MODE)
frames = frame_generator(30, audio, sample_rate)
frames = list(frames)
voiced_frames = vad_collector(sample_rate, vad, frames)
voiced_frames = voiced_frames_expand(voiced_frames, 2)
wav_name = wavpath.split('\')[-1]
save_path = out_dir + '\' +"mo"+wav_name
write_wave(save_path, voiced_frames, sample_rate)
if __name__ == "__main__":
in_wave = 'C:\Users\ctw\code\DiveintoDeep\1B356F62.wav'
outwav='C:\Users\ctw\code\DiveintoDeep\'
filter(in_wave, outwav, expand=False)上面代码是在windows平台上运行的,如果在linux下运行,则相应的文件路径需要改变,且函数filter中的wav_name和save_path里的\要修改成/
下面来看看效果,原语音的波形如下

去除vad后的波形如下,效果还是可以的。
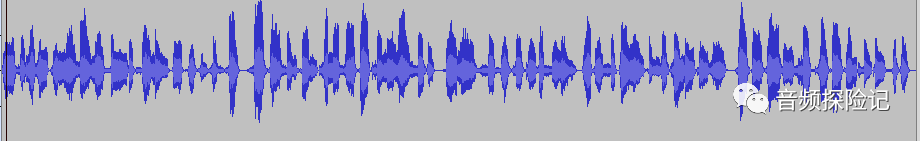
作者:TingweiSpeak | 来源:公众号——音频探险记,转载请注明
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
