
在之前的文章中介绍了webrtc在windows下使用vs2019进行完整编译的过程,整个webrtc工程包含了非常多的模块,调试音频处理模块也是非常的不方便。Github上有很多大佬对webrtc中的音频处理模块进行了抽取,因开发环境的差异,有些代码编译不通,有些代码的效果正确性无法保证,还是比较影响学习积极性的。所以花了点时间对webrtc中的音频处理模块(Audio Processing Module, APM)进行了抽取并测试了AGC, ANS, AEC等功能,特此记录一下。之所以对APM模块进行抽取是因为webrtc中的很多模块没有提供相应模块对应的demo,对于像我这样的渣渣初学者,模块学习起来非常困难。而APM模块中包含了整个音频处理模块的调用逻辑,通过调试APM模块可以很方便的进行APM的学习。
说明:
- 开发环境:Ubuntu,
- IDE:Clion
- 代码:基于之前介绍的AGC2代码:https://github.com/ctwgL/webrtc_agc2
Audio Processing Module
在audio_processing.h头文件中定义了相应的音频处理模块,要想开启相应的模块功能,只需要将各个模块对应的enabled设置为true即可。各个模块的定义如下(就这些模块,不知道得研究多久.
struct PreAmplifier {
bool enabled = false;
float fixed_gain_factor = 1.f;
} pre_amplifier;
struct HighPassFilter {
bool enabled = false;
bool apply_in_full_band = true;
} high_pass_filter;
struct EchoCanceller {
bool enabled = false;
bool mobile_mode = false;
bool export_linear_aec_output = false;
// Enforce the highpass filter to be on (has no effect for the mobile
// mode).
bool enforce_high_pass_filtering = true;
} echo_canceller;
struct NoiseSuppression {
bool enabled = false;
enum Level { kLow, kModerate, kHigh, kVeryHigh };
Level level = kModerate;
bool analyze_linear_aec_output_when_available = false;
} noise_suppression;
struct TransientSuppression {
bool enabled = false;
} transient_suppression;
struct VoiceDetection {
bool enabled = false;
} voice_detection;
struct GainController1 {
bool enabled = false;
enum Mode {
// Adaptive mode intended for use if an analog volume control is
// available on the capture device. It will require the user to provide
// coupling between the OS mixer controls and AGC through the
// stream_analog_level() functions.
// It consists of an analog gain prescription for the audio device and a
// digital compression stage.
kAdaptiveAnalog,
// Adaptive mode intended for situations in which an analog volume
// control is unavailable. It operates in a similar fashion to the
// adaptive analog mode, but with scaling instead applied in the digital
// domain. As with the analog mode, it additionally uses a digital
// compression stage.
kAdaptiveDigital,
// Fixed mode which enables only the digital compression stage also used
// by the two adaptive modes.
// It is distinguished from the adaptive modes by considering only a
// short time-window of the input signal. It applies a fixed gain
// through most of the input level range, and compresses (gradually
// reduces gain with increasing level) the input signal at higher
// levels. This mode is preferred on embedded devices where the capture
// signal level is predictable, so that a known gain can be applied.
kFixedDigital
};
Mode mode = kAdaptiveAnalog;
// Sets the target peak level (or envelope) of the AGC in dBFs (decibels
// from digital full-scale). The convention is to use positive values. For
// instance, passing in a value of 3 corresponds to -3 dBFs, or a target
// level 3 dB below full-scale. Limited to [0, 31].
int target_level_dbfs = 3;
// Sets the maximum gain the digital compression stage may apply, in dB. A
// higher number corresponds to greater compression, while a value of 0
// will leave the signal uncompressed. Limited to [0, 90].
// For updates after APM setup, use a RuntimeSetting instead.
int compression_gain_db = 9;
// When enabled, the compression stage will hard limit the signal to the
// target level. Otherwise, the signal will be compressed but not limited
// above the target level.
bool enable_limiter = true;
// Sets the minimum and maximum analog levels of the audio capture device.
// Must be set if an analog mode is used. Limited to [0, 65535].
int analog_level_minimum = 0;
int analog_level_maximum = 255;
// Enables the analog gain controller functionality.
struct AnalogGainController {
bool enabled = true;
int startup_min_volume = kAgcStartupMinVolume;
// Lowest analog microphone level that will be applied in response to
// clipping.
int clipped_level_min = kClippedLevelMin;
bool enable_agc2_level_estimator = false;
bool enable_digital_adaptive = true;
} analog_gain_controller;
} gain_controller1;
// Enables the next generation AGC functionality. This feature replaces the
// standard methods of gain control in the previous AGC. Enabling this
// submodule enables an adaptive digital AGC followed by a limiter. By
// setting |fixed_gain_db|, the limiter can be turned into a compressor that
// first applies a fixed gain. The adaptive digital AGC can be turned off by
// setting |adaptive_digital_mode=false|.
struct GainController2 {
enum LevelEstimator { kRms, kPeak };
bool enabled = false;
struct {
float gain_db = 0.f;
} fixed_digital;
struct {
bool enabled = false;
float vad_probability_attack = 1.f;
LevelEstimator level_estimator = kRms;
int level_estimator_adjacent_speech_frames_threshold = 1;
// TODO(crbug.com/webrtc/7494): Remove `use_saturation_protector`.
bool use_saturation_protector = true;
float initial_saturation_margin_db = 20.f;
float extra_saturation_margin_db = 2.f;
int gain_applier_adjacent_speech_frames_threshold = 1;
} adaptive_digital;
} gain_controller2;
struct ResidualEchoDetector {
bool enabled = true;
} residual_echo_detector;
// Enables reporting of |output_rms_dbfs| in webrtc::AudioProcessingStats.
struct LevelEstimation {
bool enabled = false;
} level_estimation;而使用APM的整体逻辑还是很清晰的。
AudioProcessing* apm = AudioProcessingBuilder().Create();//创建APM
AudioProcessing::Config config;//创建Config对象
//回声消除模块开关
config.echo_canceller.enabled = true;
//噪声抑制模块开关
config.noise_suppression.enabled = true;
//设置噪声抑制开关
config.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kVeryHigh;
//增益控制模块1开关
config.gain_controller1.enabled = false;
//瞬态抑制模块开关
config.transient_suppression.enabled = false;
//增益控制模块2开关
config.gain_controller2.enabled = false;
// 高通滤波开关
config.high_pass_filter.enabled = false;
//VAD开关
config.voice_detection.enabled = false;
//应用Config
apm->ApplyConfig(config);
//然后调用apm->ProcessReverseStream()和apm->ProcessStream()进行语音处理。ANS
首先体验一下ANS功能,将噪声抑制模块开启并设置降噪等级,其他模块关闭。
config.noise_suppression.enabled = true;
config.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kVeryHigh;带噪语音如下
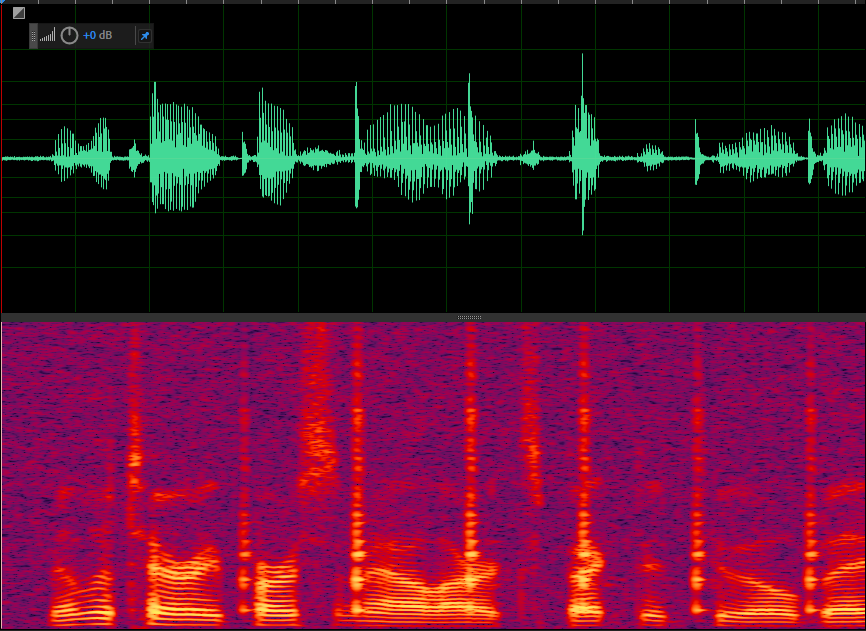
降噪后的语音
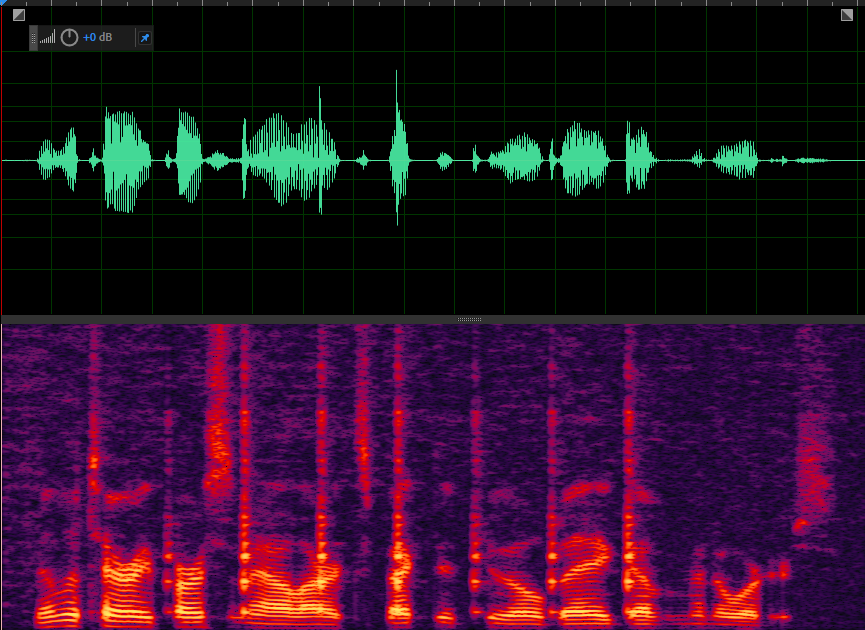
AGC
将AGC1模块开启并设置模式为自适应模式
config.gain_controller1.enabled = true;
config.gain_controller1.mode = AudioProcessing::Config::GainController1::kAdaptiveDigital;
config.gain_controller1.compression_gain_db = 3;
config.gain_controller1.target_level_dbfs = 1;原语音
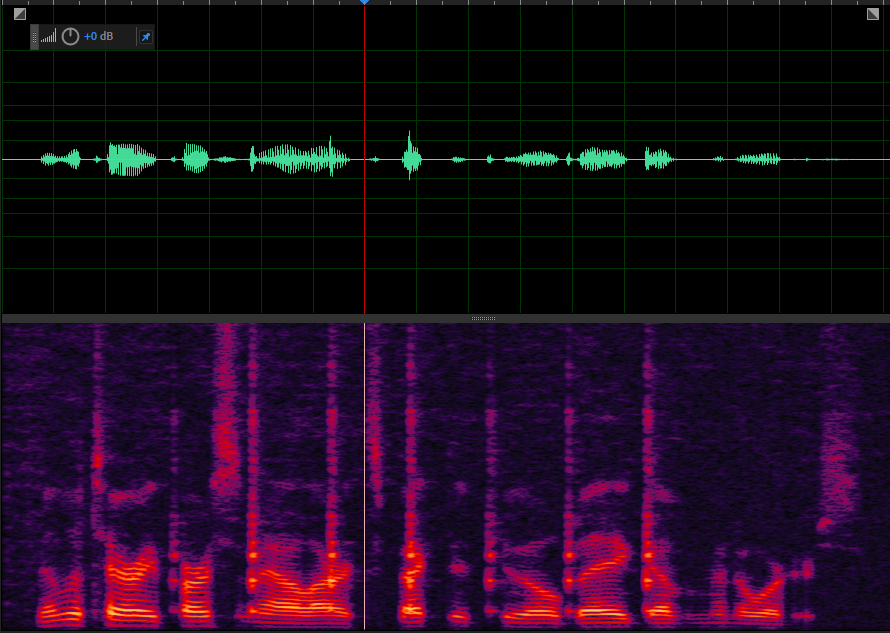
增益后的语音
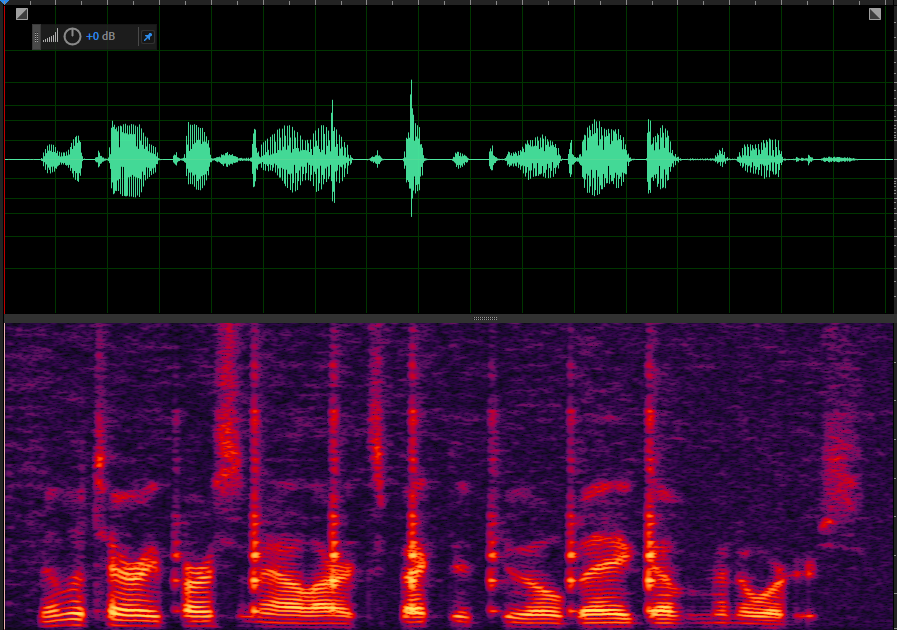
AEC
只需要打开回声消除开关即可。由于之前没有接触过回声消除相关的东西,就在网上找了一段近端信号,一段远端信号简单处理了一下。
config.echo_canceller.enabled = true;近端信号
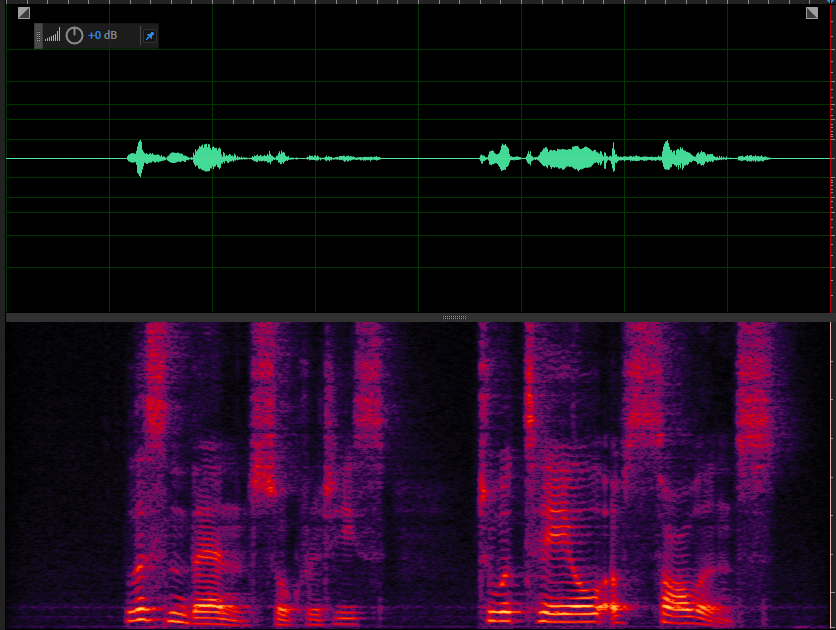
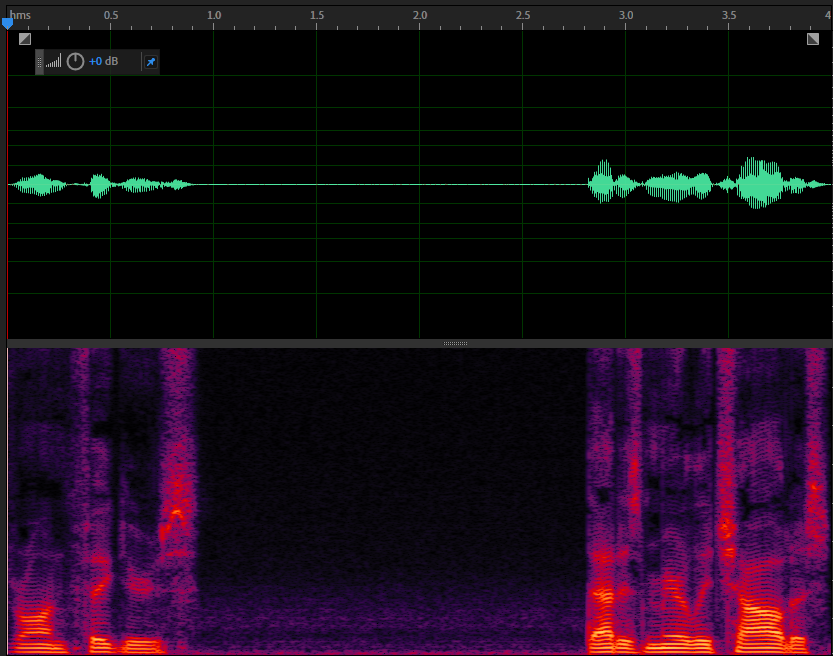
远端信号
处理后的语音
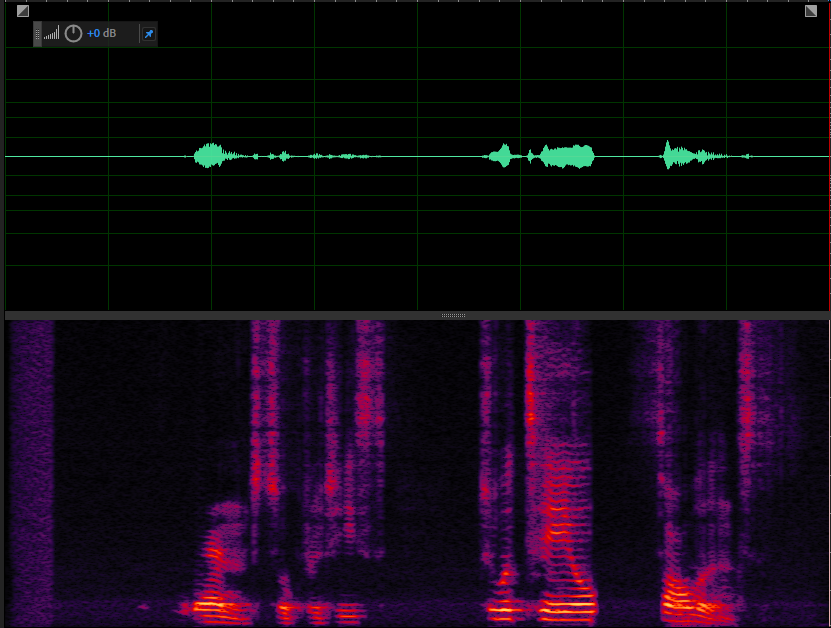
也不知道这个效果对不对,到时候找标哥大佬确认一下。暂时就测个3A的功能吧,VAD以及瞬态噪声抑制的功能等后续研究研究。整个APM处理代码main_apm.cc如下:
//
// Created by 11291 on 2022/5/10.
//
#include <iostream>
#include "api/audio/echo_canceller3_config.h"
#include "api/audio/echo_control.h"
#include "modules/audio_processing/include/audio_processing.h"
using namespace webrtc;
using namespace std;
int main(int argc, char* argv[])
{
printf("apm test");
FILE *fd_far = NULL;
FILE *fd_near = NULL;
FILE *fd_out = NULL;
constexpr int16_t kAudioLevel = 10000;
constexpr int kSampleRateHz = 16000;
constexpr int kNumChannels = 1;
fd_far = fopen(argv[1], "rb");
fd_near = fopen(argv[2], "rb");
fd_out = fopen(argv[3], "wb");
if (!fd_far || !fd_near || !fd_out)
{
cout << "fopen file fail!" << endl;
}
#if 1
int samples_per_frame = kSampleRateHz / 100;
int bits_per_sample = 16;
int bytes_per_frame = samples_per_frame * bits_per_sample / 8;
int NN = samples_per_frame ;
int delay_ms = 30;
int analog_level = 60;
cout << "samples_per_frame =" << samples_per_frame << endl;
cout << "bytes_per_frame =" << bytes_per_frame << endl;
cout << "delay_ms =" << delay_ms << endl;
int16_t *render_frame = (int16_t*)malloc(1024);
int16_t *render_frame_out = (int16_t*)malloc(1024);
int16_t *capture_frame = (int16_t*)malloc(1024);
int16_t *capture_frame_out = (int16_t*)malloc(1024);
webrtc::StreamConfig instreamConfig = webrtc::StreamConfig(kSampleRateHz, kNumChannels, false);
webrtc::StreamConfig outStreamConfig = webrtc::StreamConfig(kSampleRateHz, kNumChannels,false);
AudioProcessing* apm = AudioProcessingBuilder().Create();
AudioProcessing::Config config;
config.echo_canceller.enabled = true;
config.echo_canceller.mobile_mode = false;
config.noise_suppression.enabled = false;
config.noise_suppression.level = webrtc::AudioProcessing::Config::NoiseSuppression::kVeryHigh;
config.gain_controller1.enabled = false;
config.gain_controller1.mode = AudioProcessing::Config::GainController1::kAdaptiveDigital;
config.gain_controller1.compression_gain_db = 1;
config.gain_controller1.target_level_dbfs = 1;
config.transient_suppression.enabled = false;
config.gain_controller2.enabled = false;
config.high_pass_filter.enabled = false;
config.voice_detection.enabled = false;
apm->ApplyConfig(config);
while(1)
{
if (NN == fread(render_frame, sizeof(int16_t), NN, fd_far))
{
fread(capture_frame, sizeof(int16_t), NN, fd_near);
apm->ProcessReverseStream(render_frame, instreamConfig, outStreamConfig, NULL);
apm->ProcessStream(capture_frame, instreamConfig, outStreamConfig, capture_frame_out);
fwrite(capture_frame_out, sizeof(int16_t), NN, fd_out);
}else
{
cout << "read far file end NULL" << endl;
break;
}
}
delete apm;
free(capture_frame);
free(capture_frame_out);
free(render_frame);
free(render_frame_out);
fclose(fd_far);
fclose(fd_near);
fclose(fd_out);
#endif
return 0;
}总结
总的来说,webrtc对于音频处理从业者而言是一个大宝藏,无论是工程化还是算法都有很多值得借鉴学习的地方。后续将会持续研究webrtc的音频处理模块,大致的学习顺序应该是AGC1–>AGC2–>ANS–>VAD–>瞬态噪声抑制–>AEC。想要尝试一下APM的,可以从https://github.com/ctwgL/webrtc_agc2下载整个代码,下载完成后将其中的main.cc替换成上述的main_apm.cc,然后再进行编译即可。
作者: ctwgL | 来源:公众号——音频探险记
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
