
自动增益控制(Automatic gain control, AGC)是控制语音信号的增益稳定在指定水平的算法,可以避免语音忽大忽小引起的听觉不适。AGC作为音频3A算法之一,似乎并没有像ANR和AEC那样被较多的关注,但我个人觉得这是一个十分有趣的算法,因此在这里做一个流程解析。
1. WebRTC AGC简介
WebRTC的AGC算法有以下几个模式,顾名思义,第一个模式是什么都不改变,但是会作削顶保护,然后是模拟增益自适应和数字增益自适应以及固定数字增益。AGC算法每帧输入10ms的语音数据,这10ms数据又会被分为10个子帧。WebRTC的AGC使用纯定点化实现,因此运行速度很快,但是数值的具体含义要花很多时间才能知道是什么意思。
enum { kAgcModeUnchanged, kAgcModeAdaptiveAnalog, kAgcModeAdaptiveDigital, kAgcModeFixedDigital};2. Initialization
我们先看初始化部分,这里的minLevel和maxLevel分别是音量的最小值和最大值。
int WebRtcAgc_Init(void *agcInst, int32_t minLevel, int32_t maxLevel, int16_t agcMode, uint32_t fs)在初始化函数里首先会进行数字域的初始化,设定一些参数的初始值。
int32_t WebRtcAgc_InitDigital(DigitalAgc *stt, int16_t agcMode)值得注意的是,这里面也初始化了近端信号和远端信号的VAD,AGC的VAD是通过能量相关的阈值来判别语音信号的,有消息说最新版的WebRTCAGC采用RNN进行VAD判决,本人也在repo中看到了相关代码,但是具体细节还没来得及确认。
WebRtcAgc_InitVad(&stt->vadNearend); WebRtcAgc_InitVad(&stt->vadFarend);在初始化函数主体也会进行VAD的初始化,并且还会根据不同的模式对输入的minLevel和maxLevel进行缩放,如果选用kAgcModeAdaptiveDigital这个模式会自动设定为0和255,这里可以看出AGC算法能控制的增益范围是[0, 255]。
if (stt->agcMode == kAgcModeAdaptiveDigital) { minLevel = 0; maxLevel = 255; stt->scale = 0; }剩下的就是一些参数的初始化,参数的具体含义在agc.h这个头文件里面有详细的注释,这里就不多讲了。
3. Set
初始化之后,我们可以下一些参数来控制AGC算法的表现,这个结构体里面有三个参数,targetLevelDbfs就是目标电平了,compressionGaindB是压缩增益, limiterEnable是否使用limiter。
typedef struct { int16_t targetLevelDbfs; // default 3 (-3 dBOv) int16_t compressionGaindB; // default 9 dB uint8_t limiterEnable; // default kAgcTrue (on)} WebRtcAgcConfig;
int WebRtcAgc_set_config(void *agcInst, WebRtcAgcConfig agcConfig)接下来,我们看下set函数里面有些什么东西。首先是把config的参数赋给结构体,然后进行一些阈值的判断,这里我们可以发现targetLevelDbfs的范围是[0, 31]。
if ((agcConfig.targetLevelDbfs < 0) || (agcConfig.targetLevelDbfs > 31)) { stt->lastError = AGC_BAD_PARAMETER_ERROR; return -1; }如果我们使用kAgcModeFixedDigital,那么compressionGaindB的值会进行相应的调整。
if (stt->agcMode == kAgcModeFixedDigital) { /* Adjust for different parameter interpretation in FixedDigital mode */ stt->compressionGaindB += agcConfig.targetLevelDbfs; }然后我们会更新AGC的阈值。
void WebRtcAgc_UpdateAgcThresholds(LegacyAgc *stt)值得一提的是AGC的gain table也是在这里计算的
int32_t WebRtcAgc_CalculateGainTable(int32_t *gainTable, // Q16 int16_t digCompGaindB, // Q0 int16_t targetLevelDbfs, // Q0 uint8_t limiterEnable, int16_t analogTarget) // Q4. Process
现在到了究极复杂的处理阶段了。
int WebRtcAgc_Process(void *agcInst, const int16_t *const *in_near, size_t num_bands, size_t samples, int16_t *const *out, int32_t inMicLevel, int32_t *outMicLevel, int16_t echo, uint8_t *saturationWarning) 首先要对采样率进行判断,8000Hz采样点数为80,其他采样率采样点数为160。我们先看下数字AGC的流程(这个流程每次都会运行)。
int32_t WebRtcAgc_ProcessDigital(DigitalAgc *stt, const int16_t *const *in_near, size_t num_bands, int16_t *const *out, uint32_t FS, int16_t lowlevelSignal)首先根据采样率确定每毫秒有多少个采样点,然后对近端信号进行VAD判决,这里会有一个下采样到4kHz的过程,然后计算子带能量,然后通过短时和长时能量的均值和方差进行VAD判决。
int16_t WebRtcAgc_ProcessVad(AgcVad *state, // (i) VAD state const int16_t *in, // (i) Speech signal size_t nrSamples) // (i) number of samples然后会根据VAD的似然比和方差调整衰减因子。接下来计算每个子帧的包络,并计算每个子帧对应的增益。我们可以看到这里有一个快包络的跟踪和一个慢包络的跟踪。
for (k = 0; k < 10; k++) { // Fast envelope follower // decay time = -131000 / -1000 = 131 (ms) stt->capacitorFast = AGC_SCALEDIFF32(-1000, stt->capacitorFast, stt->capacitorFast); if (env[k] > stt->capacitorFast) { stt->capacitorFast = env[k]; } // Slow envelope follower if (env[k] > stt->capacitorSlow) { // increase capacitorSlow stt->capacitorSlow = AGC_SCALEDIFF32(500, (env[k] - stt->capacitorSlow), stt->capacitorSlow); } else { // decrease capacitorSlow stt->capacitorSlow = AGC_SCALEDIFF32(decay, stt->capacitorSlow, stt->capacitorSlow); }使用快包络和慢包络的最大值作为当前子帧的等级
// use maximum of both capacitors as current level if (stt->capacitorFast > stt->capacitorSlow) { cur_level = stt->capacitorFast; } else { cur_level = stt->capacitorSlow; }最后把等级映射到增益上去,增益分为整数和小数部分。这里用了很trick的方法,首先计算定点数前面0的个数来获取索引值,然后小数部分通过线形插值获取,然后把整数部分和小数部分相加作为下一帧的增益。
zeros = NormU32((uint32_t) cur_level);if (cur_level == 0) { zeros = 31;}tmp32 = ((uint32_t) cur_level << zeros) & 0x7FFFFFFF;frac = (int16_t) (tmp32 >> 19); // Q12.tmp32 = (stt->gainTable[zeros - 1] - stt->gainTable[zeros]) * frac;gains[k + 1] = stt->gainTable[zeros] + (tmp32 >> 12);下面计算门限值,门限值由两部分组成,一部分是基于快包络计算的似然比,另一部分是短时方差。
// Gate processing (lower gain during absence of speech) zeros = (zeros << 9) - (frac >> 3); // find number of leading zeros zeros_fast = NormU32((uint32_t) stt->capacitorFast); if (stt->capacitorFast == 0) { zeros_fast = 31; } tmp32 = ((uint32_t) stt->capacitorFast << zeros_fast) & 0x7FFFFFFF; zeros_fast <<= 9; zeros_fast -= (int16_t) (tmp32 >> 22);
gate = 1000 + zeros_fast - zeros - stt->vadNearend.stdShortTerm;接着会根据计算出来的门限值进行一些判断,并限制gain的范围防止失真。最后把增益应用在当前语音帧上。这个处理过程为分两步,首先对第一个子帧单独进行处理:
delta = (gains[1] - gains[0]) * (1 << (4 - L2)); gain32 = gains[0] * (1 << 4); // iterate over samples for (n = 0; n < L; n++) { for (i = 0; i < num_bands; ++i) { tmp32 = out[i][n] * ((gain32 + 127) >> 7); out_tmp = tmp32 >> 16; if (out_tmp > 4095) { out[i][n] = (int16_t) 32767; } else if (out_tmp < -4096) { out[i][n] = (int16_t) -32768; } else { tmp32 = out[i][n] * (gain32 >> 4); out[i][n] = (int16_t) (tmp32 >> 16); } } // gain32 += delta; }然后对剩余的子帧进行处理:
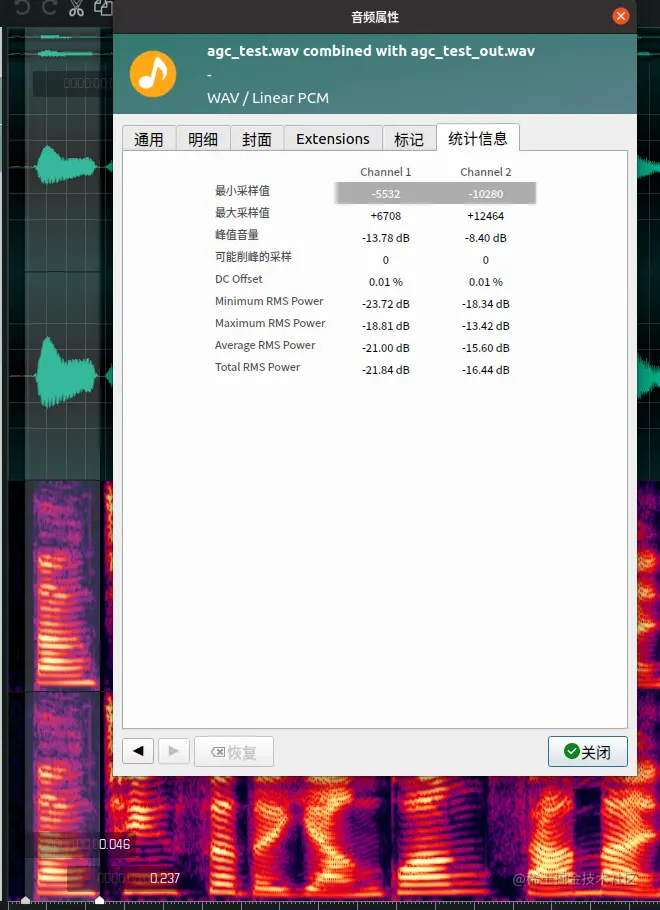
// iterate over subframes for (k = 1; k < 10; k++) { delta = (gains[k + 1] - gains[k]) * (1 << (4 - L2)); gain32 = gains[k] * (1 << 4); // iterate over samples for (n = 0; n < L; n++) { for (i = 0; i < num_bands; ++i) { int64_t tmp64 = ((int64_t) (out[i][k * L + n])) * (gain32 >> 4); tmp64 = tmp64 >> 16; if (tmp64 > 32767) { out[i][k * L + n] = 32767; } else if (tmp64 < -32768) { out[i][k * L + n] = -32768; } else { out[i][k * L + n] = (int16_t) (tmp64); } } gain32 += delta; } }至此AGC一帧的处理流程就全部结束了,最后看下它的效果, 可以看到虽然增益有所增加,但是能量较大的语音和能量较小的语音包络并不是在同一水平,这可能会引起声音忽大忽小。
5. Conclusion
相比于其他算法,AGC似乎没有那么受到深度学习的青睐,很少听说有人用深度学习作AGC算法。WebRTC的AGC达到了基本AGC的功能,但是存在很多不足。个人感觉AGC是一个很偏工程性的算法,只有调试经验多了才能更深入的理解算法的内容。WebRTC的AGC高度工程化的代码,带来了计算效率提升的同时也使得了解其原理的门槛变高,但是了解其核心并没有那么困难。
参考文献:
[1]. 实时语音处理实践指南
[2]. zhuanlan.zhihu.com/p/375716200
作者:Ryukkkkkk
链接:https://juejin.cn/post/7077569910078963719
来源:稀土掘金
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
