
通过前面文章的分析,我们已经明确,Router 的核心职责是作为中央存储记录在线客户端的连接状态,Router 在本质上是一个内存数据库。
内存是一种易失性的存储,既如此,Router 的可用性如何保障呢?
副本是分布式存储系统容错技术的唯一手段!所以解决 Router 的可用性问题,为其增加冗余的副本即可。
分布式存储系统的副本,有两类常用模式:主从模式和主主模式。
一、主从模式
对于主从模式来说,服务向 “主节点” 写数据,“从节点” 从 “主节点” 中同步数据;“主节点” 和 “从节点” 都是可以提供 “读数据” 服务的,不过只有主节点才能提供 “写数据” 服务,所以主从模式对于写操作来说,是单点方式,要解决 “写高可用” 是非常麻烦的。
二、主主模式
对于主主模式来说,服务可以向任何一个 “主节点” 写数据,也可以从任何一个 “主节点” 读数据,然后两个主节点之间互相同步数据,所以主主模式同时满足数据 “读高可用” 和 数据 “写高可用”;但是要注意,主主模式不适用的业务场景:对同一条数据从两个 “主节点” 同时进行写操作。
举一个例子: 主主模式集群中有一条数据为 x = 5,两个服务节点分别对两个 “主节点” 同时进行修改,一个 “主节点” 修改为 x = 7,一个 “主节点” 修改为 x = 9,此时两个 “主节点” 在互相同步时就会出现冲突。
所以,在使用主主模式时,一定要避免对相同数据的并发写。
Router 采用了 主主模式,见下图。
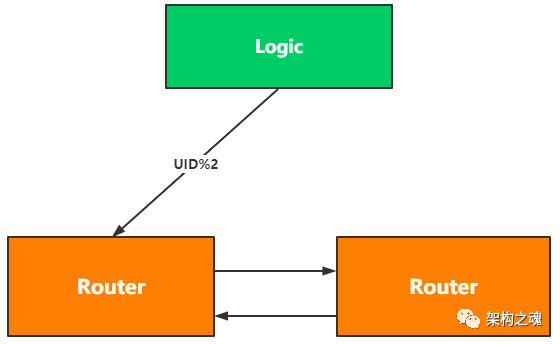

Logic 在写 Router 时,通过公式 uid % 2 计算要写入的 Router 节点,避免了相同用户记录在两个主 Router 节点上的并发写操作。另外,对于同一用户的操作,会由相同的 Logic 节点来处理(后面的技术文章中会详细分析),这也会避免相同用户记录的并发写入。
单个 Router 节点保存了所有在线客户端的用户数据,随着在线用户量的增多,Router 会很容易到达存储瓶颈;解决这个问题的常用方案是分片,见下图。
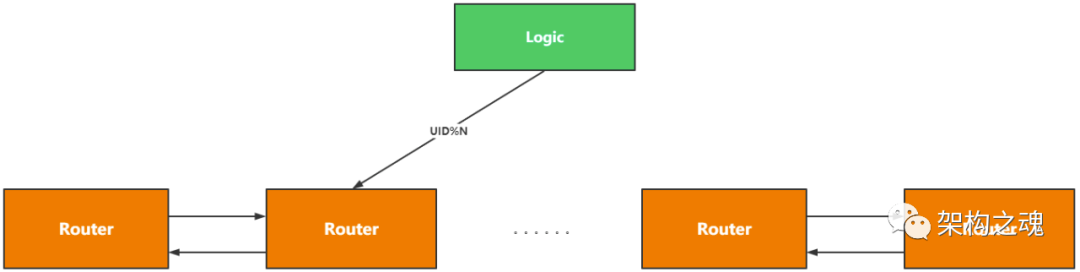
将所有在线用户分配到 N 个分片中,需要部署 N 组Router,每一组 Router 可以主主模式部署也可以主从模式部署; Logic 在写 Router 时,通过公式 uid % N 计算要写入的 Router 分组。这样通过分组的方式,实现了在线用户的横向线性扩容;每一组内部通过主主模式 或 主从模式实现了高可用。
这里有一个实践性很强的问题,大家思考一下: 将最开始的一组 Router 扩容为四组 Router 时,怎样将原来的数据进行迁移呢?
答案是不必迁移。一组 Router 扩容为四组 Router 后,原来这一组 Router 中大概会有四分之三的在线用户数据会被遗弃,不过不必担心,在上一篇文章(IM专题:分层架构IM系统(6)— Router能力分析)中,我们分析过,Router 的心跳扫描线程会扫描出心跳失活的用户记录进行清理;另外,其它三组 Router 最开始是空白数据,但随着在线用户客户端的心跳到来,会逐步将这空白的三组 Router 数据进行修复。
心细的同学会提出疑问:即使如此,当从这三组 Router 中读数据时,读不到怎么办呢?这就涉及到 IM 系统的容错性了。将一个在线用户,按离线方式去处理,并不会对用户造成不好的体验。当然,对 Router 进行扩容,选择在凌晨时分处理,肯定是最合适的。
将一个刚启动的 Router 节点作为 “从节点” 部署时,“主节点” 是如何进行数据同步的呢?见下图。
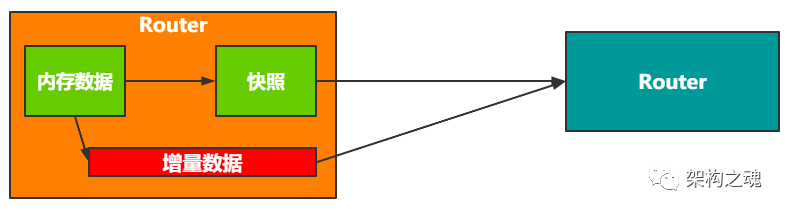
Router 在内存中维护了很多个 Map,当有其他 Router 节点以 “从节点” 的角色连接过来时,“主节点” Router 会将内存数据生成一个 “快照”,然后将 “快照” 数据发送到 “从节点”。
“主节点” Router 生成 “快照” 后,再接收到的所有的 “写操作” 将全部写入到 “增量数据队列” 中;Router “从节点” 消化完 “快照” 后,就会再次发请求到 “主节点”,然后不断从 “主节点” 的 “增量数据队列” 中读数据完成主从同步。
关于 “快照” 如何生成,我们在后面的技术文章中进行分析!
最后,总结文中关键:
1、 分布式存储系统的副本模式有两种实现方式:主从模式和主主模式,在使用主主模式时,需要避免相同数据记录在两个主节点上被并发写入;
2、 Router 采用了主主模式,当在线用户量达到单个 Router 的存储瓶颈时,通过分片方式实现横向扩容;
3、 在对 Router 进行横向扩容时,在 IM 这个业务场景下,不需要进行数据迁移;
4、 Router 进行主从数据同步时,先生成和同步快照,然后同步增量数据。
对 Router 的分析到这里时,会有同学提出疑问: Router 在整个 IM 系统中,特别像 Redis,Redis 是完全可以替代 Router 的 ,为什么要自研 Router 呢? 因为在早期,Redis 还没有那么成熟和普及!随着 IM 系统不断迭代,用 Redis 替换掉 Router 是必然的,因为 Redis 的扩展性和维护成本相对都是最好的!
作者:棕生 | 公众号—— 架构之魂
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。