
AI”卷”进实时互动
2021年,元宇宙概念席卷全球,国内各大厂加速赛道布局,通过元宇宙为不同的应用场景的相关内容生态进行赋能。针对“身份”、“沉浸感”、“低延迟”、“随时随地”这四个元宇宙核心基础,ZEGO 即构科技基于互动智能的业务逻辑,提出并落地了 ZegoAvatar 解决方案,将 AI 视觉技术应用至虚拟形象,完成了业务和技术的无缝衔接。

ZegoAvatar 基础能力包括:面部表情随动、语音驱动表情、AI 人脸特征识别(AI 捏脸)、拍照捏脸等,涉及的 AI 技术点包括人脸检测、人脸跟踪、人脸关键点检测、头部姿态检测、3D人脸重建、AI 特征识别等。
上次我们讲述了关于 ZegoAvatar 的面部表情随动技术解析,今天我们将和大家一起再探讨下关于 ZegoAvatar 中的 AI 捏脸部分!
捏脸技术的发展历程
首先来讲一下“捏脸”的概念,“捏脸”就是用系统设定的元素组合成为虚拟角色定制出个性化的形象,比如通过人脸、眉毛、眼睛、发型等元素的重新组合,搭配成一张头像作品。
关于捏脸的发展过程
2005 年,国内出现了首款可以进行捏脸的游戏《完美世界》。在游戏中你可以自定义角色形象,捏出你想要的造型。
当然,那个时候还叫“形象自定义系统”,仅仅可以满足一些比较简陋、简单的五官替换功能,虽然那时,多半的玩家也只是先选择系统库里的脸型,然后再选择发型,之后再选择五官模型,但这新奇的模式不仅给玩家带来了全新的游戏体验,也为后来游戏中“捏脸”系统的蓬勃发展奠定了基础。
2013 年《剑灵》B&S 又将捏脸的玩法进行了普及,它还有一个非常好的捏脸导入功能,你可以直接将别人的捏脸数据导入你创建的人物中,这意味着捏脸的成本非常低。
2018 年国内新推出的热门游戏《逆水寒》,提供了可调动面部几十个肌肉群、通过排列组合绽放出无数种可能性的捏脸系统。
我们为什么要“捏脸”?
关于我们为什么要“捏脸”这个问题,我们可以从审美标准、代入感和个性化三个方面来思考:
通过对比不同世代的审美标准,我们可以发现这样一个规律:随着时代的不断进步,人的审美观、对美的要求都在不断地发生改变。对于服饰、配色的追求是如此,对于游戏品质的追求亦是如此。
无论是游戏还是虚拟社交,最重要的无疑是“代入感”,而对这一点感官最为直观的,那就是自己的玩家形象,因此一个强大捏脸的游戏,给玩家的代入感是无与伦比的。
捏脸也是寄托个性化表达的载体之一。如果你想以高冷酷炫的外表示人,那你就给自己捏一个霸道总裁脸;如果你希望对外界呈现温柔可人的一面,那你不妨把自己的虚拟形象塑造得柔美端庄。
当下很多玩家的注意力已经从在游戏里的“炫实力”转移到了“炫酷”、“炫特色”上面。无论打开哪款时下流行的网游,玩家花在装扮、美化上的钱绝对不会比提升能力来得少。一张独具特色的虚拟角色面孔在虚拟世界中已然成为社交的第二张名片,而这也成为了与虚拟世界连接的桥梁。
ZegoAvatar 捏脸效果展示
向大家展示一下 ZegoAvatar 的拍照捏脸效果:

说明:
1、实验数据来源均为内部收集和付费收集获得的,不涉及用户隐私;
2、当您在使用我们产品 Avatar SDK 功能时,我们需要本地处理您的面部特征值信息、声音特征信息,以实现捏脸、表情随动、声音驱动功能场景。您需要授权我们使用摄像头、麦克风权限,关闭后仅影响对应功能,不影响应用其他功能。我们仅会在您的本地设备中离线处理相关面部特征值信息、声音信息,不会上传、后台存储或与第三方共享该种信息。
整体捏脸流程解析
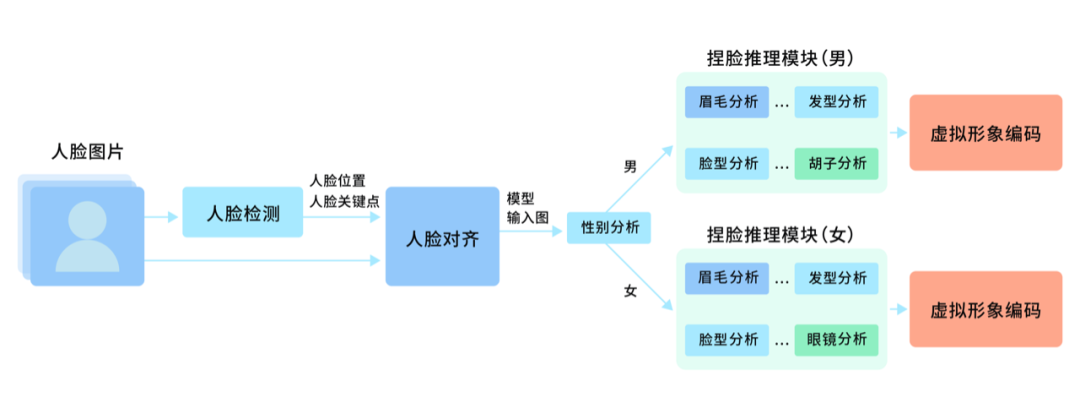
在 ZegoAvatar 的技术方案中,拍照捏脸是通过送入一张人脸照片来得出该照片中人的性别、年龄、发型、脸型、眼睛大小、眉毛位置、眉毛长短、眉毛类型、是否戴眼镜等信息来给出一个与该头像最为契合的虚拟形象。
与传统的捏脸方式不同, ZegoAvatar 拍照捏脸采用了 AI 技术,可实现自动生成自己的虚拟形象,让每个人的虚拟形象不再千篇一律。下面我们将向大家详细解读 ZegoAvatar 捏脸算法大致流程与整体架构。
AI 技术在捏脸中的具体应用
AI 捏脸涵盖的主要技术有:人脸检测、人脸对齐,性别分类,发型分类,及眉毛、眼睛人脸五官的属性分类等。
捏脸的大致流程
- 通过对输入图片的分析获取对齐后的人脸图片。人脸对齐后的图片分 2 种,一种是仅含人脸的图片(图片人脸占比100%),另一种是包含完整头发信息的图片(人脸占比 25% 左右);
- 将对齐后的人脸图片送入性别分类模型中,得出性别;
- 通过判断性别来选择相应的捏脸推理模块,从而得到虚拟形象编码(含是否有胡子,脸型、发型等信息);
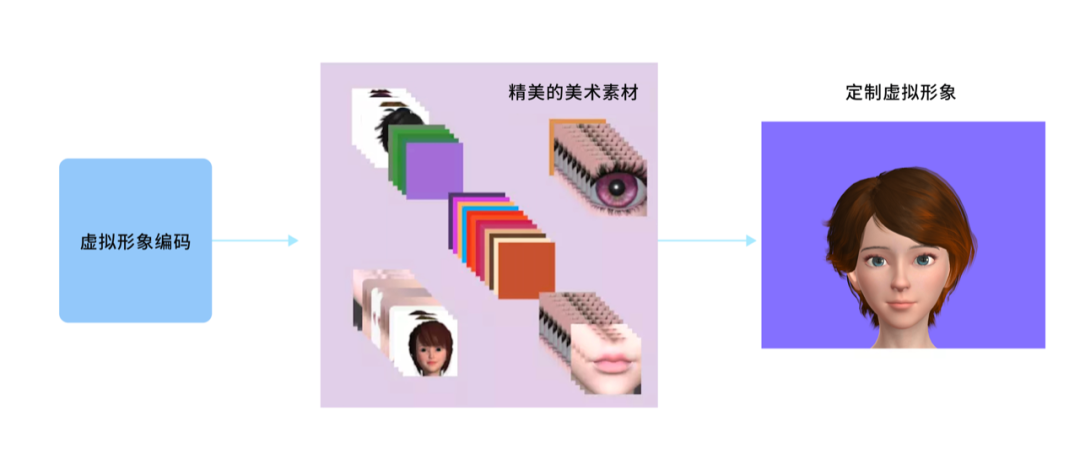
- 最后通过虚拟形象编码生成定制化的虚拟形象。
捏脸的效果难点攻克
为了得到最好的捏脸效果,我们在实际研发过程中需要很好的解决以下问题:
- 数据如何采集
- 如何保证结果准确
- 不同用户在不同使用场景的鲁棒性
- 效果如何保证
科学数据的采集
根据数据采集模块得到人脸属性数据,并通过数据矫正和增强后训练得到 AI 表情模型,具体分为以下几个部分:
- 数据采集:针对业务需求,我们购买和收集了人脸数据约 102 万张,并经过严格标注和验收;我们为此开发了一套可用于人脸属性的数据标注软件,用于获取人脸的性别、头发、胡子、是否带眼镜、皮肤等级等数据;
- 数据管理:我们还对一些难例在数据集上进行细分,尤其是对面部光线过暗、图像质量低、人脸角度过大等极端情况的数据进行了分类管理,在训练时可以对其进行不同的数据处理,如样本均衡,针对难例类型加入超参数均衡损失计算等在数据上进行训练优化;
- 数据增强:针对落地场景,设计了定制化的数据增强流程,丰富了训练数据的模式。
模型设计的主要思想
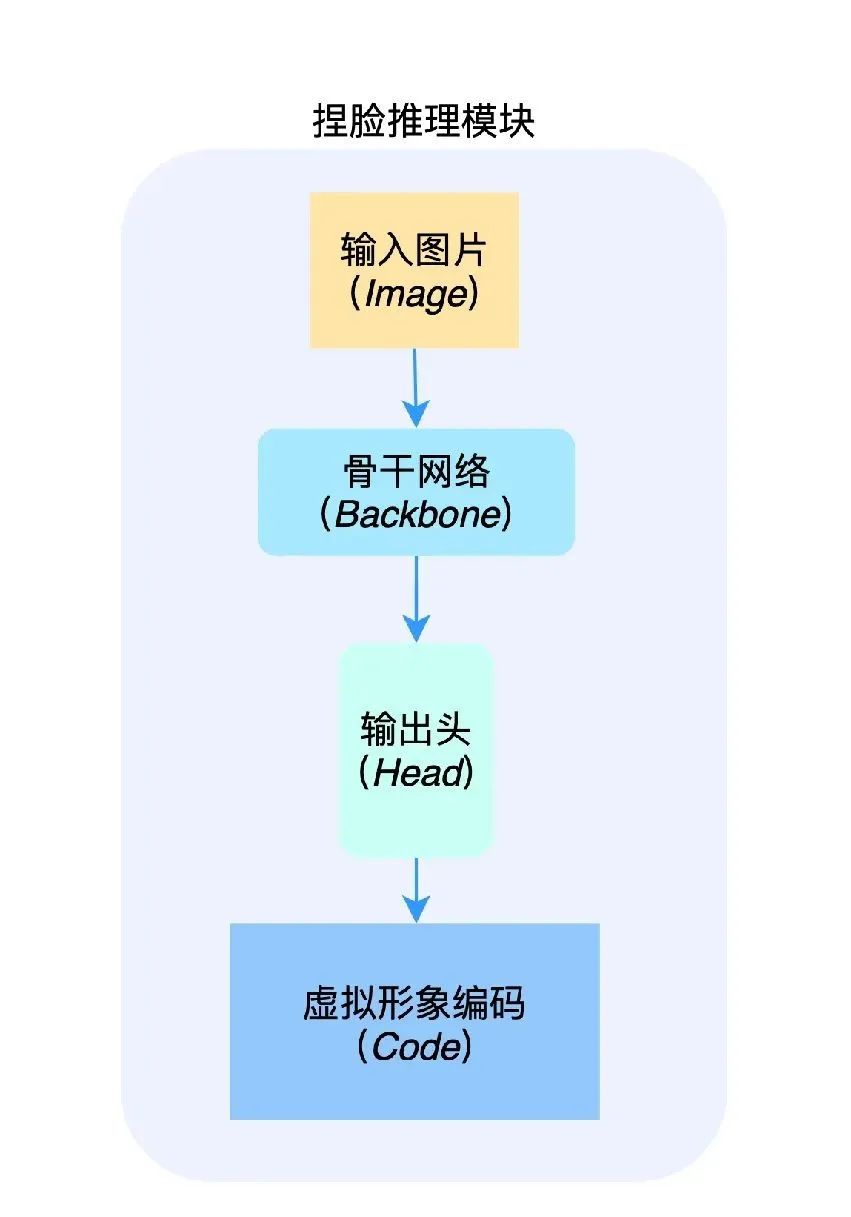
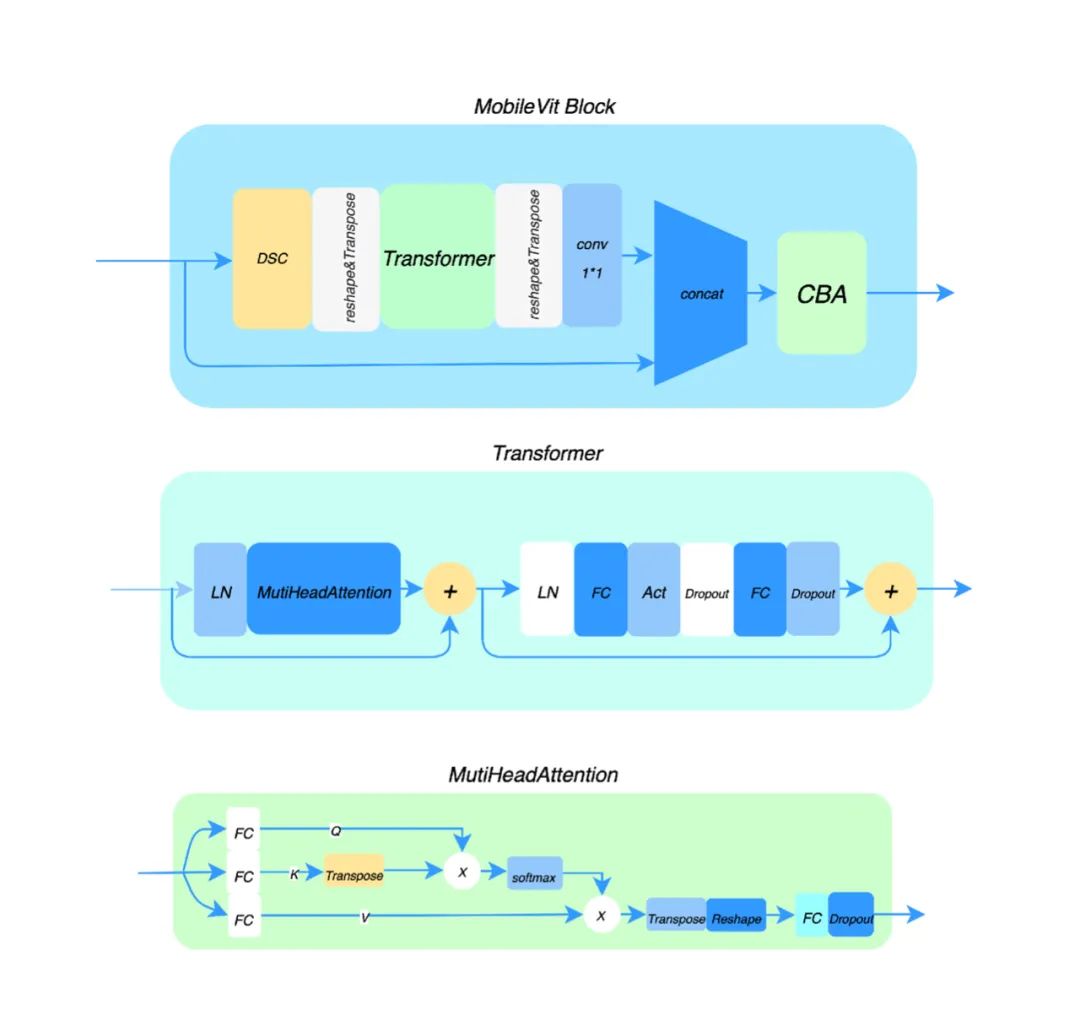
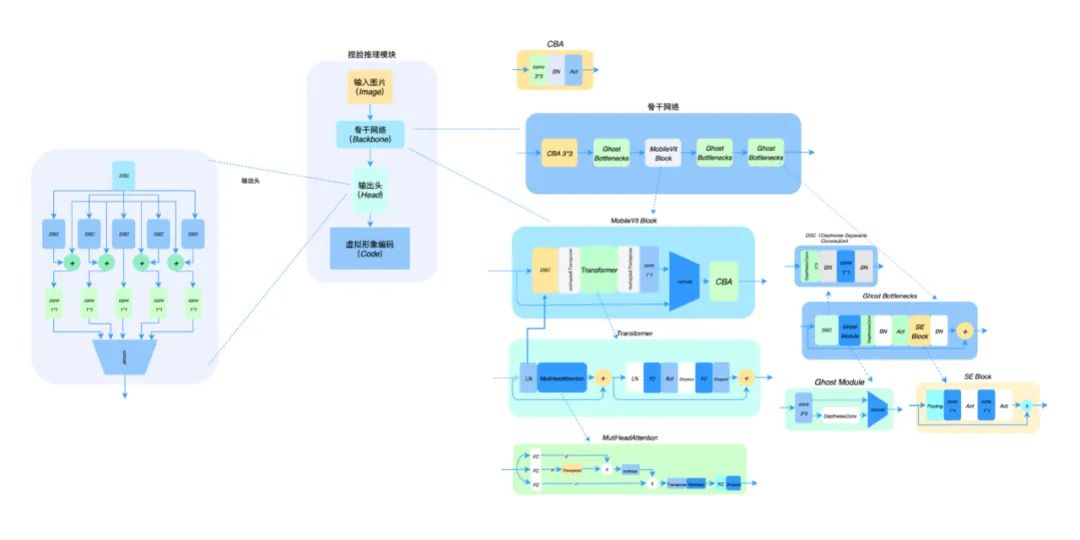
在捏脸推理模块中的网络模型搭建上,我们通过试验结果对比验证,设计一种性能和精度表现都非常不错的网络结构,主要包括提取图像特征的骨干网络和输出相应虚拟形象编码的输出头。结构图如下:
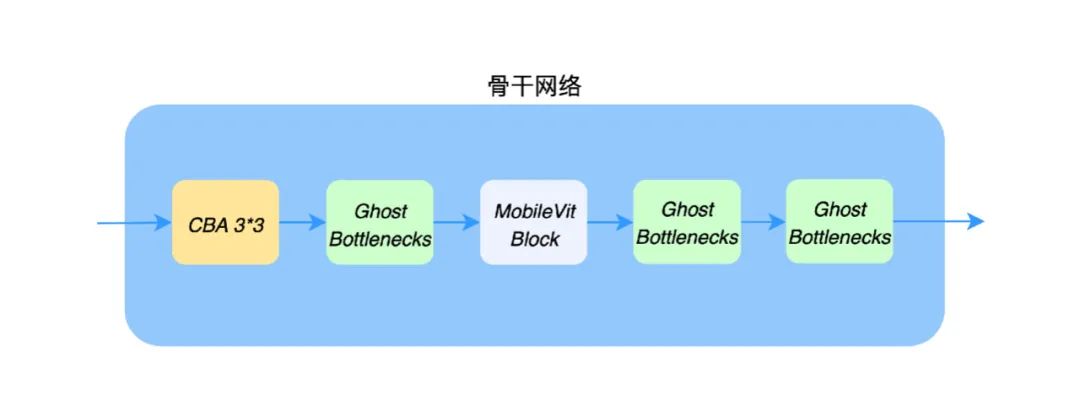
我们尝试了 Ghostmodel、Mobilenet、Bottleneck、MicroNet 等思想的网络结构和训练策略,在反复测试验证下最终的骨干网络是由 CBA、Ghost Bottleneck、MobileVit Block 组成,结构如下:
其中骨干网络和输出头模块的具体结构如下:
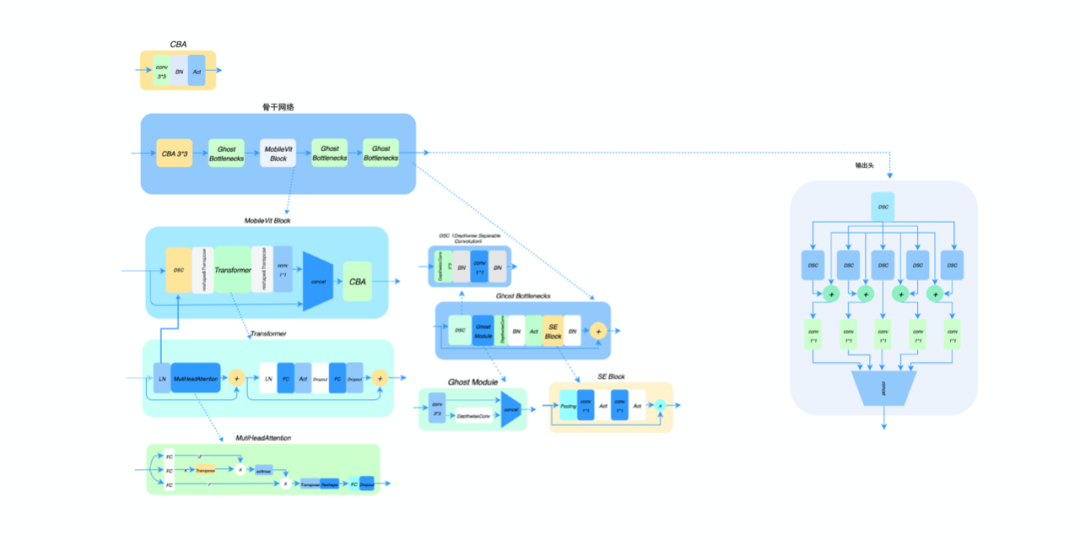
其中 Ghost Bottleneck 通过“廉价“的操作(DepthwiseConv)获取“冗余“的特征图来实现模型的推理提速,并通过Bottleneck 思想将特征图的通道进行增加和减少进一步减少了参数量,其结构如下:
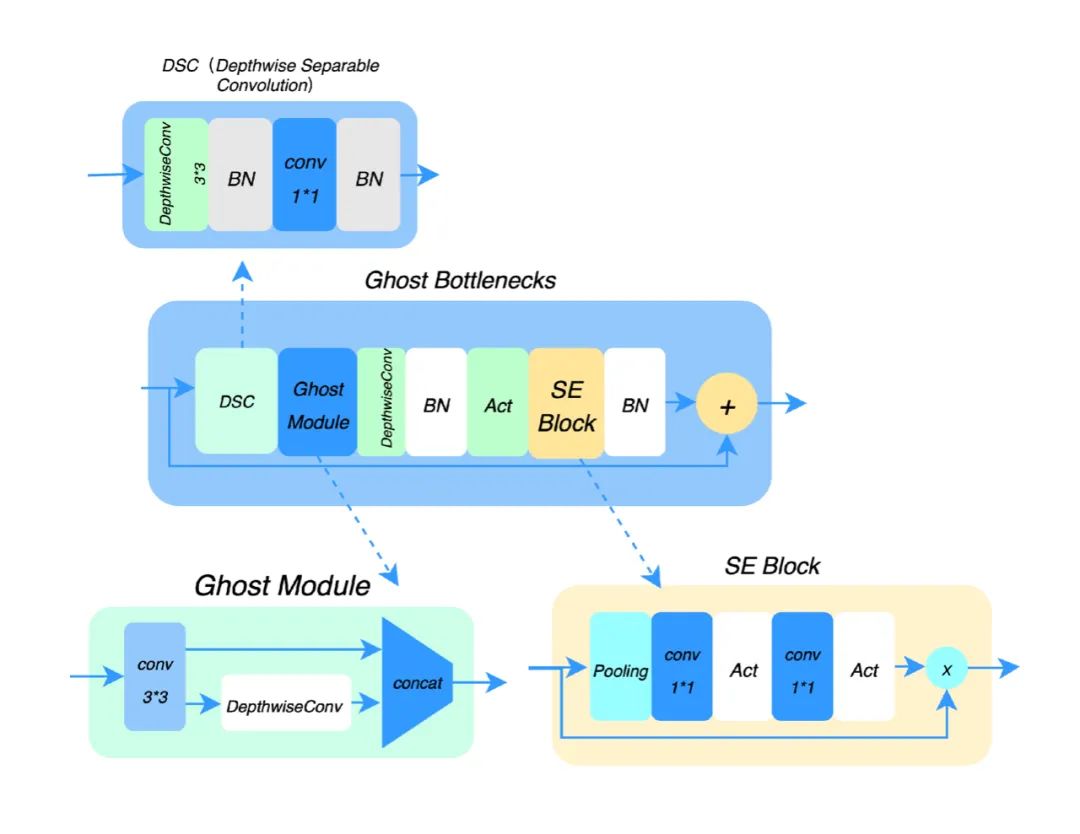
Transformer,MobileVit Block 可以通过较少的参数获取各个特征图中局部的表征信息和特征图对其他特征图的全局表征信息,通过特征之间相互“参照”,使得特征的表达更加准确,其结构如下:
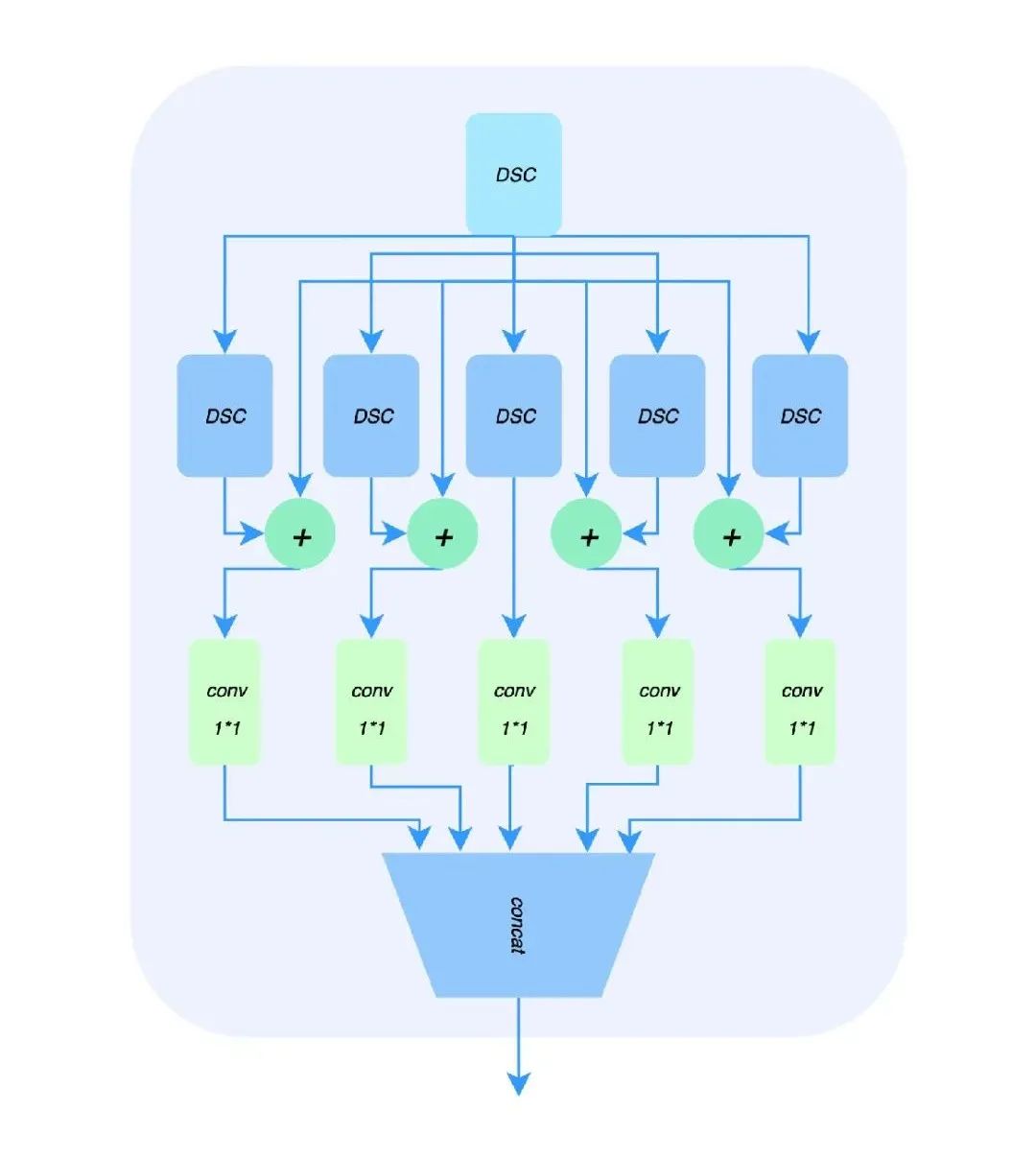
输出头采用的特征共享的结构,使具有相关性的子任务之间相互起促进作用,其结构如下:
就这样搭建出了我们完整的网络结构:
精心设计优化方法
设计不同的任务分支并针对类别进行细分,还采用的共享特征的机制利用任务之间的相关性辅助目标任务学习。
损失函数为:
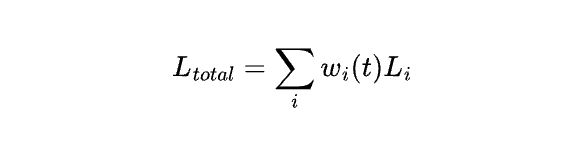
在实际训练时我们不知道各个子任务之间的影响是否都是有效的,为消除多任务之间存在竞争关系,我们通过调整梯度,使每个 task 的训练率相同,从而可以自动平衡多任务 loss function 中的权重。举个例子,如果任务i收敛的很快,那么相对于其他子任务这个任务的 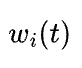 就应该减小,从而使其他任务对当前网络产生更大的影响。
就应该减小,从而使其他任务对当前网络产生更大的影响。
总的来说,我们大致从以下几个方面进行优化:
- 从网络设计:
捏脸算法不是一个笼统 end-to-end 的算法,需要从很多维度提取特征进行细节分析。为了减少模型的消耗,我们很多模型都采取多任务辅助监督训练。中间辅助监督的思想最早在 2014 的 ILSVRC 冠军模型 Googlenet 中出现,后面在分割网络 PSPNet 中有借鉴,最近在 ECCV 2020 中提出的 LableEnc,更是说明将 ground-truth 标签映射到潜在嵌入空间上,作为辅助backbone 训练的中间监督信息在检测领域的有效性。结合我们实际任务,我们的多任务辅助监督训练与上面提及的中间辅助监督不一样,我们的中间监督不仅仅只使用 ground-truth,大多时候,我们设计的网络会使用多个任务协同监督一个主任务。 - 从数据处理:
数据处理,我们会根据我们实际需求,采用不同的数据增强,除此之外,为了减少计算量,在某些任务中,我们还使用重构图像的策略,X = AS,X 表示原图像,S 表示重构图像,A 表示基函数组成的矩阵。
我们的优化准则为: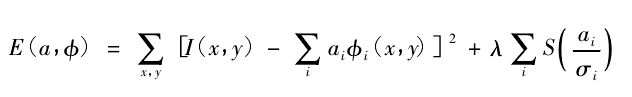
 其中,I(x,y) 表示原图像 X 上的像素,
其中,I(x,y) 表示原图像 X 上的像素,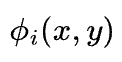 表示基函数矩阵 A 的第 i 个向量,
表示基函数矩阵 A 的第 i 个向量,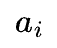 表示 S 中的第 i 个响应值。通过优化准则,我们能够实现通过感受野响应相对强烈的信息表达整张图片所有信息。
表示 S 中的第 i 个响应值。通过优化准则,我们能够实现通过感受野响应相对强烈的信息表达整张图片所有信息。 - 从损失函数 损失函数的设计能够直接影响网络收敛的好坏,不同任务的损失函数不同,但其本质就是通过最小化损失函数求得全局最优。我们会通过具体任务定义不同的损失函数,或者在公开损失函数中根据我们需求加惩罚项或约束。
完美的捏脸效果
由编码结果直接生成虚拟形象,可能会出现脸型与五官或者发型“不搭噶“的情况。如何保证定制虚拟形象拥有更高的颜值,也需要依赖整个团队的配合。
一方面,开发同学在虚拟形象的渲染效果上不断的调试优化,在肤色的调节、阴影的渲染、毛发的渲染、高光效果上做了很多尝试;另一方面设计同学为虚拟形象设计的各种贴图素材,构建了完备的素材库。例如:眉毛类型、眼睛形状、睫毛样式、脸型、肤色等。
在技术不断钻研和美学角度审视的碰撞下,这样才使得 ZegoAvatar 最终的虚拟形象不仅有很高的精细度,还提供了十分丰富的捏脸自由度。
下面从 3 个方面简单表达捏脸环节的效果:
- 从性别上分析
性别识别,是捏脸最基础也是最关键的环节。因为角度,光照等外界因素,很容易识别错误,一旦性别识别错误,后面的捏脸程序,就会“越跑越偏”。为了平衡准确率和在移动端实时性,训练过程中尝试了很多 tricks,我们的性别识别,在不同国籍不同年龄不同场景不同表情组成的 5万测试集上,准确率能达到 96.7%。 - 从人脸外观特征上分析
性别识别结果之后,人脸上的外观特征识别尤为重要,比如是否戴眼镜,是否有胡子,胡子分布在哪里。这些人脸上明显的外在特征,如果识别不准确,捏出来的效果就会非常假。我们人脸外观特征模型,包括眼睛,胡子和胡子分布的识别,各维度的准确率分别为眼镜:99.5%、胡子:96.2%、胡子上下左右分布:95.0%。 - 从头发维度上分析
头发分析也是捏脸过程非常重要的一环,并且头发多个维度都具有多样性,在头发分析中,如果识别错其中一个维度,整体效果就会大大打折扣。我们的头发分析模型,囊括了 5 种长度,9 种刘海,2 种捆扎方式还有头发区域 4 种维度的信息,能够给到渲染模块非常细粒度的头发特征,从而渲染出非常逼真的头型。
ZEGO 即构科技根据 AI 产业发展变化,抓住适合自己技术能力的垂直应用场景,围绕虚拟社交和在线 KTV 场景核心问题挖掘,为用户打造个性化的虚拟形象。在制作 AI 捏脸时走了一些弯路,后来我们从围绕市场玩家的关注热点,又在整个团队的不断探索和验证、积极寻找突破口下我们的捏脸质量也越来越高。
莎士比亚在《仲夏夜之梦》中借人物之口说过,“想象的东西往往是虚无缥缈的,但在诗人的笔下,它们可以有形、有固有的实质,也可以有名字”。ZEGO Avatar 就如同莎士比亚笔下的诗人一般,为每个人定制个性化的虚拟形象,成功的开启了进入元宇宙时代的入口。
ZEGO 即构科技也将随着相关领域的技术成熟,将打造出赋予新的内涵和意义的数字人。从技术底层为内容开发者赋能,将虚拟技术更直接、更便捷、更高效的交付终端用户。
未来,我们可通过 AI 模型直接得出捏脸系数,真正做到千人千面!
访问 ZEGO Avatar 开发文档,开始捏脸之旅。
本文为原创稿件,版权归作者所有,如需转载,请注明出处:https://www.nxrte.com/jishu/994.html