
现代变化检测通过深度卷积强大的判别能力取得了显着的成功。然而,由于场景中物体的复杂性,高分辨率遥感变化检测仍然具有挑战性。具有相同语义概念的对象可能在不同的时间和空间位置表现出不同的光谱特征。最近使用纯卷积的变化检测管线仍在努力将时空中的远程概念联系起来。非局部自注意方法通过对像素之间的密集关系进行建模表现出有前景的性能,但计算效率低下。在这里,我们提出了一种双时态图像Transformer (BIT),以高效且有效地对时空域内的前后内容进行建模。我们认为高维度的变化区域可以用几个视觉词来表示,如语义token。为实现这一点,我们将双时态图像表达为几个token,并使用Transformer编码器在基于token的紧凑时空中对前后内容进行建模。然后将学习到的前后内容丰富的token反馈到像素空间,以通过Transformer解码器改进原始特征。我们将 BIT 合并到一个基于深度特征差异的变化检测框架中。在三个变化检测数据集上进行的大量实验证明了所提出方法的有效性和效率。值得注意的是,我们基于 BIT 的模型显着优于纯卷积baseline管线,仅使用1/3的计算成本和模型参数。基于没有复杂结构的简单主干ResNet18,我们的模型在效率和准确性方面超过了几种最先进的变化检测方法,包括最近四种基于Attention的方法。
来源:Arxiv
论文地址:https://arxiv.org/abs/2103.00208
代码链接:https://github.com/justchenhao/BIT_CD
作者:Hao Chen, Zipeng Qi and Zhenwei Shi
内容整理:陈梓煜
简介
变化检测的目标是通过比较在不同时间拍摄的同一区域的共同配准图像,为区域中的每个像素分配二进制标签,即变化或无变化。变化的定义因应用而异,例如在遥感图像中,城市扩张、森林砍伐和损害评估都会造成遥感图像拍摄结果的变化。基于遥感图像的信息提取仍主要依赖人工目视判读,自动变化检测技术可以减少大量的人力成本和时间消耗,因而受到越来越多的关注。
高分辨率卫星数据和航空数据的可用性为精细监测土地覆盖和土地利用开辟了新途径。基于高分辨率光学遥感图像的变化检测在两个方面仍然是一项具有挑战性的任务:1)场景中存在的物体的复杂性,2)不同的成像条件。两者都导致具有相同语义概念的对象在不同时间和不同空间位置(时空)表现出不同的光谱特征。例如,如图1(a)所示,场景中的建筑物物体具有不同的形状和外观(黄色方框),同一建筑物物体在不同时间可能由于光照而具有不同的颜色(红色方框) 变化和外观改变。为了识别复杂场景中的兴趣变化,强大的变化检测模型需要:1)识别场景中发生变化区域的高级语义信息,2)区分真正的变化和复杂的无关变化。
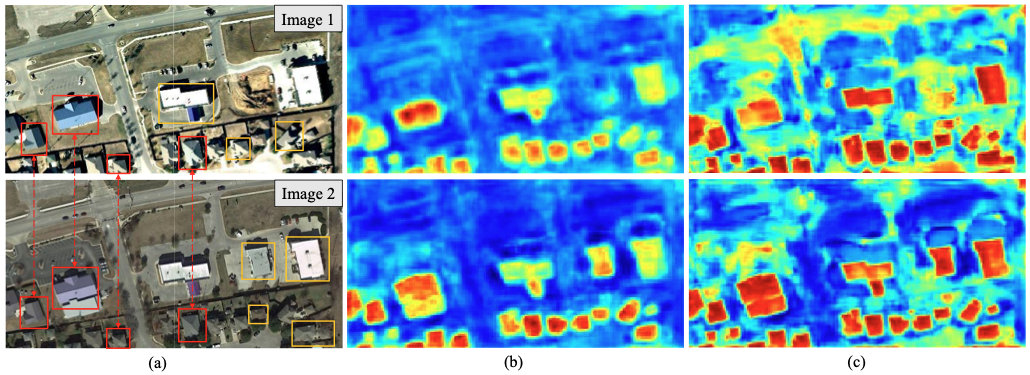
如今,由于其强大的判别能力,深度卷积神经网络已成功应用于遥感图像分析,并在变化检测任务中表现出良好的性能。最近的变化检测 方法依赖于基于 CNN 的结构从每个时间图像中提取变化区域的高级语义特征。
由于空间和时间范围内的前后内容建模对于识别高分辨率遥感图像中的兴趣变化至关重要,因此最近的努力一直集中在增加模型的接收场 (RF),通过堆叠更多的卷积层,使用扩张卷积,并应用Attention机制。与本质上受限于RF大小的纯基于卷积的方法不同,基于注意力的方法(通道注意力、空间注意力和自注意力)在建模全局信息方面是有效的。然而,大多数现有方法仍难以将时空中的远程概念联系起来,因为它们要么将注意力分别应用于每个时间图像以增强其特征,要么只是使用注意力来重新加权通道或空间维度中融合的双时相特征。最近的一些工作利用self- attention对时空中任何像素对之间的语义关系进行建模,取得了良好的性能。然而,它们的计算效率低下,并且需要高计算复杂度,且计算复杂度随像素数量呈二次方增长。
为了解决上述问题,在本工作中,我们引入了双时态图像Transformer(BIT)来高效且有效地建模双时态图像的前后内容。我们认为高维度的变化区域可以用几个视觉词来表示,如语义token。我们的 BIT 不是在像素空间中对像素之间的密集关系进行建模,而是将输入图像表达为一些高级语义标记,并在基于标记的紧凑时空中对前后内容进行建模。此外,我们通过利用每个像素和语义标记之间的关系来增强原始像素空间的特征表示。
我们将 BIT 合并到一个基于深度特征差异的变化检测框架中。我们基于BIT的模型的整体过程如图2所示。CNN 主干网 (ResNet) 用于从输入图像对中提取高级语义特征。我们使用空间注意力将每个时间特征图转换为一组紧凑的语义token。然后我们使用Transformer编码器对两个token内的前后内容进行建模。孪生网络Transformer解码器将生成的前后内容丰富的token重新投影到像素空间,以增强原始像素级特征。最后,我们从两个细化的特征图中计算特征差异图像,然后将它们输入浅层 CNN 以预测每个像素是否发生变化。
本工作的主要贡献可总结如下:
- 提出了一种基于Transformer的变化检测方法,我们将Transformer引入变化检测任务,以更好地对双时态图像中的前后内容进行建模,这有利于识别图像中真正的内容变化并排除不相关的变化。
- 我们的 BIT 不是在像素空间中对任何元素对之间的密集关系进行建模,而是将输入图像表达为几个视觉词,即标记,并在基于标记的紧凑时空中对上下文进行建模。
- 对三个数据集的大量实验验证了所提出方法的有效性和效率。
方法
我们基于 BIT 的模型的整体过程如图 2 所示。我们将 BIT 合并到一个正常的变化检测管道中,因为我们想利用卷积和Transformer的优势。我们的模型从几个卷积块开始,以获得每个输入图像的特征图,然后将它们输入 BIT 以生成增强的双时态特征。最后,将生成的特征图馈送到预测头以产生像素级预测。我们关键的启发是 BIT 学习并关联高级语义的全局前后内容,并反馈以修改得到有益于原始双时态特征的新特征。
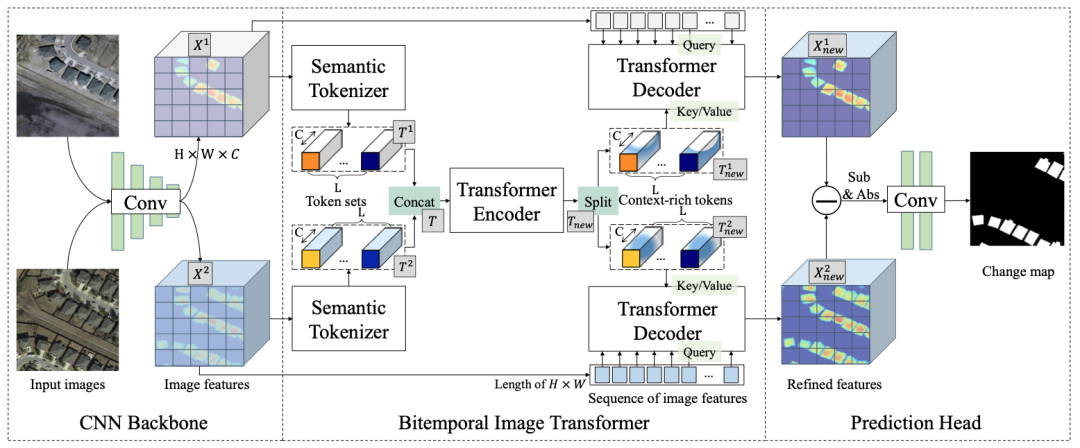
我们的 BIT 包含三个主要组件:1)孪生语义标记器(Semantic Tokenizer),它将像素分组为每个时间输入生成一组紧凑的语义token,2)Transformer编码器,它在基于token的语义概念中建模时空前后内容,以及 3) 孪生Transformer解码器,它将相应的语义标记投射回像素空间以获得每个时间的精细特征图。
孪生语义Tokenizer
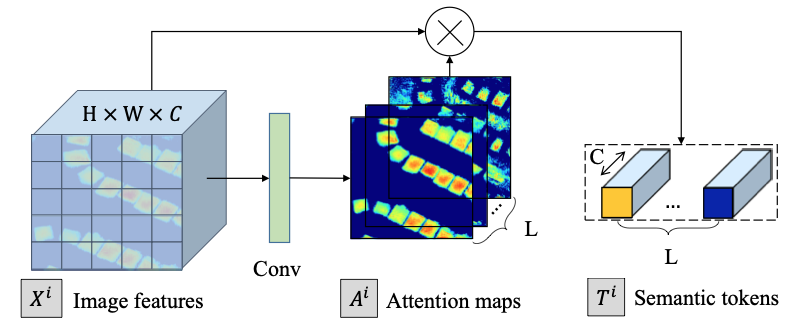
我们认为输入图像发生变化的区域可以用一些高级语义来描述,即语义标记。双时相图像可以共享语义概念。为此,我们使用孪生语义Tokenizer从每个时间的特征图中提取紧凑的语义分词。类似于 NLP 中的Tokenizer,它将输入句子分成几个元素(即单词或短语)并用一个分词向量表示每个元素,我们的语义Tokenizer将整个图像分词为几个视觉词,每个词对应一个分词向量 . 如图 3 所示,为了获得紧凑的token,我们的Tokenizer学习了一组空间注意力图,以在空间上将特征图汇集到一组特征,即token集。
Transformer编码器

Transformer 编码器由multi-head self-attention(MSA)和MLP块的 NE 层组成(图 4(a))。与使用后范数残差单元(post-norm residual unit)的原始Transformer不同,我们遵循ViT采用前范数残差单元 (PreNorm),即层归一化紧接在 MSA/MLP 之前。PreNorm 已被证明更稳定和更有效。
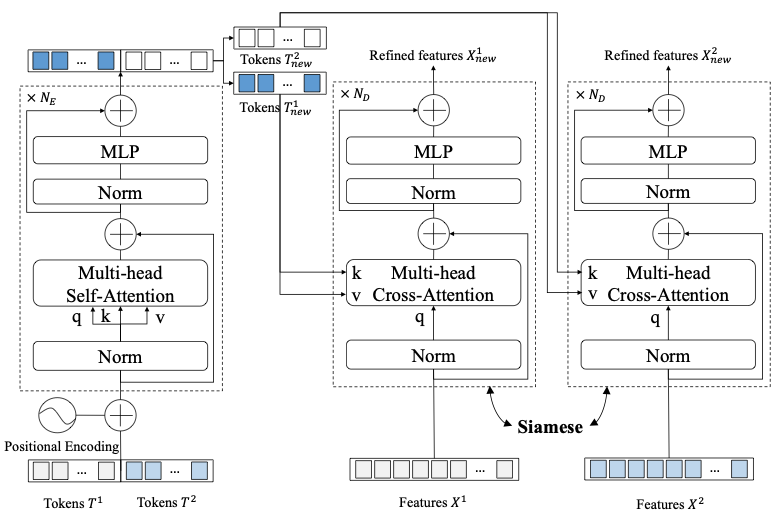


Transformer解码器

实验
数据集
- LEVIR-CD 是一个公共的大型建筑变化检测数据集。它包含 637 对大小为 1024 × 1024 的高分辨率遥感图像。我们遵循其默认数据集拆分(train/val/test)。由于 GPU 内存容量的限制,我们将图像切割成大小为 256 × 256 的小块,没有重叠。因此,我们分别获得了 7120/1024/2048 对数据用于train/val/test。
- WHU-CD 是一个公共建筑变化检测数据集。它包含一对尺寸为 32507×15354 的高分辨率(0.075m)航拍图像。由于[54]中没有提供数据分割解决方案,我们将图像裁剪成尺寸为 256×256 的小块,没有重叠并随机分割 它分为三个部分:6096/762/762 分别用于train/val/test。
- DSIFN-CD 是一个公共二进制变化检测数据集。它包括分别来自中国六个主要城市的六对高分辨率(2m)卫星图像。该数据集包含道路、建筑物、农田和水体等多种土地覆盖对象的变化。我们遵循作者提供的默认大小为 512 × 512 的裁剪样本。我们分别有 3600/340/48 个样本用于train/val/test。
实验对比
我们与几种最先进的方法进行了比较,包括三种纯基于卷积的方法(FC-EF、FC-Siam-Di、FC-Siam-Conc) 和四种基于注意力的方法(DTCDSCN、STANet、IFNet和 SNUNet)。
表1展示了LEVIR-CD、WHU-CD和DSIFN-CD数据集的整体比较结果。定量结果表明,我们基于 BIT 的模型在这些数据集上始终优于其他方法。我们 BIT 的 F1 分数在三个数据集上分别超过最近的 STANet 2/1.6/4.7 分。值得注意的是我们的 CNN 主干只是纯 ResNet,我们没有应用复杂的结构,如 FPN 或 UNet,这些结构通过融合低级特征、高空间精度和高级语义,对像素级预测任务非常强大特征。我们可以得出结论,即使使用简单的主干,我们基于 BIT 的模型也可以实现卓越的性能。这可能归因于我们的 BIT 能够在全局高度抽象的时空范围内对上下文进行建模,并利用上下文来增强像素空间中的特征表示。
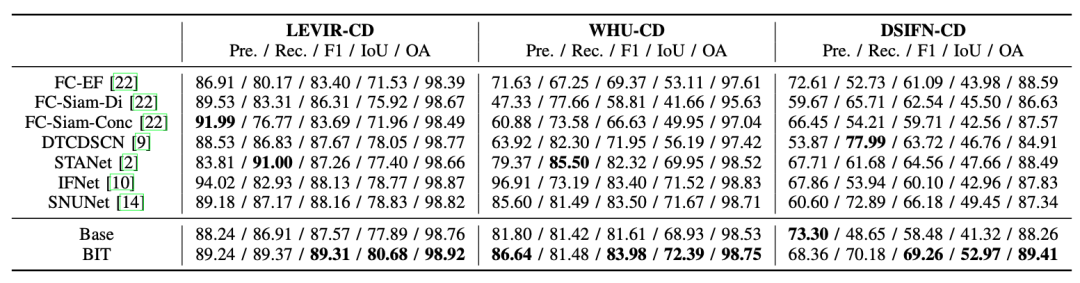
图5展示了不同方法在三个数据集上的可视化比较。为了方便查看使用不同的颜色表示TP(白色)、TN(黑色)、FP(红色)、FN(绿色)。我们可以观察到基于 BIT 的模型取得了比其他模型更好的结果。

我们的基于 BIT 的模型可以更好地避免由于对象的外观与环境光照引起的错误预测(例如,图5(a)、(e)、(g)、(i))。如图 5 (a) 所示,大多数比较方法错误地将游泳池区域分类为建筑物变化(视图为红色),而STANet和我们的BIT可以减少这种错误检测。在图 5(c)中,传统方法将道路误认为是建筑物变化,因为道路具有与建筑物相似的颜色,并且这些方法由于接收场有限而无法排除这些伪变化。其次,我们的BIT还可以很好地处理由季节差异或土地覆盖要素的外观变化引起的无关变化(例如,图5(b)、(f)和(l))。图5(f)中建筑物的非语义变化的示例说明了我们的BIT的有效性,它学习时空域内的有效上下文以更好地表达真实的语义变化并排除不相关的变化。最后,我们的BIT可以针对大面积变化生成相对完整的预测结果(例如,图5 (c)、(h) 和 (j))。例如,在图5 (j) 中,图像2中的大型建筑区域由于接收场有限而无法通过某些比较方法完全检测到(视图为绿色),而我们的基于BIT的模型呈现出更完整的结果。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
