
01 背景
传统基于神经网络的语音合成方法TTS已成为主流,技术相对也比较成熟,但是需要大量发音人的原始录音数据,制作成本相对较高。因此,少量语音样本的自定义TTS技术是语音合成领域的一大热点子方向。
由于极少数据量的限制,工业学业界推出多种方法来提高TTS合成效果。域自适应的迁移学习是一种较为主流的方法,第一阶段预训练产出语音合成的基础大模型,第二阶段基于少量数据在大模型参数上进行自适应,这种方法能最大限度的还原发音风格。
在产品层面,随着TTS技术的快速发展,自定义TTS逐渐成为智能助手越来越关注的方向。它可以满足用户个性化的需求,使用自己喜欢的音色进行播报。但目前业界通常生成自定义TTS的方式(简称自定义TTS1.0)是需要用户录制多句指定文案的音频(通常20句左右),生成相关音色,这种方式需要检测周围环境,指定录制文案,导致效率低和音色选择上的局限性。
本文主要介绍的是基于多算法融合的自定义TTS2.0方案(简称自定义TTS2.0),可以有效的提高用户声音合成效率,满足用户个性化的音色需求,同时也可以给用户带来一定的惊喜感。下图展示OPPO小布助手的产品交互示例图(左图为基于用户数据的主动推荐,右图为基于对话数据的自定义TTS生成)。
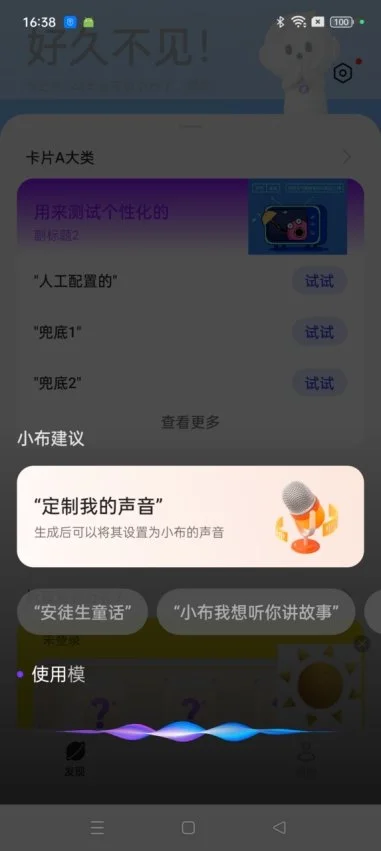

图1 自定义TTS2.0交互图
1.1 技术关键词
以下介绍一下自定义TTS2.0方案中用到的一些关键技术。
● 小样本合成:基于少量训练样本就能建模的语音合成技术,可以方便、快捷地为每个用户定制语音播报效果。
● 语音合成训推一体:合成系统的训练和推理环节紧密耦合在一起,可以快速为海量用户定制模型和服务。
● 声纹比对:通过发音人的语音与已存储主发音人模型进行置信度计算,最终给出判决,以决策当前发音人身份是否于为主发音人。
● 声纹聚类:通过对同一设备的多次交互数据进行身份归类,找出交互次数最多的主发音人。
● 音质检测:通过对交互语音的分析,可以衡量出语音信号的质量,比如:噪声干扰程度、发音的完整性、有效音长短、内容丰富度等。
1.2 技术领先性
作为业界首个基于对话音频的小样本语音合成技术在语音助手的实践,具备以下5点技术领先性:
1.语音合成训练数据的自动化筛选,无需人工标注,效果好且成本低。
2.训练音频样本少,且音频质量相对一般的情况下,确保合成质量不降低。
3.降低用户主动配合录音采集的样本数量,提升用户体验。
4.采用端云协同的训推一体化框架,可以大幅提升生成音色的效率。
5.采用大规模训练数据的端到端模型,只针对用户音色相关模块进行自适应训练,可以确保小样本下的音色相似度,同时确保合成效果的鲁棒性。
02 技术和落地实践方案
2.1 总体架构
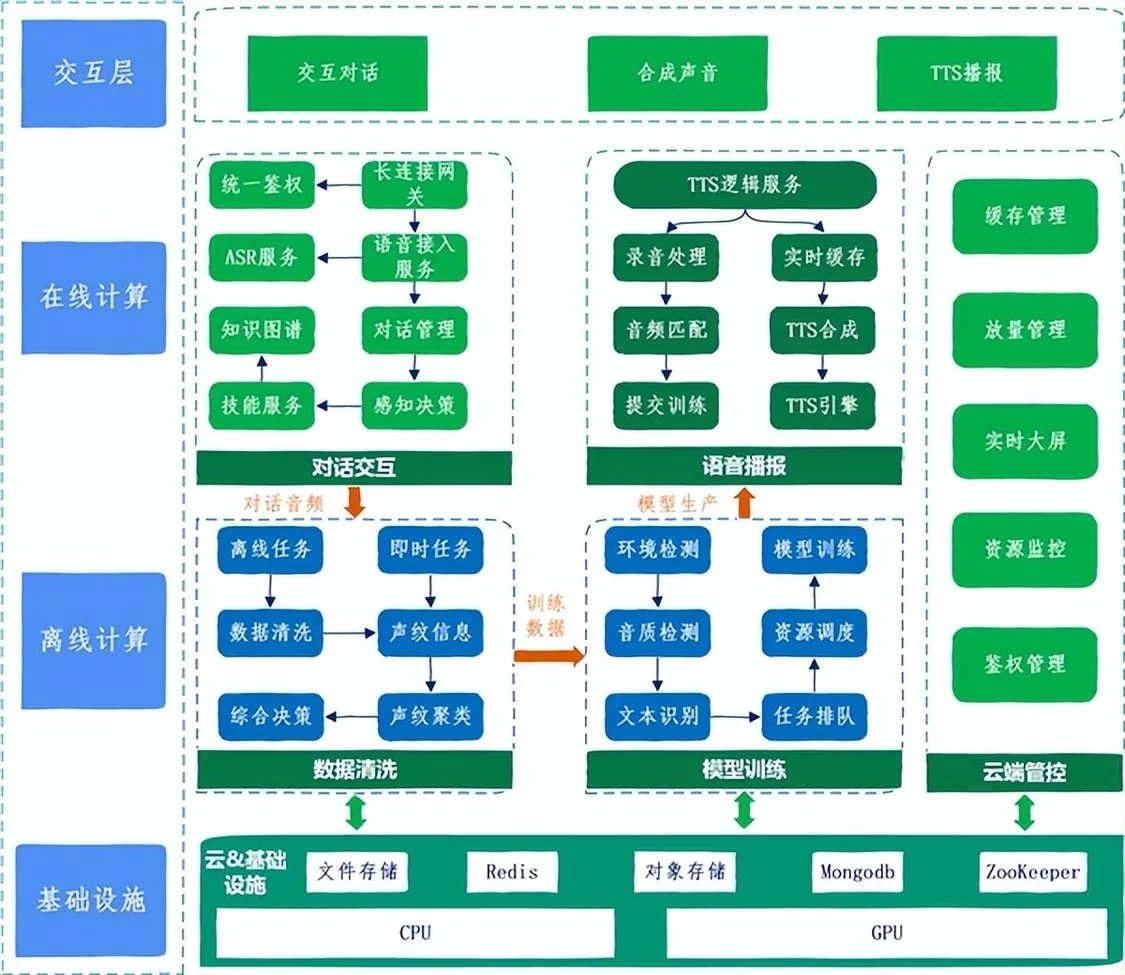
图2 整体架构图
从数据流处理的及时性角度划分,整体架构可以分为两层:在线计算和离线计算。
● 在线计算:包括语音对话交互和语音播报领域,主要是帮助用户完成语音对话,录音训练和TTS播报功能;用户在使用小布助手进行对话时,首先通过ASR服务,把用户语音转换为文本,后端的对话管理和NLU服务(自然语音理解)完成对输入文本的技能和意图识别,最终对应技能服务给到NLP结果返回给用户侧,完成一次对话交互行为;用户也可以主动在小布助手个性化声音模块录入自己的声音,并提交合成声音任务。模型训练成功后,TTS播报服务则将需要播报的文本给到TTS引擎,生成音频持续流式给到客户端进行播报。
● 离线计算:包括数据清洗和模型训练。首先基于用户大量的对话音频,采用大数据分析能力,清洗和过滤出满足条件的音频(如音频时长,文本长度,信噪比),并获取每条音频的声纹信息。然后经过声纹聚类模型,判别出该设备的主说话人,最后综合决策将主说话满足条件的多条对话音频和用户合成声音时主动录入的多条音频一起提交给模型训练。模型训练成功后,推送给在线TTS引擎服务使用。
2.2 遇到的困难和挑战
在整个创意形成到方案设计以及落地过程中,遇到不少问题和挑战。其中比较关键的问题有如下几个:
1.海量对话数据如何挑选出高质量满足条件的音频?
小布助手的用户群体大,涉及不同年龄阶层,不同地区方言,不同说话习惯及使用场景。比如孩童说话语速慢,声音小。因此,在复杂的环境和海量数据情况下,如何挑选满足条件的音频作为训练数据,是面临的第一个大挑战。
2.单设备存在多说话人情况下,如何保证挑选的训练音频都是主说话人?
通常单个手机设备是固定一个用户在使用,比较容易获取主说话人。不过我们分析发现,存在大概30%以上手机有2个及以上的使用者。极端情况下,某些设备多个用户说话的占比都相对均匀。同时在产品交互上,我们为了降低对用户体验的影响,没有增加用户繁琐的声纹注册流程。
3.在云端资源有限下,如何满足海量用户的声音合成体验?
小布助手作为首个月活破1.3亿的语音助手,用户活跃高,对新特性参与度也比较高,这必将带来大量的请求。在云端服务器资源有限情况下,既需要保证用户的声音合成需求,又要保障训练效率,降低用户的等待时长。
2.3 解决的方案
针对前文介绍题和挑战,我们通过分析交互习惯趋势,兼顾运营成本,进行全链路架构方案的设计和优化。算法同学优化性能和效果,工程同学保障系统的高可用和低成本,进而保障用户体验。
1.海量对话数据如何挑选高质量音频?
用户历史语音交互数据因为包括了大量无效数据,整体语音质量远低于用户为声音合成专门录制的语音质量。为了提高用户音色的合成效果,必须实现快速和准确地识别出无效部分,并且,整个数据挑选流程需要全自动化,无需人工干预和标注。为此,我们制定了数据筛选规则,在以下6个方面设定了阈值,从而保障挑选出来的训练音频质量。
● 音频时长:每条音频时长大于一定时长。通过设定合适的阈值,稳定时长的音频,也会降低对后续声纹模型效果的挑战。
● 文本长度:每条音频语音识别出来的文本长度,剔除文本较短的语音。单条语音文本越长,最终模型训练效果越好;通过限制文本长度,带来的另外一个好处,就是降低噪音数据。
● 语速:挑选语速适中的语音数据,正常人说话是2-3字/秒。超过或者低于这个语速的数据也进行剔除。
● 音量:每条音频计算的RMS值在[-35dB,-10dB],去掉低音量或者声音较小的数据。
● 置信度:借鉴语音识别过程对无效数据检测算法,保留识别置信度大于一定值的语音。置信度越高,语音清晰和质量越高。
● 编辑距离:经过上述条件筛选的大批量数据中,需要再次去除掉重复度高的相似语音,保留语义和文本内容有明显差异的一批数据。训练集差异性越好,语音元素越丰富,训练效果也优秀。
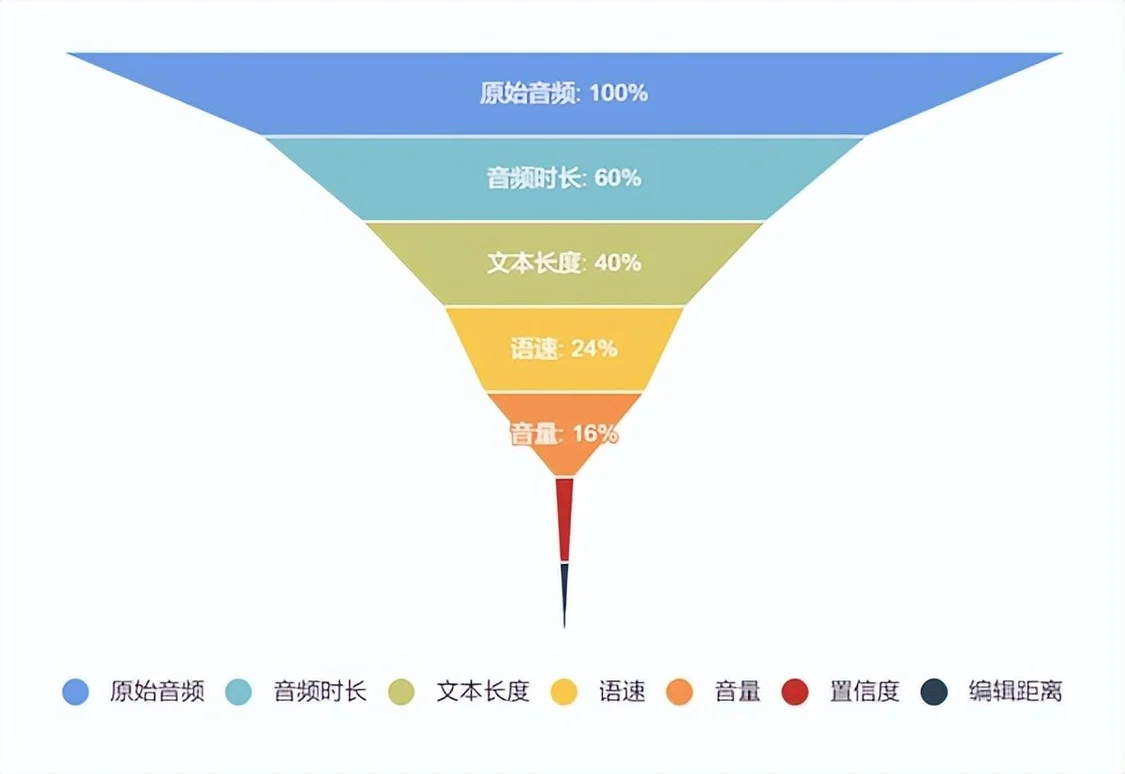
图3 声音筛选漏斗图
2.单设备存在多说话人情况下,如何保证挑选的训练音频是主说话人?
我们设计了通用的筛选和判定主说话人的流程:一、获取每条音频的声纹特征值,二、基于特征值进行声音归类,三、判定主说话人并生成语音库。
● 首先,我们通过声纹算法能力,对用户的每条音频提取声纹表征。声纹模块采用当前主流的ECAPA-TDNN声纹模型,并使用Speechbrain搭建训练系统。
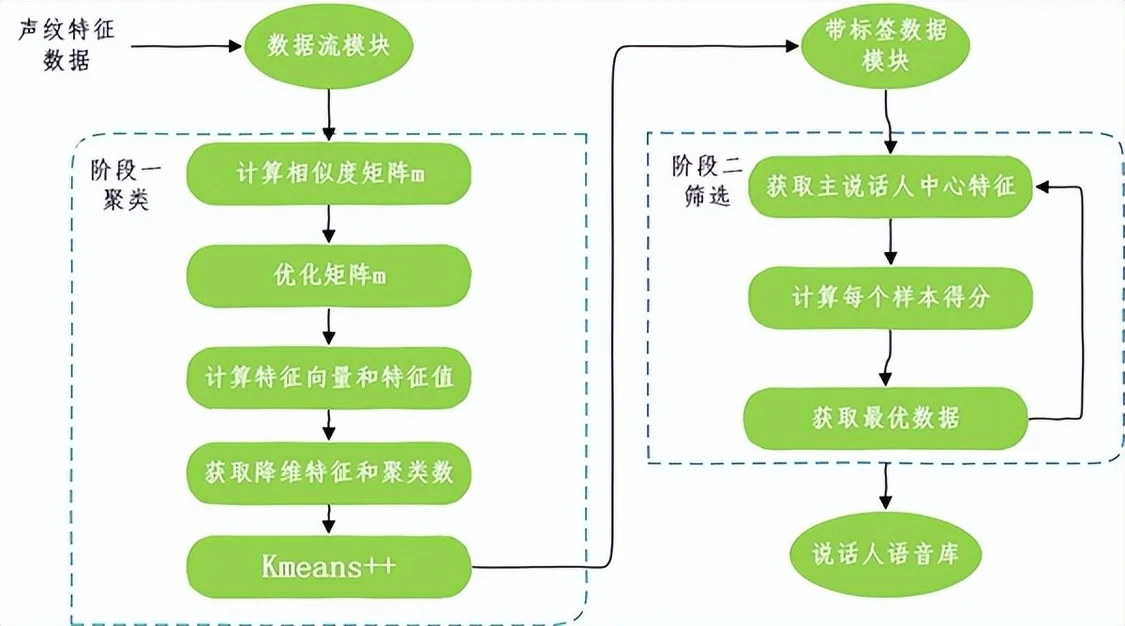
图4 说话人聚类流程
● 然后,通过聚类算法计算出单设备的说话人群。聚类算法种类繁多,比如适合较短序列的聚合式分层聚类(AHC),需要设置类别数的K-means、K-means++等;本方案采用谷歌Turn-to-Diarize系统适合中等长度序列的谱聚类算法,并且利用特征值的最大间隔法来获取准确估算说话人的数量。
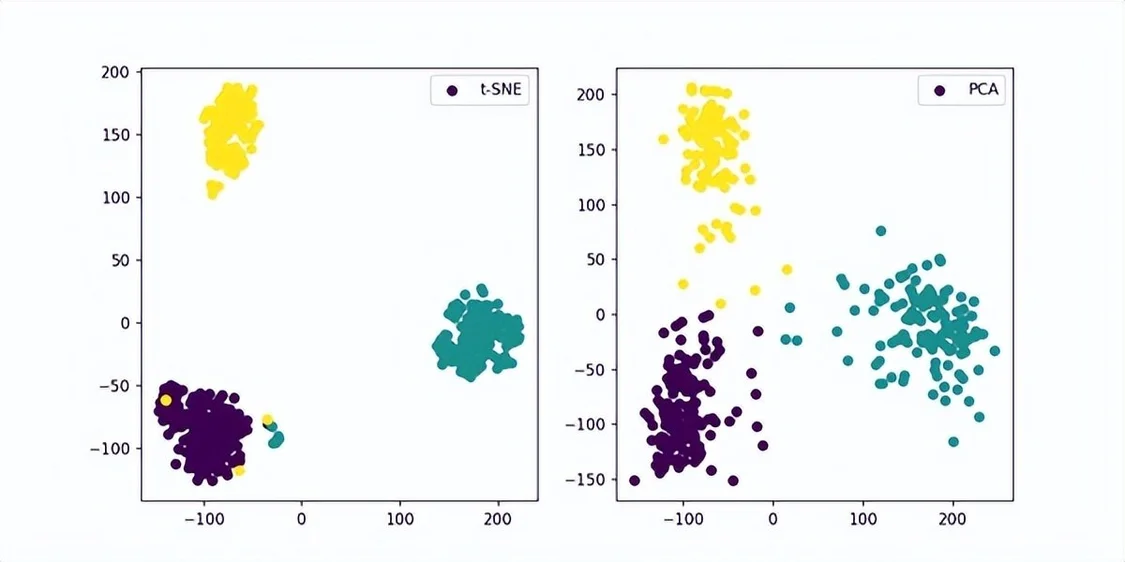
图5 聚类结果示意图
● 其次,采用谱聚类加中心得分的方式获取设备用户语音交互最频繁的人的最优的多条音频,该音频最终提供给语音合成模型训练;如果聚类结果发现多个用户使用频率差不多,我们就将最近2个月使用次数最多的用户作为主说话人,然后挑选齐满足条件的多条音频作为训练集。通过聚类算法,我们可以确保主说话人判定准确率达到95%。
● 最后,为了提升计算速度和效率,实践过程中采用相关矩阵权重本身替换拉普拉斯矩阵,并且去除掉高斯模糊等优化计算量。最终效果每次聚类200条声纹特征大约耗时700ms左右。
3.在云端资源有限下,如何满足海量用户的声音合成体验?
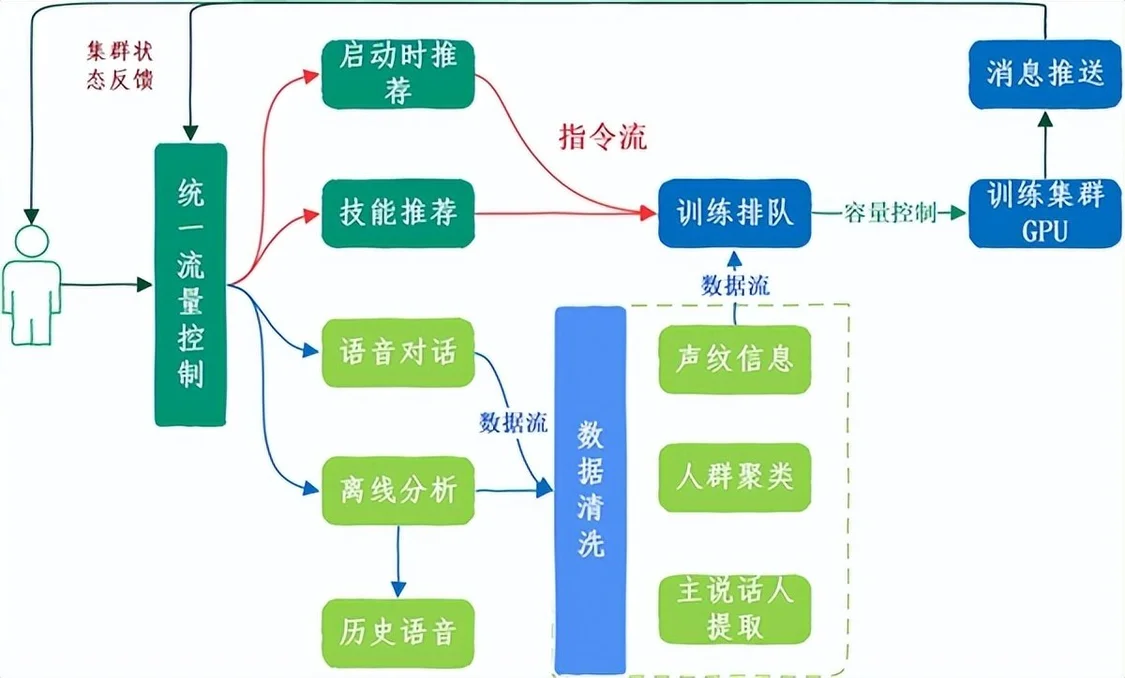
图6 音色合成全流程
● 首先,我们建设了统一的灰度服务,该服务可以动态控制所有与音色合成特性有关的入口和曝光量,也可以做到一键放量和关闭。
● 其次,我们建立排队机制和批处理的方式,对突发流量进行削峰填谷,避免对后端服务的资源挤兑。参考后端集群容量计算初始放量的用户规模,同时也构建动态反馈机制:根据后端任务排队、资源剩余等情况,及时反馈给流量控制服务进行综合决策,减少对用户曝光和引流,避免引发系统的“雪崩效应”。
对某批用户放量前,会通过离线分析任务提前对该批用户的历史语音进行数据清洗,筛选出符合条件的音频数据,做好数据准备。当该用户通过指令提交训练任务后,就会触发声音合成流程。
用户声音合成(自定义TTS2.0)包括三个阶段:预训练、在线训练、在线推理。
1.预训练阶段:主要用于产出基础模型,参数分布作为语音合成的先验分布态,降低模型朝少量样本数据域学习的难度。该阶段基于千人级、万小时级的语音数据训练出鲁棒性高的基础模型。该基础模型属于完全端到端模型,共有6个模块组成:说话人编码器、文本编码器、声学编码器、时长预测器、双向编码器、声码器。
2.在线训练阶段:固定文本编码器参数,训练其他模块,调整学习率防止过拟合及无法收敛现象。其中,音频对应的文本通过语音识别引擎识别获得,并通过语音合成前端获得对应的音素序列。
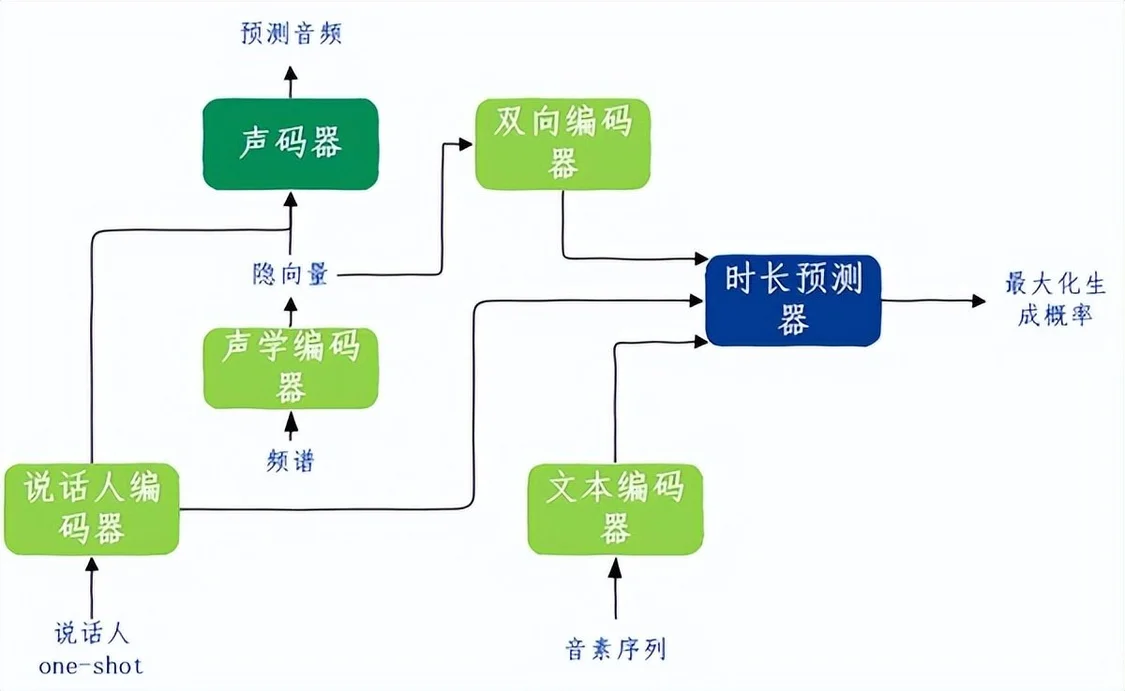
图7 自定义TTS2.0预训练和在线训练阶段
3.在线推理阶段:该阶段加载固定的文本编码器,以及在线训练阶段完成的其他模块,跟进用户输入的播报文本和特定说话人ID,输出预测音频,完成自定义TTS音频的合成。
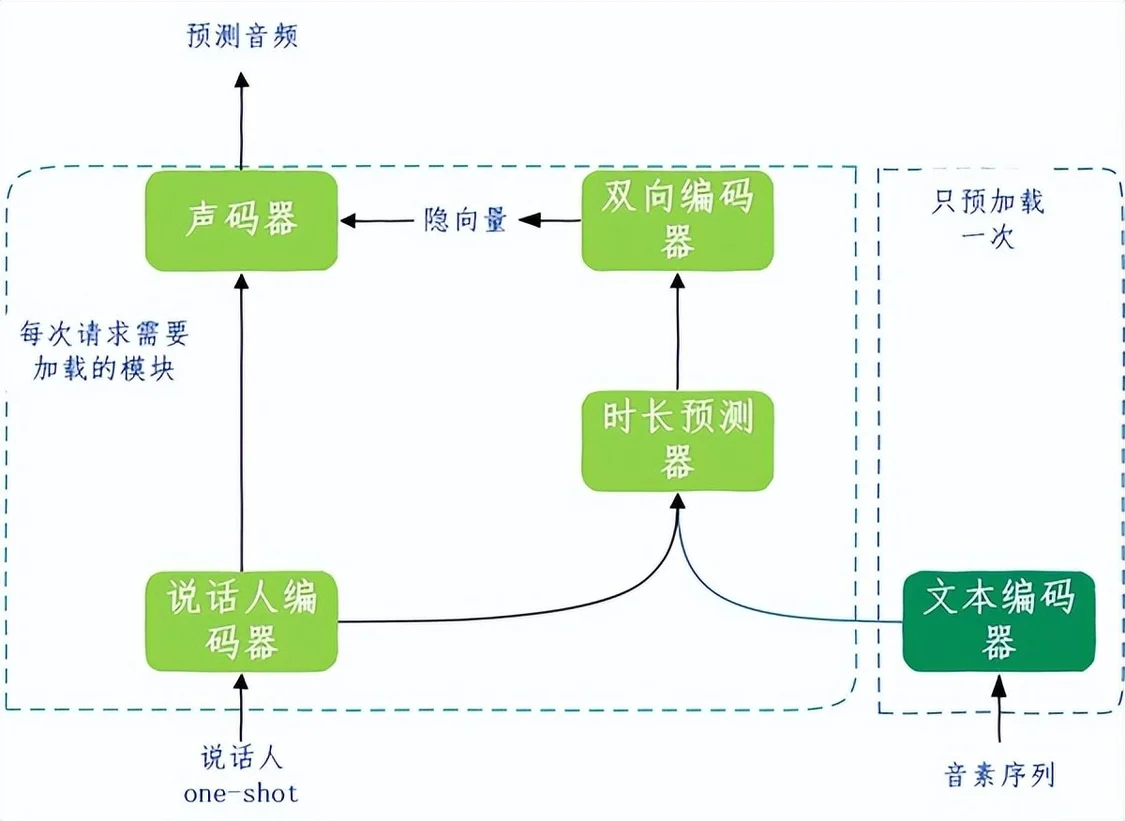
图8 自定义TTS2.0在线推理阶段
● 同时,为了降低长时间等待对用户体验的影响,我们根据单个模型训练时间以及正在排队任务数,计算预期等待时间展示给用户。并且在声音合成的训练任务完成后,会主动推送消息告知用户,提升用户的体验。
● 最后,建设了立体化监控系统,对每一条训练任务的训练时间,排队时间,训练状态进行统计和分析。可以通过实时大盘,观测到一些因为系统异常情况导致的任务耗时增加或失败,并设置告警及时通知相关方进行干预,从而保障系统的顺利运行。
03 实践效果/价值
我们对这两个方案(自定义TTS1.0方案和基于交互音频的自定义TTS2.0方案)进行了MOS效果评测,结果表明方案1.0和方案2.0合成的声音差异较小,评测数据如下。

我们在优化了TTS合成效率及音色丰富度上,没有太降低音色的合成效果,依旧可以提供相对自定义TTS1.0方案效果一致的音色,具有较强的提效降本的价值。
04 总结与展望
本文系统性介绍了OPPO小布助手在用户自定义TTS和提高用户播报体验方面做的一些工作。主要围绕语音清洗,主说话人聚类,小样本TTS合成技术进行了介绍,在工程实践上,着重介绍了云端资源有限情况下的一些降本增效的设计方法和理念。
通过数据分析,存在多个角色使用同一台设备交互的情况,例如:母子共用手机等。我们介绍了,单设备存在多说话人情况下,采用数据清洗和声纹聚类的方法,挑选出了主说话人的训练音频,但针这种多角色情况,如何确保同时输出高纯度的多说话人训练样本,是未来重点探索的方向。
自定义TTS未来方向是0句话合成(Zero Shot TTS),即不需要用户专门录制声音,仅依赖用户历史语音交互数据,即可实现高自然度、高相似度的语音合成效果。该技术属于低资源合成范畴,因此我们将重点增强语音数据自动过滤功能,增强高质量数据的利用率,降低低质量数据的利用率,并将用户发音评测信息、声纹信息用于语音合成联合建模,以此提升低资源语音合成效果。
05 团队介绍
OPPO小布助手团队:以小布助手为AI技术落地的关键载体,致力于提供多场景、智慧有度的用户体验。小布助手是OPPO智能手机和IoT设备上内置的智能助手。作为多终端、多模态、对话式的智能助手,小布助手的技术覆盖语音识别、语义理解、对话生成、知识问答系统、开放域聊天、推荐算法、数字人、多模态等多个核心领域,为用户提供更友好自然的人机交互体验。小布助手的技术实力在技术创新及应用上始终保持领先,当前已在多个自然语言处理、语音识别相关的行业权威赛事及榜单中获得亮眼成绩。
OPPO分贝实验室:负责语音合成技术的突破领先,并在手机应用和各种AIoT场景的全面落地。语音合成技术属于AI原子能力,是人机交互的重要一环。成立四年来,我们的合成技术赋能OPPO软硬服各业务线,满足用户在多种场景下的播报需求。除了通用合成提供30余款音色之外,我们还提供多情感合成、多风格合成、多语种合成、小样本合成、离线合成、语音变声等能力,覆盖了OPPO绝大多数设备(手机、手表、电视)。2020年,Blizzard Challenge国际评测中,我们获得自然度第一、相似度第二的成绩。2021年,我们的语音合成基础能力获得信通院颁发的可信AI证书。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
