
目前 SOTA 的神经表示的实现是基于可训练的特征网格获得的,特征网格本身承担了学习任务的一部分,因而允许后续更小的,更有效的神经网络结构。然而这样的特征网格结构+全连接层结构与单独的全连接层结构相比会带来巨大的记忆开销,以及更长的训练时间。本文通过一种通用的新输入编码来降低这一成本:即引入由可训练特征向量构成的多分辨率散列表,通过学习使得有效特征占据哈希表,减小数个量级的带宽的浪费和计算资源的花费。
来源:SIGGRAPH 2022
作者:THOMAS MÜLLER, ALEX EVANS, CHRISTOPH SCHIED, ALEXANDER KELLER
原文链接:https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
项目链接:https://github.com/NVlabs/instant-ngp
整理人:何冰
隐式神经表达简介
计算机图形基本上由参数化外观的数学函数表示。数学表示法的质量和性能特性对视觉保真度至关重要。我们希望表示法能够保持快速和紧凑,同时捕获高频、局部细节。由多层感知器 (MLPs) 表示的函数,作为神经图形原语,已被证明符合这些标准。
而这些方法的重要共同点是将神经网络输入映射到高维空间的编码,这是从紧凑模型中提取高近似质量的关键。在这些编码中,最成功的是可训练的、特定于任务的数据结构,他们承担了很大一部分的学习任务。这使得可以使用更小、更高效的 MLP 成为可能。然而,这种数据结构依赖于启发式和结构修改(如剪枝、分裂或合并),这可能会使训练过程复杂化,将方法限制在特定的任务中,并使得该方法在 GPU 上的性能表现不佳。
本文 [1] 通过使用多分辨率散列编码来解决这些问题,该编码方法是自适应的,高效的,独立于任务的。它仅由两个值配置——参数的数量 T 和所需的最佳分辨率 Nmax ——经过几秒钟的训练,在各种任务上产生最先进的质量。
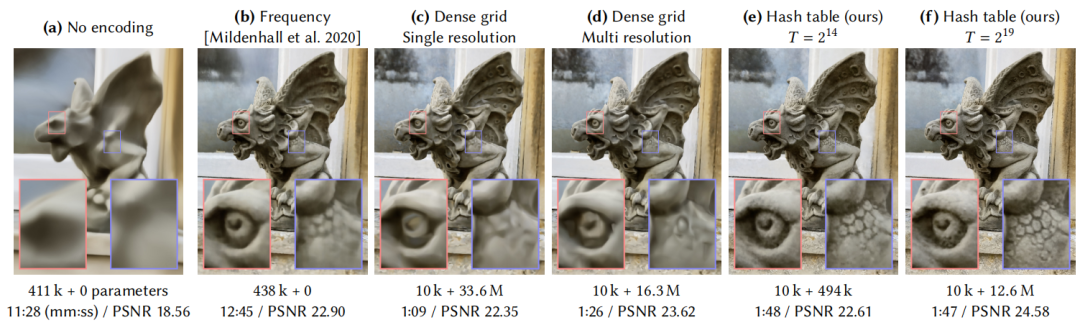
图 1 对比了多种主流的编码方法:
- 不使用任何编码将位置信息直接输入 MLP 结构中 (a) 难以拟合图像中的高频信息。
- 对位置信息使用频率编码 (b) 可以在一定程度上拟合图像中的高频信息,其模型大小与 (a) 相似。
- 密集特征网格编码中的特征可以理解为对其局部空间的一个整体描述,使用密集特征网格编码 (c) 可以显著减少训练时间,并减小MLP层的大小,但密集特征网格的大小过大 (33.6Mb)。
- 使用多尺度网格编码 (d) 可以压缩近一半的的特征网格大小,并进一步提高复原图像的 PSNR。
- 本文中提出的方法 (e) 其实是基于 (d) 的优化,在几乎不损伤图像复原质量的前提下,可将特征网格的大小压缩至原来的 1/30。
- 调整本文方法中的超参数,可以在压缩率和模型大小之间做权衡。
InstantNGP 与多分辨率哈希编码流程与原理
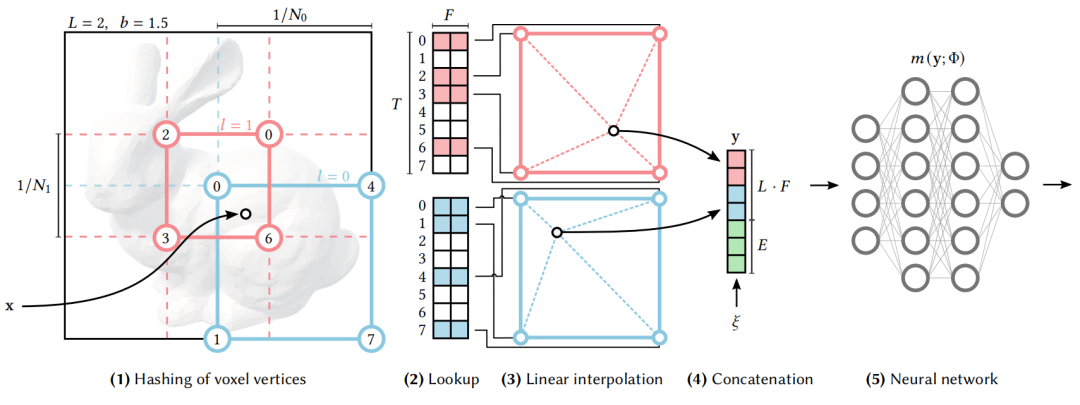
不妨以 2D 图像为例:
- 给定输入的坐标x,在不同尺度下选取该坐标周围 4 个特征点(特征点等间距地分布在图像上,不同尺度的特征点间间距不同);
- 通过哈希码表进行索引,在不同尺度的码表下获得该尺度的对应的4个特征点;
- 通过2维的线性插值获得该坐标的特征向量;
- 并将所有尺度下的特征向量与补充输入(如视角方向或纹理)拼接;
- 输入 MLP 网络中。
其中步骤一继承了多尺度特征网格编码 [2] 的工作,在此不再赘述。在图像中提取的特征网络存在一定的问题,即需要很密集的特征网格才能使恢复的图片达到高的质量,并且由于自然图片中存在大量的平坦区域,在图像复原时也是少数的特征向量起绝大多数的作用,因此单独存储每个特征的效率很低。
空间哈希函数 [3] 如下所示:

哈希表的作用是使原本空间中邻近的特征在特征表中随机分布,使得哈希碰撞的概率逼近理论值。
粗分辨率下的特征点总数少,少于设定的最大码表长度 T 时,映射是一一对应的映射;粗分辨率下的特征点总数多于 T 时,则会产生多对一的映射,即哈希碰撞。
但如前文所说,在图像复原过程中,少数的特征向量起绝大多数的作用。因此哈希码表中两个重要特征向量碰撞的概率很低,往往是一个相对重要向量和数个不重要向量处于码表的同一位置。在训练过程中,哈希码表将会逐渐留下更重要的特征向量。
码表长度远小于原来的密集网格的特征向量个数即是本文方法能够有效压缩特征的关键。
实验
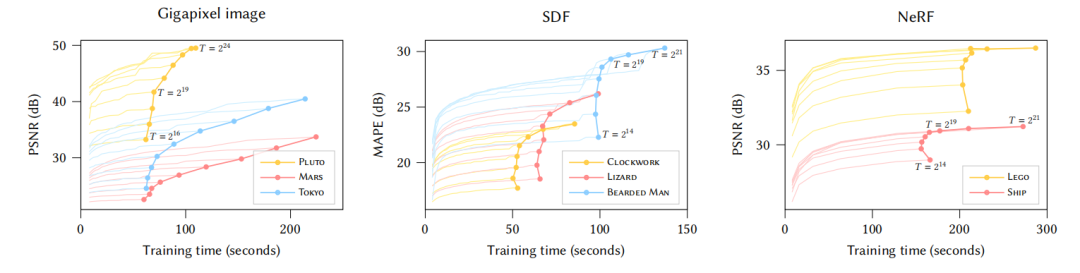
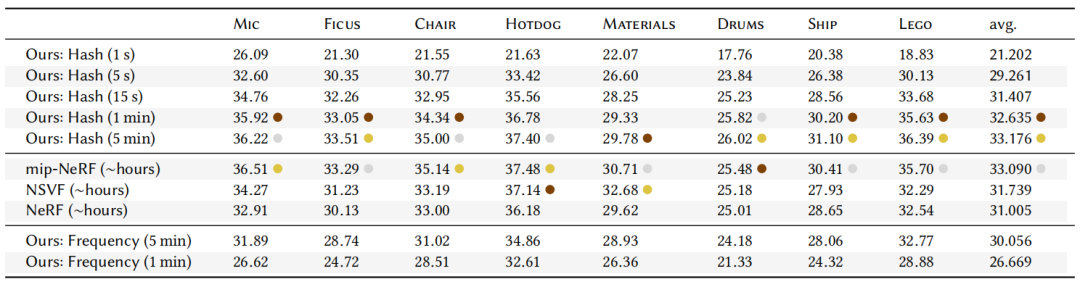
如图 3 所示,浅色线为不同数据集,不同超参数 T 时的训练过程,在训练开始的数秒内,模型就能达到较高的 PSNR ,收敛前的 PSNR 跳跃上升是由于学习率的下降;深色线上的点则为模型收敛对应的 PSNR 和最终训练时间。由于作者在实验中使用的是 RTX 3090 GPU ,在 T > 219 时, GPU的快速缓冲区 (cache) 超负载 ,训练收敛时间显著上升。
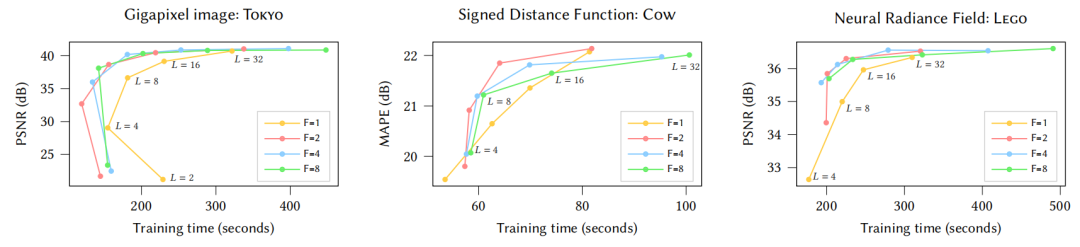
作者尝试了不同的超参数,发现在不同数据集下, F=2,L=16 总是拥有最佳性能和质量(曲线位于左上方),因此这组超参数被固定下来,应用于本文的所有其它实验。
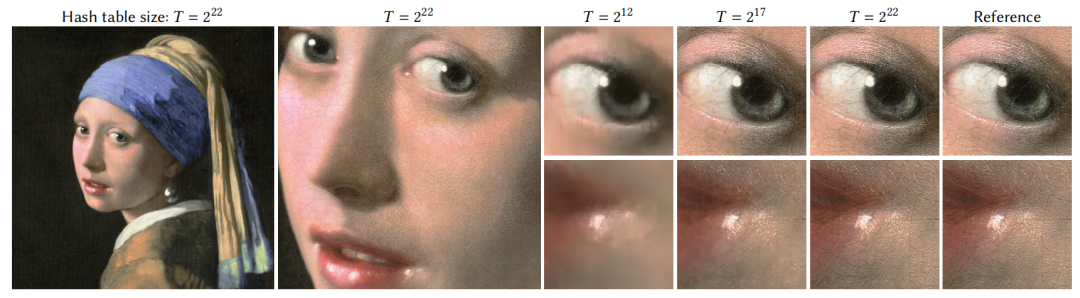
从低分辨到高分辨,模型大小依次为 117k,2.7M,47.5M ,最后一个模型的 PSNR 为 29.8dB。
引用
[1] Müller, Thomas, Alex Evans, Christoph Schied, and Alexander Keller. “Instant Neural Graphics Primitives with a Multiresolution Hash Encoding.” ACM Transactions on Graphics 41.4 (2022): 1-15. Web.
[2] Julian Chibane, Thiemo Alldieck, and Gerard Pons-Moll. 2020. Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE.
[3] Matthias Teschner, Bruno Heidelberger, Matthias Müller, Danat Pomeranets, and Markus Gross. 2003. Optimized Spatial Hashing for Collision Detection of Deformable Objects. In Proceedings of VMV’03, Munich, Germany. 47–54.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。
